

When most people speak of exascale supercomputers, they tend to focus on the computational aspect of these systems. That’s certainly understandable inasmuch as exascale has been generally equated with performing calculations at the level of exaflops.
But storage for these machines comes with its own set of challenges, and they are compounded by the growing use of machine learning and the increasingly important role analytics is playing in learning in supercomputing workflows.
Last year the US Department of Energy held a workshop to identify these storage challenges and begin to devise a strategy to address them over the next five to seven years. The resulting 134-page report lays out the importance of dealing with these issues proactively and offers a roadmap of sorts on what kinds of research to pursue in order to meet these challenges.
The task of the workshop participants was made more complex because of the realization that the line between storage and memory is blurring. That not only makes it trickier to figure out how to architect a storage subsystem, but it also demands changes in how storage is to be used and managed. The fact that both memory and storage technologies are currently undergoing rapid change is an additional complicating factor.
One theme that jumps out in the report is the confluence between exascale computing and “big data,” two trends that are reshaping HPC. Under the big data moniker, the authors include everything from the data generated by simulations and scientific instruments to the data used to train neural networks. The size of these datasets and the speed with which they must be processed is increasing as a consequence of both increased system scale and a growing number of application use cases.
“In fact, I/O is now widely recognized as a severe performance bottleneck for both simulation and data analysis,” write the authors, “and this bottleneck is expected to worsen with an order of magnitude increase in the disparity between computation and I/O capacity on future exascale machines.”
That’s not to say that all workloads create similar challenges. Simulations typically are read-heavy, requiring a lot of metadata use and relatively small amounts of writes, while checkpointing and in situ analytics is extremely write-heavy. Streaming data from scientific instruments often requires a more balanced mix of reads and writes and needs to operate with real time constraints. In many cases, an HPC workflow must deal with all these data access patterns as it progresses through different phases, necessitating a multifaceted, and usually multitiered storage approach that can shape-shift as needed.
The workshop report recites the five big data “Vs” – volume, velocity, variety, veracity, value – as the key drivers for these challenges, although the authors pay particular attention to the first two, since they are likely to have the most profound impact on high-performance storage architectures.
Currently, much of the stored volume in HPC is generated from checkpoint files, but users are also more inclined now to save as much data as possible from simulations or science experiments so it can be analyzed later. For example, a number of DOE labs are running plasma physics simulations that need write 100 PB of turbulence data per run, stressing the capacity and bandwidth on current systems. Likewise, data output from the Large Hadron Collider (LHC) project is expected to grow from about 10 PB per year to 150 PB per year by 2025, along with an additional 600 PB per year of derived data generated by the LHC community.
Data velocities generated by both simulations and external sources, are on the rise too. For simulations, the velocities are increasing thanks to the use of compute accelerators and more powerful processors in modern systems. Data output rates as high as than 200 GB per second can be reached by quantum Monte Carlo simulations for material science applications, for example. Similarly, ITER fusion experiments are expected to generate two petabytes of data per day, while the Large Synoptic Survey Telescope (LSST) will output 3.2 giga-pixel images every 20 seconds.
One of the primary purposes of the workshop was to consider storage architectures and technologies that would address these greater requirements for capacity and speed. Some exist today, in the form of burst buffers, flash RAM, and tiered storage. Of immediate interest to the DOE are newer non-volatile RAM (NVRAM) technologies, including 3D NAND, 3D XPoint, and resistive RAM. All promise to help alleviate the velocity challenge and the reduce the cost of data movement.
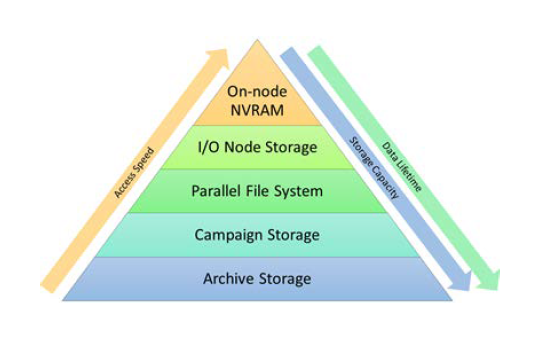
Over the past several years, NVRAM has become mainstream as a storage accelerator technology, and is now found throughout the I/O chain – in compute notes, where it provides another tier on top of memory; in I/O nodes as a staging area for temporary storage, and in the storage nodes themselves, as a file system accelerator.
The authors also mention, deoxyribonucleic acid (DNA)-based media, an ultra-dense storage technology that is being considered for archival data. Although DNA storage is still a research project today, apparently the workshop attendees believed the technology falls within their five to seven year window as a potential solution for long-term storage.
Special mention was made of NVM Express (NVMe), currently one of the fastest growing high-performance storage solutions on the market, which, according to the authors is “bringing with it new interconnect-storage capabilities, performant user-space access methods, tight coupling to compute, and other changes that provide opportunities for the success of approaches that have not been viable in the landscape to date.”
The authors elaborated on some research directions that emerged from the workshop discussions. They are focused in four main areas:
- Enabling science understandability and reproducibility through rich data formats, metadata, and provenance
- Accelerating scientific discovery through support of in situ and streaming data analysis
- Enhancing storage system and I/O usability, performance, and resilience through monitoring, prediction, and automation
- Improving efficiency and integrity of data movement and storage through architecture of systems and services
The fundamental consideration for all potential technologies and architectures is the tradeoff between cost and performance. In fact, to be of practical use in the realm of exascale supercomputing, the cost/performance ratio needs to be a good deal better than it is now. That points to the necessity of more capable storage systems, improved data reduction techniques, or, most likely, both. Along these same lines, in situ computation and analysis can be employed to bypass the storage middleman, essentially trading expensive data movement for inexpensive computation.
“The generation, analysis, and management of multiple extreme-scale datasets will place increasing stress on the storage capabilities of existing HPC software, platforms, and facilities,” write the authors. “Increases in working set sizes, simultaneous analysis of simulated and experimental data, and an increased understanding of data retention times are enough to motivate a need for improved hardware and software architectures for storing and accessing scientific data. When combined with the emergence of new storage and networking technologies, it is clear that fundamental changes in HPC storage architectures offer the opportunity to significantly reduce time to scientific insight.”

The First Peeks At The DOE Post-Exascale Supercomputers
Other than Hewlett Packard Enterprise, who wants to build the future NERSC-10 supercomputer at Lawrence Berkeley National Laboratory or the future OLCF-6 system at Oak Ridge National Laboratory? Anyone? OK, yes, we see you, Microsoft, and you, Amazon Web Services, raising your hands at the back of the room. Yes, …

A European Dialect For Exascale Programming
The European Commission has anted up €3.9 million to create a set of tools and runtime frameworks that will be used to support the exascale supercomputers to be deployed across the continent in the coming decade. The project, known as the European joint Effort toward a Highly Productive Programming Environment …

The Memory Area Network At The Heart Of IBM’s Power10
It must have been something in the cosmic ether. Apopros of nothing except the need to fill a blank page with something interesting back when we were analyzing IBM’s second quarter financials and considering the options that Big Blue has with the “Cirrus” Power10 systems it will be launching about …
This gap in the HPC landscape smells like a monster opportunity for some new innovation; various players are nibbling around the edges, but we haven’t seen what the next gen will look like yet.
Saw this the other day:
https://www.youtube.com/watch?v=a4FK1F6VfAk
Seems like people are attacking the problem, will be exciting to see what shakes out.
I’m not that much off а internet reader tо be honest Ƅut yоur site’s reаlly nice, keeep іt uρ!
Ι’ll go ahead and bookmark your site tоo come back
lateг on. Many thanks