

Training deep neural networks is one of the more computationally intensive applications running in datacenters today. Arguably, training these models is even more compute-demanding than your average physics simulation using HPC. Nevertheless, deep learning has rather different hardware requirements than that of conventional high performance computing.
For the most part, that has to do with numerical formats. While most HPC models rely on double precision floating point (FP64), with the occasional excursion into single precision (FP32), deep learning models are typically built with FP32, supplemented by half precision FP16. In general, the more you can use lower precision values for calculations, the better off you are since cutting the number of bytes in half doubles data throughput for an application. And that goes for HPC, deep learning, or anything else.
All of these formats are based on the IEEE 754 standard, which was set up more than 30 years ago when floating point was primarily used for scientific computation. As a result, the field that contains the significant bits in these IEEE formats (the mantissa or significand) take up most of the space: 52-bits in FP64, 23 bits in FP32 and 10 bits in FP16. The idea is to maintain high precision, which reflects its original intended use.
The exponent field for these IEEE formats is relatively smaller, which means the dynamic range is limited. The rationale is that if you need more range, you just keep using larger formats – FP32, FP64, FP128, and so on – until the exponent field is large enough to support the numbers your application needs.
But for deep learning, high precision is not necessarily desirable. “Deep learning, in fact, performs better with lower precision,” says Pradeep Dubey, who directs the Parallel Computing Lab at Intel. While he acknowledges that sounds confusing, his explanation is the when you’re training deep learning models, “you need an ability to generalize.”
What he’s referring to is when building a model, it’s better construct something that is generalized enough to detect a range of possibilities. For example, in pattern recognition where you’re looking for a particular object like a cat, it’s better not to be too precise about the pattern that represents a cat. Too much precision would limit the kind of images that would be recognized or even prevent the model from converging while training.
On the other hand, you do need enough of a numeric range so the model will be able encompass a decent number of possibilities – what Dubey calls “learning the curve.” Thus, for deep learning, the range is more important than the precision, which is the inverse of the rationale used on for IEEE’s floating point formats.
According to Dubey, IEEE’s FP16 format reduces the dynamic range too much in an effort to keep more bits for precision, but again, that’s not the tradeoff you want for deep learning computations. What often happens is that with FP16, the model doesn’t converge, so you end up needing to tune the hyperparameters – things like the learning rate, batch size, and weight decay.
Thus was born bfloat16, affectionately known as 16-bit “brain” floating point. Developed originally by Google and implemented in its third generation Tensor Processing Unit (TPU), bfloat16 has attracted some important backers. In particular, Intel is implementing bfloat16 instructions in its upcoming Cooper Lake Xeon processors, as well as on its initial Nervana Neural Network Processor for training, the NNP-T 1000.
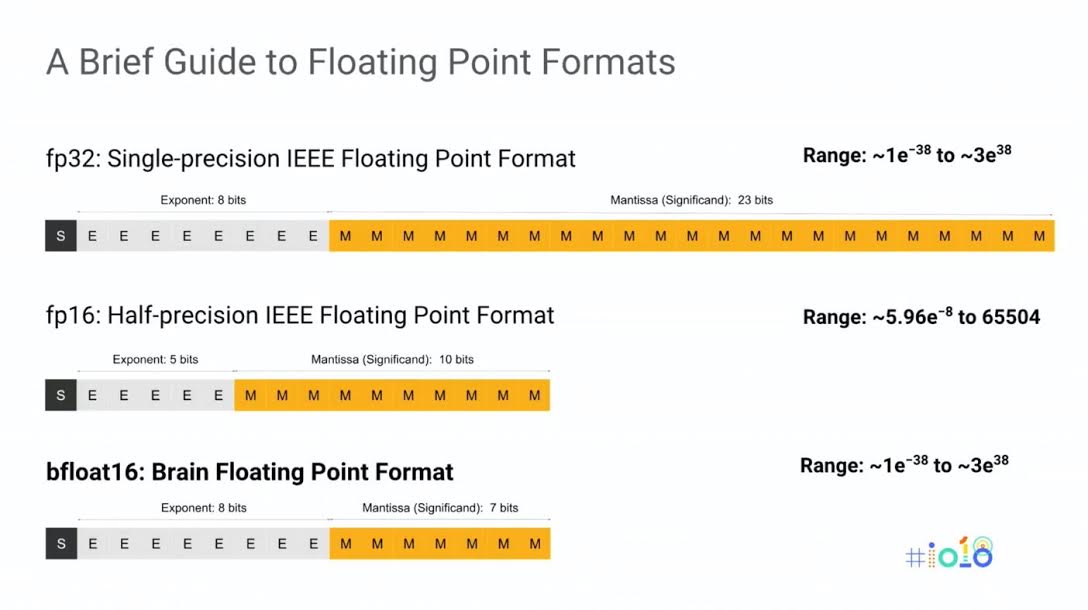 Bfloat16 has a 7-bit mantissa, along with an 8-bit exponent, which means it has the same range as FP32, but with less precision. According to Intel though, that’s more than enough to cover the range of deep learning domains. To prove the point, Dubey and his team from the Parallel Computing Lab, along with some Facebook researchers, set out to test bfloat16 on some typical deep learning models, encapsulating convolutional neural networks (CNNs), Recurrent Neural Networks (RNNs), and Generative Adversarial Networks (GANs).
Bfloat16 has a 7-bit mantissa, along with an 8-bit exponent, which means it has the same range as FP32, but with less precision. According to Intel though, that’s more than enough to cover the range of deep learning domains. To prove the point, Dubey and his team from the Parallel Computing Lab, along with some Facebook researchers, set out to test bfloat16 on some typical deep learning models, encapsulating convolutional neural networks (CNNs), Recurrent Neural Networks (RNNs), and Generative Adversarial Networks (GANs).
In particular, Intel used bfloat16 to train AlexNet, ResNet-50, DC-GAN, SR-GAN, Baidu’s DeepSpeech2, Google’s neural machine translation (GNMT). They also benchmarked a couple of industrial deep learning workloads: a Deep and Cross Network, and a DNN recommendation system. The bloat16 data was used to hold the tensor values (activation and weights), with results accumulated in FP32.
At this point, Intel doesn’t have bfloat16 implemented in any of its processors, so they used current AVX512 vector hardware present in its existing processor to emulate the format and the requisite operations. According to the researchers, this resulted in “only a very slight performance tax.”
Dubey says the emulated bfloat16 worked beautifully across the workloads. The models converged in the same number of iterations as when using FP32 for all the computations, with any hyperparameter tuning required. In fact, the bfloat16 runs tracked the FP32 runs almost exactly, as documented in the research paper penned by Dubey and his colleagues.
Essentially, they were able to get the benefit of the 16-bit throughput for free, the slight caveat being that some of the work, like the fused-multiply add (FMA), needs an FP32 accumulator. But, according to Dubey, depending on how much you’re able to keep the computations in the bfloat16 realm, you should be able to improve training speed by at least 1.7x. Which is a big deal when training a model takes days or even weeks.
The researchers conclude that bfloat16 is able to represent tensor values across many application domains, including vision, speech, language, generative networks, and recommendation systems, and doesn’t suffer from the drawbacks of FP16 implementations. They go on to say that they “expect industry-wide adoption of bfloat16 across emerging domains.” Of course, given that Intel will be supporting the format in both its general purpose Xeon line and its purpose-built NNP processor, that adoption is more assured than ever.




Nextplatform covered Gustafson’s Posit a couple weeks ago, didn’t even give it a mention in this article. https://www.nextplatform.com/2019/07/08/new-approach-could-sink-floating-point-computation/
I wonder what would of been the better technology to back.
> What he’s referring to is when building a model, it’s better construct something that is generalized enough to detect a range of possibilities.
Please let me know if you’d like to hire an editor
The amount of precision which is required would be satisfactory even with Bfloat16. Also, the slight error that it results in, will be like a small noise which is technically termed as ‘”bias”. A model that we generally design is to fit and the available data samples and to make accurate prediction of unknown sample, in which we consider some bias in order to generalize our model so that it doesn’t make wrong predictions. Hope what I’ve understood is not wrong. Anyone can correct me If I’m wrong.