

If you want inspiration for a hyperscale, resilient distributed block storage service, apparently a jellyfish is a good place to start looking for architectural features.
That is precisely what Amazon Web Services has done to create Physalia, the massively distributed database service that stores the metadata for its Elastic Block Store service, which as the name suggests provides block storage for applications running on that public cloud.
Werner Vogels, chief technology officer of Amazon, talked a bit about Physalia, which gets its name from Physalia physalia, also known as the Portuguese man o’war jellyfish, at the re:Invent conference last December and the techies behind the Physalia product have just released a paper describing what it is and how it is different from other high speed databases and datastores. While it is highly unlikely that AWS will ever open source Physalia, it is possible that it will inspire others to re-create elements of its architecture that will be open source, much as has happened with many hyperscaler and cloud builder technologies in the past.
Millions Of Databases Instead Of One Or Several
In any kind of distributed system, sooner or later a component is going to fail, and the number of failures and their effect compounds as the number of components grows in the aggregate system. And so, system architects have to be very careful, particularly when it comes to a network failure linking components, which is often called a network partition to indicate that systems on both sides of the cluster can be working fine, but the two halves of the application and datastores underlying them cannot speak to each other and this causes all kinds of problems.
The trick is to be very precise about what needs to happen, to anticipate these problems, and to find the best ways possible to address them under the circumstances. No approach is perfect, particularly when it comes to databases. But when you are creating a database for the metadata that underpins the Elastic Block Storage backbone at Amazon Web Services – very likely the largest set of the largest individual block storage device on the planet – you have to get about as close to perfect as possible or people are going to lose data, lose patience, or both. And that would mean lost business for AWS. It is ten times harder to get a new customer than it is to keep an existing one, so keeping the customers that are using the infrastructure services happy is the key to revenue growth at AWS.
Some setup is necessary before getting into the details on the Physalia massively distributed database that AWS created to manage the metadata for the EBS service. In the hyperscale and cloud builder world, as Vogels pointed out in his keynote, “Everything fails all the time.” And that means companies operating at scale have to be obsessed not just about the availability of individual components and how that potentially changes the system availability as it runs at tremendous scale, but also about minimizing the blast radius – the number of devices and therefore the number of customers who are affected by some kind of outage.
Getting the blast radius as small as possible is a tricky business. As Vogels reminded everyone, you can split workloads across regions – spanning multiple availability zones within an AWS region – that helps, and then you can also break down these regions into cells that are podded up with smaller capacities and therefore make outages potentially smaller. Ditto for architectures that are just zonal – living in one availability zone at a time – you can break these down into cells as well so fewer customers are affected by any potential outage.
“It is always the case that we want to reduce the blast radius, but how do we pick the size of the cells?” Vogels asked rhetorically. “If you have smaller cells, you can really reduce the blast radius, and it is easy to test and it is easy to operate. But if you have larger cells, they are more cost efficient and they reduce splits and so the whole system is easier to operate. So the question is always how to really nicely partition your system so you can actually make use of cell-based architectures.”
EBS is a zonal service on AWS, and it is not just a collection of disk volumes running on a bunch of disk drives. The data is sharded into many pieces (for a number of different reasons), and a copy of each shard is replicated for availability. A configuration manager, which sits on a separate network from the one that connects EBS to the Elastic Compute Service, controls the access to any of these shards – if an active shard fails, it knows where to turn on the inactive replica and keep the data flowing in the block service and – very importantly – starts re-replicating that shard to another location in the storage so EBS can take another hit shortly and not lose data. This doesn’t happen a lot, but lots of services are failing at the same time, then the database that keeps track of all the state of all of those active and inactive and replicating EBS volume shards has to be superfast and crazy resilient. Because AWS is handling millions and millions of volumes, that configuration manager underneath EBS could easily become overwhelmed during a widespread outage.
Just like the people at Google, namely Eric Brewer, vice president of infrastructure at the search engine giant who formalized the CAP Theorem of distributed databases and datastores back in 1998, the people at Amazon are well aware that the need to worry about three things – consistency, availability, and partition tolerance, so maybe CAPT was a better abbreviation? – and you can only do any two of the three well. In practice, distributed database and datastore designers try to get as close as 100 percent for all three as possible, and Google’s Spanner globe-spanning relational database with a giant, nuclear-clock synchronized control plane is one way to do it, and the Physalia database underpinning EBS takes a very different approach that creates a massively parallel and intelligently placed metadata that migrates along with the actual EBS storage chunks and therefore radically minimizes the blast radius of an outage with the storage service.
Building Blocks
Amazon’s Elastic Compute Cloud virtual machine compute service, or EC2, and its companion Simple Storage Service object storage service, or S3, debuted together in March 2006 and set off the second – and finally successful – wave of utility computing that had been underway for nearly a decade before Amazon got the product right at the right time, just ahead of the Great Recession. While S3 was great for a lot of things, there are plenty of stateful applications that need something a little more hefty than the ephemeral storage that was available inside EC2 instances at the time and also needed block storage to run things like databases, which need block storage and at a substantial scale. EBS was launched in August 2008, and it allowed customers to access the raw storage directly or to format it with a file system of their choice and then mount it from an EC2 instance.
In designing EBS, you might think that what Amazon had done is create a kind of giant virtual, clustered storage area network out of commodity servers and storage enclosures, first with disks and then with a mix of disks and flash, all linked through the vast Clos networks that public cloud and hyperscaler datacenters employ. But that is not what Amazon did. Instead, EBS is a bunch of smaller virtual block storage appliances that initially scaled volume sizes from 1 GB to 1 TB, with up a maximum of 20 volumes allocated to any one customer.
Today, the flash-based EBS service using gp2 instances scales from 1 GB to 16 TB with a maximum throughput of 250 MB/sec per volume and of 2,375 MB/sec per EC2 instance; I/O operations per second top out at 80,000. The io1 instances have four times the IOPS and throughput and cost 25 percent more plus some incremental fees on top of that for the incremental IOPS. The disk-based EBS service using st1 instances range in size from 500 GB to 16 TB, with a maximum throughput of 500 MB/sec per volume and a maximum IOPS of 500. Volumes can be ganged up to span petabytes of capacity across applications. The sc1 instances based on disks for EBS have half that IOPS and throughput and cost a little more than half the price of the st1 instances. These four different EBS instance types allow customers to tune their EBS performance (in terms of both bandwidth and latency) and capacity specifically for different workloads.
It is a good thing that EBS itself is not a single, giant virtual SAN because it makes it much easier to manage this block service, and as it turns out, much easier for it to recover from failures thanks to the invention of the Physalia database. And this is one of the reasons why AWS can promise 99.999 percent availability of the EBS service within an availability zone within one of its regions. Multiple datacenters make up an availability zone, and multiple availability zones each have their own power and cooling and facilities comprising a very coarse-grained blast radius and together comprise an AWS region. We know that AWS has 22 regions with a total of 69 availability zones, but we do not know how many datacenters are in each zone, and therefore we cannot easily estimate how many compute and storage servers AWS might have. It is probably many millions of servers with many tens of millions of EC2 instances and many millions to maybe many tens of millions of EBS volumes. We have a sense that the EBS volume count is in the millions because Vogels said that there were “millions and millions” of tiny Physalia databases.
An aside: While AWS is talking about the Portuguese man o’war – a colony of quasi-independent microorganisms working as a collective that we perceive as a single jellyfish – it is just as accurate to say that the EBS service itself is inspired by this cell-based architecture and indeed, most cloud services with resilience do.
When The Bits Hit The Fan
According to the Physalia paper, written by Marc Brooker, Tao Chen, and Fan Ping of AWS, back in April 2011, something very bad happened to make the cloud giant rethink the way the control plane data for EBS was itself stored. The EBS control plane has to keep track of all of the replicated shards of data in the volumes attached to EC2 instances that are using EBS, and back then all of this configuration data was stored in a database that also housed the EBS API traffic. It worked fine, until someone made a network change that partitioned the network by accident and it caused 13 percent of the EBS volumes in a single availability zone to go dark. A network storm ensued between the EC2 instances looking for data, the EBS nodes where the data replicas were stored, and the EBS control plane that could designate the backup as the primary and get data fed to those EC2 instances. But a race condition ensued, with the EC2 instances jamming the EBS control plane, which caused it to not be able to remirror data, and the EBS service went into a brownout condition, affecting all EBS API performance and availability across the region where the availability zone resided.
It took a while to figure out what had happened with EBS on that day, and in 2013, AWS set out to create a new database that could handle the peak loading that happened during an outage when all of those shards in the EBS volumes would need to be shifted from the primaries to the backups and a new backup would have to be created and designated as such to provide high availability as well as strong consistency – and to minimize the blast radius of an outage should one occur.
The key insight that the techies at AWS had was that not all EC2 clients needed to have access to all EBS data all the time – in fact, that would be a very bad thing for a public cloud utility to do for data security and sovereignty reasons. And because of this, the keys for the EBS volume partitions used to control replication of EBS shards could be distributed across the network in many databases instead of one.
“Obviously there are multiple things that can cause outages and the blast radius will vary depending on what cause that is,” explains Marc Brooker, senior principal engineer at AWS. “With Physalia, we create a cell per volume and so a logical failure of a cell – either caused by a network partition or a power outage or whatever – is isolated to the failure of a single EBS volume. And that’s very different from previous architectures, which would take advantage of scale by grouping lots of volumes together.”
Physalia, which is a key-value store, does not hold the customer data, but just the keys to the partitioning data that controls where the data and its replicas are located. And because it has been imbued with knowledge of the location of data volumes and the topology of AWS datacenters and where EBS volumes are physically located, it can move this EBS control plane data around so that it is always near the EC2 client that is using it. And hence, the odds that a network partition or some other kind of failure in an availability zone or region will cause the race condition like when the EBS control data was stuffed into the API database – instead of freestanding and distributed as it is now – are lower and therefore the chance that EBS can recover from these errors (or more precisely not be bothered by them at all) is much higher. The blast radius is reduced.
The way that this is done is pretty hairy, and this is where the jellyfish comes in. The man ‘o war is really a collection of standalone organisms that cannot live outside of the colony of organisms.
The keys for controlling the EBS shard partitions are chopped up and replicated in seven nodes (not physical server nodes but logical elements of a distributed state machine), and a Paxos protocol is used to build consensus across the nodes as the data in them changes; one of the nodes is designated as the master in each Paxos cell and keeps that job until it fails, and then one of the other nodes takes over. This approach allows for extremely high consistency for this distributed EBS control plane data. In fact, the EBS control data stored in Physalia is about 5,000X more available than the replicated customer data stored in the sharded EBS volumes.
Here is the point: Instead of a centralized control plane – as EBS had before – it is a colony of these Physalia cells, made up of logical, mathematical data nodes linked by Paxos, that does the controlling, and these tiny databases are spread around the literal, physical server nodes in the AWS infrastructure and move in such a way that they are kept close to the EC2 instances with which the shards of the EBS volumes are associated.
This placement of the cells, embodied in little Physalia databases, is what allows for AWS to cut back on the EBS blast area. And the fact that nodes can be shared across cells means that, as an EC2 instance moves, the data from the nodes can be moved to another Physalia database that is closer to that EC2 node, with a logical cell stretching for a bit before snapping over to the new location, without breaking the Paxos linkages between the nodes to the extent that the master node in the cell fails and therefore the means to locate and replicate data gets lost, too. The location of the cells is stored in an eventually consistent cache called, suitably enough, the discover cache. This does not have to be perfectly consistent, apparently, to work well.
So what is the effect of moving from the centralized database to Physalia for the EBS control plane? Take a look at these two charts:
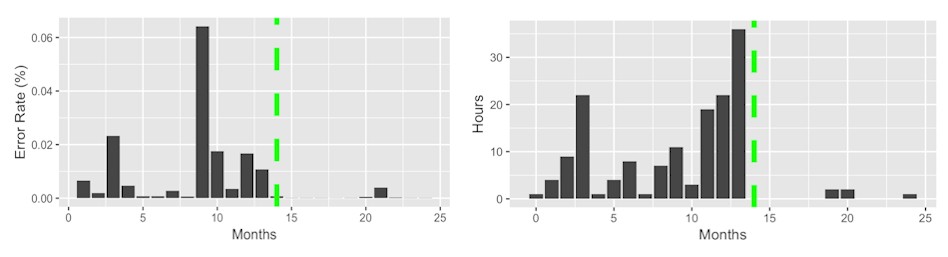
The chart on the left above shows the error rate of the primary copy of the EBS volume trying to reach the configuration data in either the system before Physalia (on the left of the green line) for 14 months and after Physalia was the EBS control plane data store (for a little more than nine months). Both hardware and software infrastructure failures as well as overload caused the higher error rates; these issues did not magically go away after Physalia was installed, but the new distributed state machine and the intelligently distributed control data (putting it close to the EBS volumes they controlled) could largely ride out these failures. This is the whole point of bringing this up, as far as AWS is concerned.
The chart on the right above shows the number of hours per month, using the old and new EBS control plane datastores, had an error rate greater than 0.05 percent in production. Again, you can barely see it.
While this is all very well and good, and is meant to inspire system architects and site reliability engineers, it seems very unlikely that AWS would ever open source Physalia. But, there is no reason why some intrepid database designer could not mimic it, just like Doug Cutting of Yahoo created Hadoop and its Hadoop Distributed File System as a clone of Google’s MapReduce and Google File System, or the way CockroachDB has created something very much like Google’s Spanner distributed, globe-spanning relational database. Then, all kinds of centralized control plane databases and datastores could, in theory, be made massively distributed like the services they control and exhibit the increased resiliency that AWS is showing off.




Be the first to comment