

It is pretty clear at this point that there is going to be a global recession thanks to the coronavirus outbreak. Maybe it will be a V-shaped recession that falls fast and recovers almost as fast, and maybe it will be a sharp drop and a much more prolonged climb back to normalcy. As we have pointed out before, we think that IT technology transitions are accelerated by such trying times, and this could happen starting soon. There is no doubt that companies are going to be even more aggressive in measuring the performance per dollar and performance per watt on every piece of hardware that will still need to go into datacenters in the coming days, weeks, and months.
As far as servers go, AMD, with its Epyc processors, is going to perhaps be the biggest beneficiary because it is the easiest drop-in replacement for the much more expensive Xeon SP processors from Intel. And while the Arm server chip upstarts, Ampere Computing and Marvell, were not planning for a global pandemic when they timed the launches of their chips on their roadmaps, they may be among the beneficiaries of the budget tightening that will no doubt start at most companies – if it hasn’t already. They would do well to get their chip samples ramped and products into the field as soon as possible.
We have reviewed the upcoming “Quicksilver” Altra processor from Ampere Computing and its future roadmap two weeks ago and also reviewed the upcoming “Triton” ThunderX3 processor from Marvell and its future roadmap this week. And now we are going to go through the performance and price/performance competitive analysis that these two chip makers have done as they talk about their impending server chips.
We realize fully that any vendor claims about performance have to be taken with a grain of salt – sometimes a whole shaker – but we also know that server buyers need to have at least a baseline idea of the performance of processors before they can even figure out what processors to test for their workloads. You have to start somewhere to get evaluation machines to run actual performance benchmarks on real workloads. No one is suggesting that anyone buy machines based on vendor competitor analysis, which would be utterly stupid. Our philosophy is to present as much information as possible and then provide some informed commentary about how to think about making comparisons across suppliers and architectures. Comparisons may be odious, but that doesn’t mean that they do not have to be made. Particularly in a recessionary climate like the one that we are very likely entering.
A few things before we begin. We noticed a certain amount of chatter out there after we published some feeds and speeds on the ThunderX3 chip and claims of the performance per core that Marvell thinks it will get with the Triton chip compared to the future “Ice Lake” Xeon SP chip due later this year. Marvell did its comparisons using the open source GNU Compiler Collection (GCC) compilers on both its own gear and that of Intel, and there was a certain amount of whinging about not using the Intel C++ Compiler (ICC). As we said in the article, this is a baseline performance run with standard flags, and we think it is not only absolutely valuable to have this consistent compiler substrate running across generations and architectures, we also think people have a very good sense that for a lot of workloads, the ICC compiler delivers somewhere around 20 percent more performance on a wide range of workloads. Unfortunately, a lot of them are microbenchmarks that have had their compilers tweaked to run things like the SPEC tests and others at peak efficiency and that may not be reflective of the baseline performance that a lot of actual applications will see. So, our attitude is that all CPUs should run the standard tests on GCC since it is supported equally well (or poorly depending on how you want to look at it) on all CPUs, and then each vendor should trot out their optimized compilers to show the uplift they get on these microbenchmarks and other systems level software such as databases and then the actual workloads should be tested. In this way, you can see the full spectrum of platforms and tunings and how it might be correlated in the past and in the future with actual applications.
This kind of basic information that the chip makers present is just the beginning of a long process. But it is also the ante to even be part of a CPU buying decision. So is price, and we can’t really do a full analysis of Arm server chips compared to X86 until the products actually roll out and we see the prices, too. (Ampere Computing and Marvell are giving some hints on price/performance, which we can work backwards to get an initial price for at least a few SKU in their respective lineups. This gets us started on the process of thinking about how these different chips might stack up to each other.
Let’s start with Ampere Computing and how it thinks its first generation Altra chip will do against the competition in the datacenter, beginning with SPECrate 2017 Integer tests:

The Ampere Altra chip tested is presumably the 80-core version; it’s not clear. What we do know is that the system under test had two Altra processors running at 3.3 GHz turbo boost speed and that they were running the SPEC integer test with the GCC 8.2 compilers with the Ofast, LTO, and jemalloc options turned on. To get the number for the AMD “Rome” Epyc 7742, which has 64 cores running at 2.25 GHz, the figures for the Dell PowerEdge R6525 server tested last November (the best Dell system result with that processor) was used; that system had a base rate of 667 using the AOCC compiler. Ampere Computing then normalized this to GCC by multiplying by 83.5 percent, which it reckons is the ratio between AOCC 2.0 with the base options and GCC with the above-mentioned options. So that gives that two-socket machine an estimated rating of 557 and therefore each Epyc 7742 processor a rating of 278.5. Working backwards from this chart, then the Ampere processor with 80 cores has about 4 percent more integer oomph, or about 289.6. To get a number of the Intel Xeon SP, Ampere Computing chose the Dell PowerEdge R740xd that was tested back in March 2019 using a pair of 28-core “Cascade Lake” Xeon SP 8280 Platinum chips, which run at 2.7 GHz. This machine had a base SPEC integer rating of 342, which after a conversion to estimated GCC results by multiplying by 76 percent yields 260 and that works out to 130. By the way, Intel yields 4.64 per core at the GCC level, and AMD yields 4.35 per core compared to 3.62 per core for Ampere Computing.
What is annoying about what Ampere Computing has done in the following charts is that it is comparing different AMD Epycs and different Intel Xeon SPs with its Altra, and in some cases – as with the cost per total cost of ownership of a rack-scale cluster of servers – it is using a lower-bin Altra part in that comparison. We will normalize this as much as possible in a table that appears below, but let’s go over that Ampere Computing said before that.
The first thing we figured out is that it looks like the top-bin Altra part will burn 205 watts, not 200 watts flat, because that is the only way the numbers that are shown in the chart below work out:
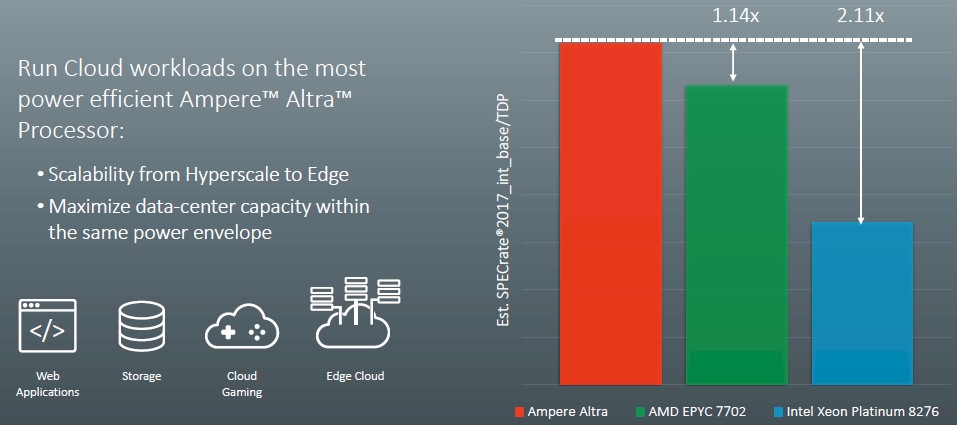
Assuming that it is keeping the 80-core part in the comparison but using a slower 180 watt part, which is mentioned in the notes on these charts, you will note that it has shifted to the AMD Epyc 7702 for the comparison above, which has 64 cores running at 11 percent lower clock speed and which also, at 200 watts, burns 11 percent less juice than the 225 watt Epyc 7742 shown in the first chart. The SPEC integer test for that machine, a Dell PowerEdge R6525, is here. Similarly, the Intel chip compared here is the Xeon SP 8276, which has 28 cores running at 2.2 GHz (down 18.5 percent from the Xeon SP 8280) and which costs $8,719 (down 12.9 percent from the $10,009 price of the Xeon SP 8280). The SPEC integer benchmark result is here for a Dell PowerEdge MX740c based on a pair of these CPUs.
This chart talks about watts per core comparisons of the same processors:
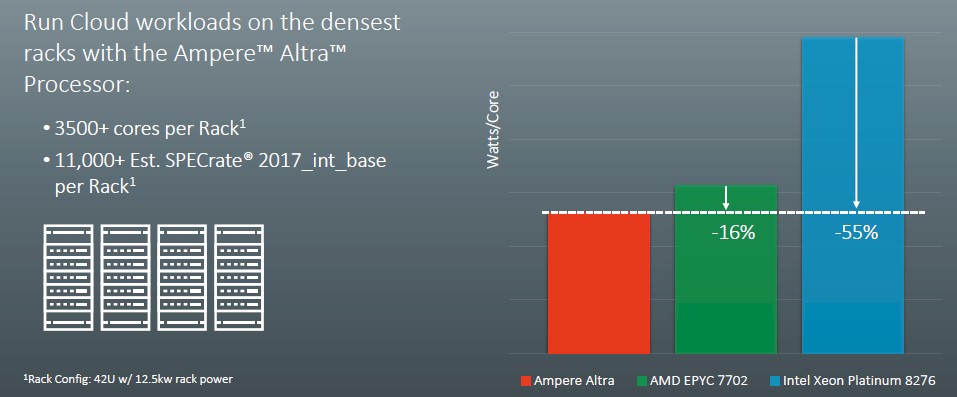
The cores are less oomphie in the Ampere Altra chips than in the Epyc or Xeon SP processors, so it is no surprise that the watts per core is lower.
Based on all of these different SKUs and data points, here is a summary table that adds it all together, including the GCC performance estimates:
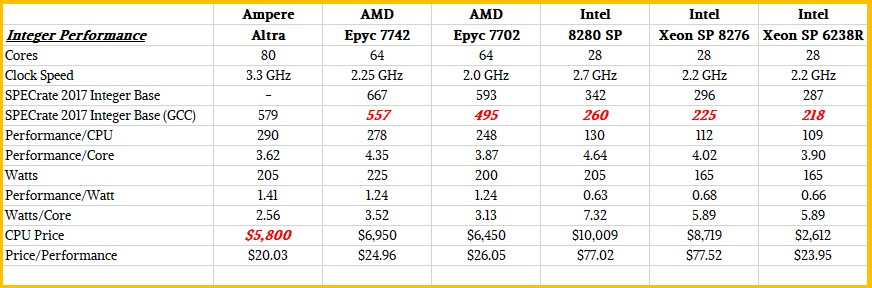
Based on the idea that Ampere Computing has to offer at least a 20 percent price/performance advantage at the chip level compared to the best that Intel and AMD can throw at the cost per performance per watt equation that dominates the buying decisions of the hyperscalers and cloud builders that Ampere Computing is targeting. We also ginned up what the 180 watt Altra part might look like based on some very serious guessing. The pricing on such a chip, we think, would be even more aggressive and go after the belly of the Xeon SP market: Those aptly named Gold processors, like the new Xeon SP 6238R.
That brings us to the last chart in the deck from Ampere Computing, which shows the performance per total cost of ownership deltas between the four chips shown below:
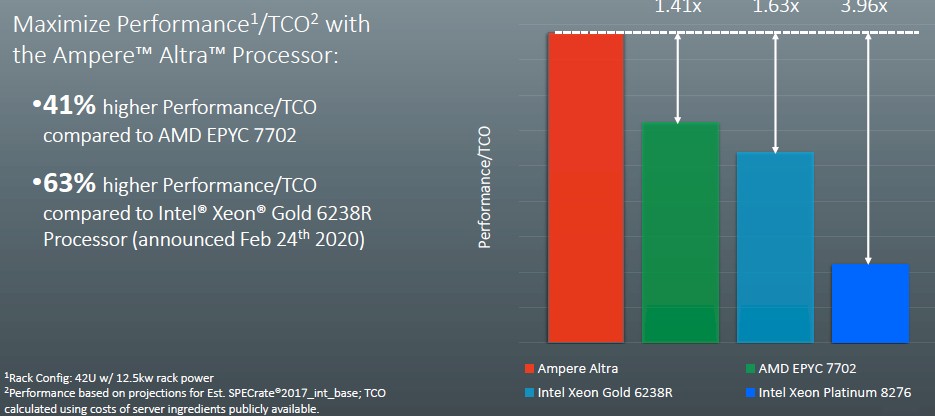
This is a system level comparison and the rack of servers using the Altra processors are using a pair of those 180 watt parts (which we estimated some feeds and speeds for) plus sixteen 16 GB memory sticks (256 GB of memory), a pair of Ethernet NICs, a 1 TB SATA drive, and base components like baseboard management controllers, power supplies, and such. The AMD Epyc 7702 server has a similar configuration, and the two Intel machines assume twelve memory sticks because they only have six memory controllers per socket. Ampere Computing has created a TCO tool that does all of this math, presumably with a lot of servers and different CPU SKUs.
What this chart says is that basically for every dollar that you spend on a rack of servers using a pair of Xeon SP 8276 processors, you will get nearly four times as performance using a rack of the 180 watt Altra processors, and the multiples are 1.63X compared to a rack of systems based on the much more reasonably priced Xeon SP 6238R processors and 1.41X that of a rack of systems based on the aggressively priced AMD Epyc 7702 processors. It is not really possible to easily guess what these system comparisons might be that Ampere Computing had in its TCO tool, but we look forward to playing with that TCO tool when it becomes available.
Where There Is Thunder, Lightning Has Struck
Marvell, as we said, is providing some performance data as well, although it is of a different type but is consistent with the kinds of data that Cavium has provided in the past as it launched the ThunderX1 and ThunderX2 processors.
The first thing that Marvell wants everyone to ponder is just how many virtual machines each one of its processors can host. At 96 cores for the top-bin Triton ThunderX3 part and four threads per core, that is 384 threads that can each, in theory, support a virtual machine. And even if the threads are ignored and a virtual machine is allocated to a core, AMD Epycs top out at 64 cores, or a 50 percent advantage to Marvell, and Intel really – for all practical purposes – tops out at 28 cores or a 3.4X advantage. If you want to do threads for each VM, then the advantage to Marvell over Intel is 6.85X and over AMD is 3X.
Here is another interesting chart from Marvell that talks about the effect of simultaneous multithreading (SMT) on various workloads. Take a gander:
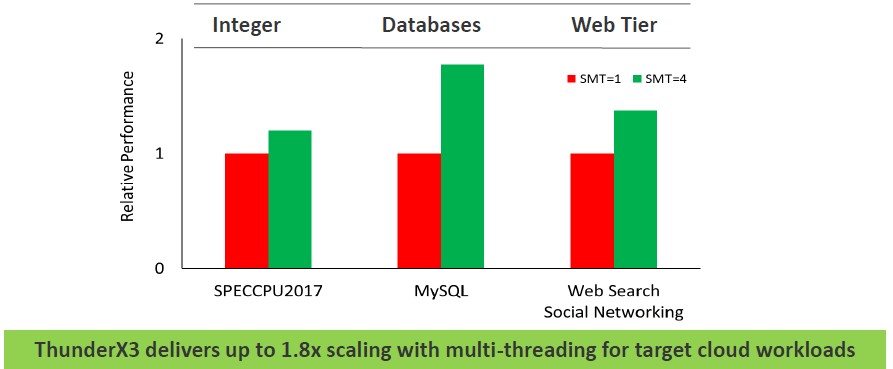
Now let’s get down to the X86 comparisons. In its tests, Marvell is looking at the SPECrate 2017 Integer Peak performance of the chips. The ThunderX3 is the CN110XX variant, which has 96 cores running at 2.2 GHz with a turbo boost to 3 GHz with a 240 watt thermal design point. These are compared to 28-core Intel Xeon SP 8280 Platinum at 205 watts and a 64-core AMD Epyc 7742 at 225 watts. Marvell is doing adjustments from the ICC and AOCC compilers to GCC where necessary and using the GCC compilers where possible to normalize everything to GCC performance levels across these architectures.
Here is the relative performance of these three processors, further normalized against the Epyc 7742 chips (meaning, their performance is set to 1.0 and the others are reckoned against this):
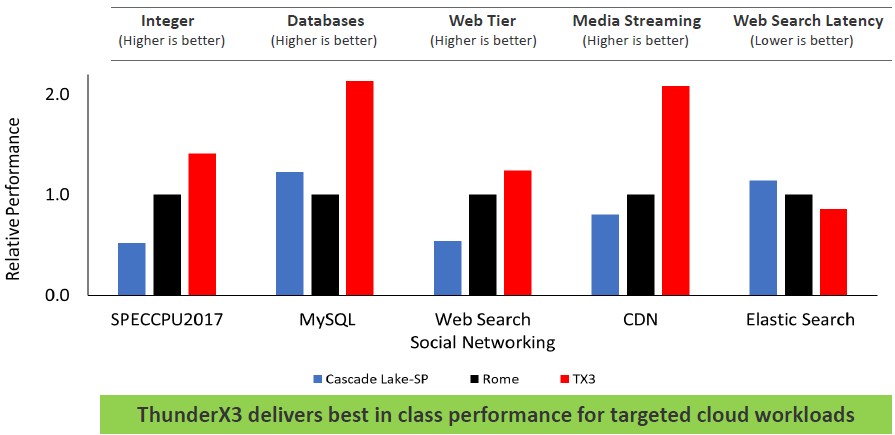
The top-bin ThunderX3 has some to a lot of performance advantage over the Epyc and sometimes the Xeon SP chips do better than the Epycs. Be careful with interpreting web search latency as gauged by Elasticsearch – lower is better, not worse in that part of the chart.
Now here is some insight into how Marvell thinks the top-bin ThunderX3 will stack up against the AMD Epyc 7742 and Intel Xeon SP 8280 on HPC workloads:
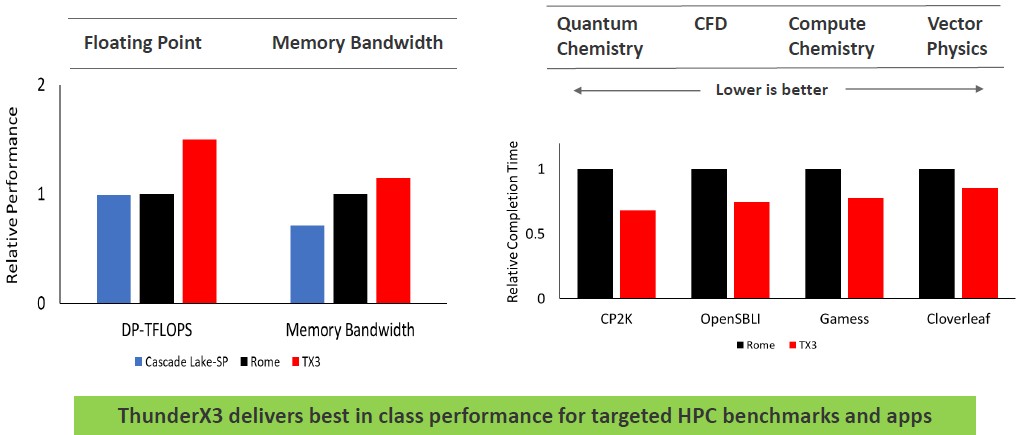
Because of the expected higher clock speed of its four SIMD units, Marvell is going to have a raw floating point advantage over the Cascade Lake Xeon SPs and Rome Epycs, according to the company. It will also have a small memory bandwidth advantage over the Rome chips and certainly some over the current Cascade Lake chips, but probably not on the future “Ice Lake” Xeon SPs Intel is planning to get out this year. And as you can see, systems based on the ThunderX3 are expected to have an advantage over the Rome chips on key HPC workloads. The question we have is how ThunderX3 will match up against the “Milan” Epyc 7003 family of chips shipping later this year as well. It is hard to say, but that gap could close up.
It would have been useful if Marvell had provided absolute rather than relative performance here. We could have had more fun with math.

The Road Ahead For Datacenter Compute Engines: The CPUs
Updated with just-announced Intel roadmap changes. It is often said that companies – particularly large companies with enormous IT budgets – do not buy products, they buy roadmaps. No one wants to go to the trouble of optimizing software for something that turns out to be a one-off product, forcing …

Betting On Mass Customization In A Post Moore’s Law World
If you wanted to wrest control of datacenter compute as embodied mainly in the Xeon SP processor away from Intel, there are a number of approaches that you might take. You could take Intel head on in the core of its market, as AMD has done with the Epyc line …

Supermicro Throws Its Weight Behind Arm Servers
Supermicro has become the latest of the big OEMs to add Arm-based systems to its portfolio, with the launch of its Mt. Hamilton platform based on the Altra line of Arm CPUs from Ampere Computing. Since Amazon’s Graviton chips aren’t available outside of AWS, and Nvidia has yet to ship …
These pseudo-benchmarks that vendors publish outside SPEC.org aren’t worth one cent.
Everyone seems to want to normalize their results to some arbitrarily-chosen imaginary constant. No-one explains how or why this normalization was done in the first place.
If a vendor wants to publish SPEC2017 results for their chip, they should publish them at SPEC.org. There are rules for submitting SPEC benchmark results that are designed to minimize hype, marketing and flat-out lies.
Absent that, this is nothing more than marketing in disguise.
There are extremely well known reasons why people choose not to compare directly to results from SPEC.org, because the specialized compilers that are rolled out for those results have coded tricks built into the compiler themselves to target individual SPEC benchmarks. These are ‘optimizations’ that would never be seen in real software in practice (see. 2006 libquantum), so they are no longer useful for organizations attempting to gauge performance in order to decide what to purpose. Really, the circumstances behind these submissions are the exact opposite of “minimizing hype, marketing, and flat-out lines.
That being said, I also wouldn’t really approve of these fixed scale factors. It’d be better if they just ran benchmarks with the same neutral non-cheating compilers with the same flags on both their chip and whichever competitors they are comparing with.
There seems to be some weird notion amongst certain corners of the internet (and I can suspect the origin of these) that SPEC workloads are only meaningful if submitted to SPEC.org, when that’s a fairly silly notion. The workloads are just workloads, which may or may not be representative of workloads that customers actually care about. Nobody is claiming those comparisons to be the be-all and end-all, there’s a reason other workloads are shown too. It’s just convenient because with SPEC people know at least exactly what the version of exactly whicb application code is being run, since it doesn’t change.
> SPEC workloads are only meaningful if submitted to SPEC.org [ … ]
That is correct. Because SPEC requires a supported compiler that can be downloaded and used by anyone. And hardware that can be bought by anyone. And the whole point of these SPEC requirements is that the claimed results must be repeatable and reproducible by anyone.
Clearly, in this benchmarketing work of fiction, none of this is true.
And you made that very same exact point in the paragraph preceding the sentence quoted above:
> It’d be better if they just ran benchmarks with the same neutral non-cheating compilers with the same flags on both their chip and whichever competitors they are comparing with.
As I said in my original post: hype, marketing and flat-out lies.
You would have a lot more credibility if you didn’t contradict yourself within two consecutive paragraphs.
And yet another “datacenter expert” article that forgets the key piece of the puzzle: that most data center apps are licensed annually by the core, and both ARM and AMD need more cores to do the same work as an Intel CPU. Save a few bucks or do something edgy and exciting and cost your business millions extra every year in software licensing.
Bet you get voted most edgy cool dood on earth!
We aren’t talking about Windows Server and a bunch of third party applications running on VMware virtualization here. This is aimed mostly at companies who own their own application stack, and often the system stack, and thus, that point is moot. We have said this repeatedly.
Maybe as the custom ARM ISA based designs get more of the server TAM others will begin offering up solutions. But as far as the Custom ARM ISA based market is concerned things are getting interesting but any comparisons of ARM and SMT4(ThunderX2) needs some core to core ThunderX2 to Power9(SMT4 variant) comparisons as well just to give some overall basis for comparison. CISC x86 compared to RISC ARM is just not enough and as far as Price/Performance, as Torvalds commented on that price/performance metric once, it’s not about Price/Performance as much as it is about that Price to a customer’s specific-workload’s performance that matters most. So server clients have their specific workloads in mind when looking at server hardware.
Also maybe the custom ARM server folks with the highest core counts and SMT capabilities should also look at testing out 3D rendering CPU workloads as well and some workstation intensive testing in addition to server workloads.
There was lot of selling off of custom ARM core designs in the marketplace over the past 6 or so years what with ThunderX2’s DNA traced back not to ThunderX1’s DNA but actually Broadcom’s Vulcan ARM core DNA. And what will become of Samsung’s discontinued Mongoose development as well as AMD’s mothballed Project K12(Custom server core IP). So loads of ongoing IP acquisition and bigger interests buying up smaller interests. I do not expect that AMD would sit on any IP that it has in its portfolio if that custom ARM competition began to make greater inroads against x86.
And really there needs to be more deep dives into each maker’s IP portfolios even for IP that’s been placed in mothballs. So all the custom ARM cores developed need to be looked at and even those that may have never made it fully to market or where to market but discontinued. And IP does make its way into the market via acquisitions and outright selloffs or licensing. Now Samsung’s mongoose may have been too fat for phones but what about other usage and AMD’s K12(Custom ARM server core) was rumored to be not much different than Zen at the hardware/architectural level and it was only that K12 was engineered to execute the ARMv8A ISA. OpenPower’s costs(Licensing/other) must be somehow limiting its adoption in the server market place but OpenPower/power9 home servers can be purchased and the entire processor firmware/software stack is open source as well.
So I’m interested not only in the CPU processor side but also the software/firmware and Motherboard platform ecosystem side as CPUs alone are just one part of the TCO. And the OS/Software and firmware ecosystem plays an even greater role in making any server hardware offering successful, and that includes OEM Partner support as well.
I’m less interested in benchmarks from any processor makers as the fine arts of compiler flags setting and cherry-picking of benchmarks is well developed. But the actual server market clients purchasing decisions holds more weight than benchmarks and what workloads are the products being used for. The clients do their own evaluations so their results hold the most weight above any other’s truly scientific third party testing with the processor makers results always in question(including any sponsored testing under NDAs/Strings attached).
The recent benchmarks of the Neoverse N1 Graviton2 instances as well as the marketing information discussed above in this blog definitely make me think ARM has caught up with Intel and AMD in performance and surpassed both in cost effectiveness.
While price-performance may be increasingly important during a recession, it is difficult, no matter how great, for a new product to beat not buying anything for saving money. In particular, I would not want to be a company counting on sales of a new computer architecture in the present economy.
List price is largely meaningless. It goes down strongly as negotiating power of the customer increases (i.e. large OEM/ODM, hyperscale). THe real question is how low can an ARM supplier go while having some margin? x86 can afford to go low because it can recover its NRE costs in other markets (desktop, laptop). Cavium has no real volume worth speaking of, so the top-bin parts will be in short supply or expensive to produce (yields). Intel/AMD have just to price it around the same Cavium is offering, and that’s the end of that.
There’s also a fair amount of ‘fiction’ (for the want of a better word) in the cavium slides. Sure, more threads means more throughput, but we’ve been there in the past with Calxeda and others who stitched together weak ARM cores to maximize throughput. SMT4 is more of the same. The reality was, and is, that 1T performance is paramount, SMT is gravy on top. You can’t have both at the same time. Hardly anybody wants 4X VMs at 1/4th the performance per VM (unless your VMs are sitting idle most of the time and even when not idle are not perf critical).
Ampere should really not be highlighting the top-end SKU. I expect that it can produce a 100-150W part that is higher perf and per/watt than its comparable x86 competition and that is where the real draw of the ARM many-core design can be. They’re overclocking their part to 3.3GHz at unknown power to eke out a 4% win (whether real or not) over its x86 rivals. ARM cores aren’t built to clock that high so it’s clearly inefficient here. They’re undercutting literally the only reason anyone would want to consider ARM: potentially lower power. (AMD has the ‘anyone but intel’ market covered solid)
Comparison above excludes for no good reason (except if trying to “prove” something that isn’t true) AMD CPUs with best price performance ( 7352, 7402 and 7452 and 7702P ) any of which have price/performance better than Ampere Altra even when using rather strange metrics used.
To the data centric,
Let’s look at whole market; client base station, cell network, network edge, metro edge, data center processing, aggregation, switch and route; public, private, enterprise, government communications, telecommunications, packet processing and inspection, security, switch and route, long haul carrier network and control; rural, suburban, urban spoke and hubs, network computing, HPC and supercomputing. What did I leave out?
Xeon (x86) Cascade Lakes has been just good enough to keep business, data processing, production operations and communications up and running, this generation of infrastructure, on Intel’s ability to supply incumbent use concerned with keeping product market and financial share and business humming along. Supply is key and lacking supply business can stall.
On a good understanding of processor and system availability across v2/v3/v4, Scalable Lakes, Scalable Lakes for the first time since Gainstown/Westmere offer no stretch?
In relation to current processor developments Scalable secondary ‘hand me down’ value is suspect. In relation to current level of network performance which is key to data center growth, network always comes first, as PAM 4 rolls out over the top, switch throughput in the middle, 5G from the edge existing compute infrastructure will be displaced quickly on new network communications and standards (programmable) and hard data processing replacements, light and heavy loads, specialties acceleration, better and best fit for use.
Replacement is inevitable. At this time beginning now and into the next 60 months, the total available market for processors of all types supporting existing infrastructure and build out exceed 1.5 trillion units of Xeon in use. On all the new possibilities let’s multiple by x2.
Across network communication and data processing, observing incumbents x86, ARM and Power, how incumbents and challengers are tapering into existing infrastructure, building out into new opportunities, there’s product category, market and volume potential for everyone.
Business will hum along, choice returns, industry and society will be better for it.
Mike Bruzzone, Camp Marketing
Take a look at the whole market; client base station, cell network, network edge, metro edge, data center processing, aggregation, switch and route; public, private, enterprise, government communications, telecommunications, packet processing and inspection, security, switch and route, long haul carrier network and control; rural, suburban, urban spoke and hubs, network computing, HPC and supercomputing. What did I leave out?
Xeon (x86) Cascade Lakes has been just good enough to keep business, data processing, production operations and communications up and running, this generation of infrastructure, on Intel’s ability to supply incumbent use concerned with keeping product market and financial share and the business humming along. Supply is key and lacking supply business can stall.
On a good understanding of processor and system availability across v2/v3/v4, Scalable Lakes, Scalable Lakes for the first time since Gainstown/Westmere offer no stretch?
In relation to current processor developments Scalable secondary ‘hand me down’ value is suspect. In relation to current level of network performance which is key to data center growth, network always comes first, as PAM 4 rolls out over the top, switch throughput in the middle, 5G from the edge existing compute infrastructure will be displaced quickly on new network communications and standards (programmable) and hard data processing replacements, light and heavy loads, specialties acceleration, better and best fit for use.
Replacement is inevitable. At this time beginning now and into the next 60 months, the total available market for processors of all types supporting existing infrastructure and build out exceed 1.5 trillion units of Xeon in use. On all the new possibilities let’s multiple by x2.
Across network communication and data processing, observing incumbents x86, ARM and Power, how incumbents and challengers are tapering into existing infrastructure, building out into new opportunities, there’s product category, market and volume potential for everyone.
Business will hum along, choice returns, industry and society will be better for it.
Mike Bruzzone, Camp Marketing
Would like to see performance comparison of graviton2 vs altra vs thunder x3
the real situation is completely different
for example https://s.dou.ua/storage-files/1_SPECrate2017_int_Fixed.PNG
Where we can find link for test for this results?