
When Arm began its pursuit of the datacenter a decade ago, the idea behind offering a low-power architecture as an alternative to Intel and is Xeon product line made sense. Density in traditional enterprise datacenters was growing and the cost of cooling these smaller, more powerful servers was at times exceeding the actual acquisition price. Cloud providers were rapidly building out their massive datacenters and cost again was a factor. Arm saw the challenges created by density and heat and thought that its architecture – which was powering most of the smartphones, tablets, and similarly mobile devices as well as some embedded controllers – could alleviate a lot of these headaches.
There were some successes over the years, with a range of chip makers embracing Arm’s datacenter system-on-a-chip (SoC) designs. Cavium made some inroads with its Arm-based ThunderX chips, a portfolio that continues to evolve with Marvell, which bought Cavium for more than $6 billion in 2018. Applied Micro pushed its X-Gene chips, which later formed the basis for Ampere’s current technology. More recently, dominant public cloud services provider Amazon Web Services (AWS) uses Arm designs for its Graviton processors and the Fujitsu-built Fugaku supercomputer in Japan – currently at number one on the Top500 list – is powered by Arm-based processors.
There also were some misses – early pioneer Calxeda shut its doors, AMD and Qualcomm backed away, and Samsung flirted with the idea of Arm chips but never really pursued it.
Arm also learned the lesson that AMD had to in the first decade of the century with its Opteron lineup, that despite the need for efficiency and to rein in costs, power was not as important as performance when it came to enterprise applications. There were heavy-duty workloads to be run and, sure, they had to run most efficiently, but organizations wanted the software to run well and would worry about dealing with heat, cooling and power consumption along the way.
“When Arm started its journey into the datacenter, we led with a power-performance message, and quite honestly, it was not a message that resonated,” Chris Bergey, senior vice president and general manager of Arm’s infrastructure line of business for almost a year, said during a recent conference call with journalists. “These servers were not battery-powered; we had a performance gap to close. Now that we’ve more than closed the performance gap, ironically the power-performance message is coming around full circle to be front and center.”
Arm looked to address this trend two years ago when it rolled out its Neoverse platform, designed to create an architecture that can address the demands of datacenters, the cloud and the fast-growing edge and the broad range of devices that reside in each. The initial “Ares” N1 platform unveiled in early 2018 and was aimed at scale-out compute environments, datacenters 5G and the edge. A week later the company ran out the Neoverse “Helios” E1 processor designed more for edge systems.
A cornerstone of the Neoverse platform was the promise that it would deliver 30 percent year-over-year performance improvement with each iteration. The company this week introduced those iterations – the “Perseus” N2, a follow-on to the N1 chips and the “Zeus” V1 platform, the first in the V-series of processors for workloads that need CPU performance and bandwidth, such as machine learning, HPC and the cloud. Both exceed the 30 percent performance increase promise. According to Bergey – who came to Arm after years with companies like Western Digital and Broadcom – the N2 delivers up to a 40 percent single-threaded performance gain over the N1; the V1 a 50 percent gain. Their place in the larger Neoverse roadmap can be seen below:
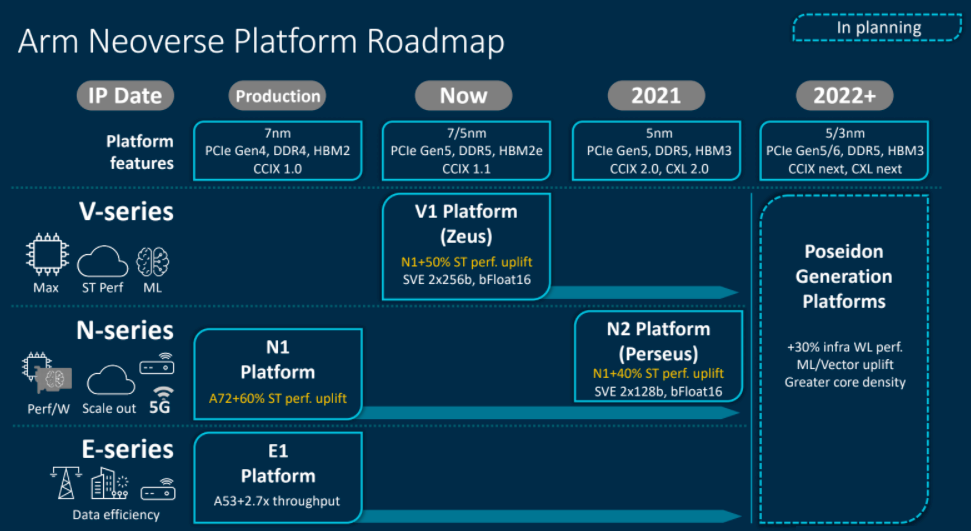
The emergence of the N2 and V1 processors comes as Arm begins the process of being bought by Nvidia in a $40 billon deal that will bring a CPU business in alongside Nvidia’s GPU portfolio and give it even more capabilities in such key spaces as artificial intelligence (AI), HPC and the cloud, areas that the Neoverse platform also targets. We’ve done both a deep look at such a deal when it was only a rumor and another look at it this month when Nvidia officially made the deal official. Nvidia is buying Arm from Japanese tech giant SoftBank Group, which will use some of those billions to alleviate its own financial pressures.
Arm was short on deep details about the N2 and V1 this week, though Bergey promised more information at the upcoming virtual Arm DevSummit (nee TechCon) starting Oct. 6. What we know about the N2 is that it’s designed to do more in terms of performance in the same footprint – in power and area – as the N1. It’s due out next year and will come with 128 cores. The plan is to be offering N2 licenses by the end of this year. Bergey said companies already are working with the N2 beta.
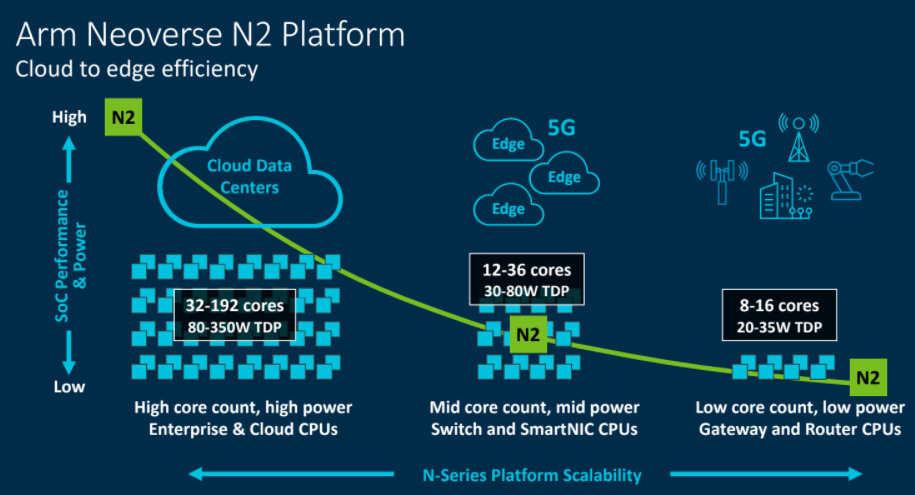
V1 is out now, the first in the V-series that is optimized for performance. The expansion of the N-series platform and the introduction of the V-series gives Arm a broader portfolio that covers a wider breadth of workloads and compute environments, from the datacenter out to the edge.
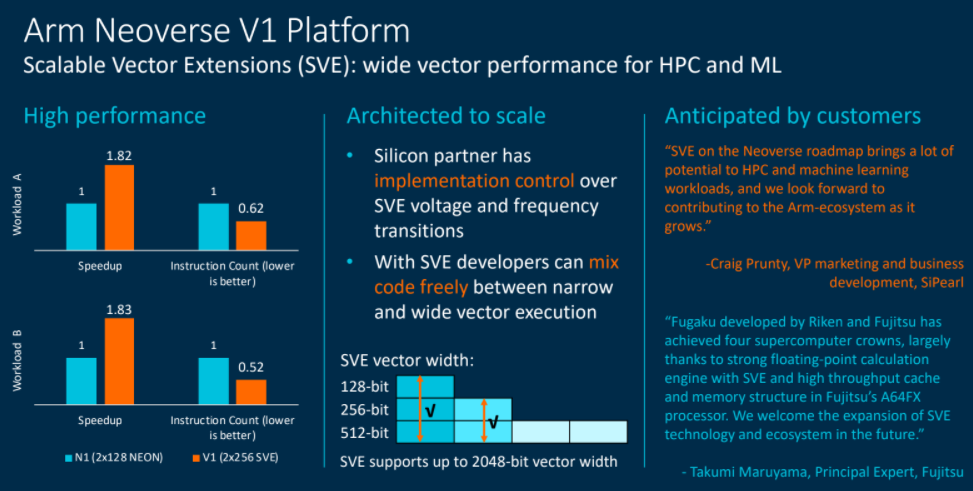
Both the N2 and V1 will support Scalable Vector Extensions (SVE), and important factor in compute environments that demand greater scalability. The A64FX chip from Fujitsu that powers the Fugaku supercomputer also supports. SVE. N2 will come with a two 128-bit pipelines; V1 with two 256-bit pipelines.
“For HPC and ML [machine learning] workloads, wider vectors can offer more application performance,” Bergey said. “At the silicon level, our partners have full control over the SVE voltage and frequency transitions, so there doesn’t have to be a frequency drop. Fujtsu’s A64FX is a great example of it. They can run full frequency all day long while executing SVE code. For developers the key benefit is that SVEs are architectured to transition seamlessly between register widths, so they can incorporate new, wider-width SVE instruction but reuse helper functions that they may have already rewritten for smaller registers. Finally, our partners are really looking forward to really unleashing the performance and ease of use of SVE in their won uses cases.”
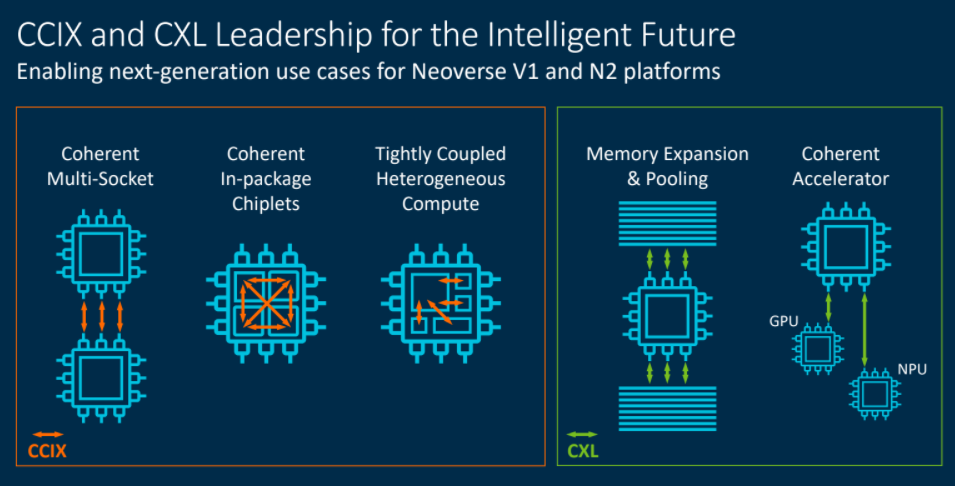
In addition, the Neoverse platforms will support CCIX and CXL chip-level interfaces to more efficiently enable manufacturers to embrace new technology quickly. The CCIX protocol delivers bidirectional coherent communications and flexibility in how it can be used. Multi-socket computing is a well-known use case for CCIX, with trends like heterogenous computing using accelerators also driving interest. There also are emerging use cases, such as chiplets. CXL can be deployed for memory pooling and expansion, such as sharing a large pool of memory across connected nodes or attaching a large pool of memory to a single node, Bergey said.
“CXL is proving to be the preferred way to attach accelerators where accelerators and the host can coherently access each other’s memory,” he said. “The most obvious use cases are for ML training and inference, but we expect new use cases to emerge by the time this hits the market.”
Arm expects the expansion of Neoverse will accelerate what Bergey called strong adoption. AWS’ Graviton2 is based on the N1 platform and he noted that operating systems, hypervisors like Xen and KVM, and emerging software like Docker containers and Kubernetes all will support Arm. Ampere also is expected to release a 128-core Neoverse-based chip by the end of the year, he said.
“The emergence of Arm in the datacenter is being driven by many factors: customization, efficiency [and] ecosystem diversity, but all of that builds on top of performance,” Bergey said. “If Neoverse wasn’t delivering a significant, measurable value proposition, you would not see the market adoption and momentum that we are achieving.”
How that momentum translates into market share against Intel and a rejuvenated AMD is unclear, but Arm has a better chance know to chip away at Intel’s dominance after abandoning its low-power pitch and focusing more on performance.

Supermicro At 30: From Designing AI Chips To Selling AI Systems
There is something about late September. Nvidia was founded 30 years ago on Tuesday this week, Google was founded 25 years ago on Wednesday, and Supermicro was founded 30 years ago today. Three decades ago, Supermicro and its sister company, Ablecom, were both family affairs, as sometimes happens with startups. …

Mixed Results For The Datacenter Thundering Thirteen In Q4
We have been tracking the financial results for the big players in the datacenter that are public companies for three and a half decades, but starting last year we started dicing and slicing the numbers for the largest IT suppliers for stuff that goes into datacenters so we can give …
Will AMD Get Back Into Arm Server Chips?
There was a bit of a kerfuffle this week when it looked like AMD was changing its position a little bit on whether or not it would get back into designing and selling server chips based on the Arm architecture. The funny thing is that the world has changed around …
Be the first to comment