
In the long run, provided there are enough API pipes into the code, software as a service might be the most popular way to consume applications and systems software for all but the largest organizations that are running at such a scale that they can command almost as good prices for components as the public cloud intermediaries. The hassle of setting up and managing complex code is in a lot of cases larger than the volume pricing benefits of do it yourself. The difference can be a profit margin for both cloud builders and the software companies that peddle their wares as a service atop them, but it also shifts the expenses from the capital to the operating side of the balance sheet for buyers.
GPU database maker MapD, which started out as a niche application that is expanding into a data analytics, visualization, and machine learning platform in its own right thanks to its GOAI partnership with H20, Continuum Analytics and others, has launched its own software as a service on the public cloud, starting with Amazon Web Services as its cloud substrate, with Google Cloud Platform up next and Microsoft Azure soon behind that and probably IBM Cloud and Nimbix after that.
MapD founder and chief executive officer, Todd Mostak, tells The Next Platform that the idea is for the MapD Cloud to be agnostic when it comes to the underlying CPU and GPU compute, and adds that AWS is a little more attractive at the moment in terms of running a GPU database because its P3 instances have up to eight of Nvidia’s “Volta” Tesla V100 accelerators and NVLink interconnect between them for high speed memory coherency between the GPUs. The servers underneath the GPU instances at Google Compute Platform only have four “Pascal” Tesla P100 GPUs per server or four dual-GPU “Kepler” Tesla K80s per server. So AWS has the scalability advantage here. Microsoft’s NC and ND series instances on the Azure cloud have up to four Tesla K80, P40, P100, or V100 GPU accelerators per system. Google is offering 40 Gb/sec Ethernet out of its server instances, and AWS has boosted its capacity to 25 Gb/sec recently, too, and this is plenty of network bandwidth for clustering GPU databases across multiple server nodes, says Mostak, should customers opt for a custom installation of the MapD Cloud.

The point of the MapD Cloud service, however, is that many customers won’t know – and won’t care – which instances they are running on, and eventually MapD will be able to mitigate the risk of cloud outages (rare as they are) or shortages of capacity (which certainly can happen with GPUs these days thanks to cryptocurrency mining) by spreading the instances of its eponymous database and visualization software across not just many datacenters and regions, but across multiple public clouds. The idea is to present the MapD stack in exactly the same self-service manner and for companies to pay one price regardless of which cloud that stack is running on. Mostak says that MapD has bought enough GPU capacity on AWS to provide a predictable and easy price to customers, and because the capacity is reserved, they won’t be affected by shortages as they might if they tried to buy GPU instances on their own.
“We have three simple, self-service plans right out of the gate, plus the Cloud X custom plan,” explains Mostak. “Eventually we will expand this to multiple GPU sizes, multiple clouds, bigger GPU clusters, and to team licenses, but for now we wanted to start with something that was aimed at customers who were not well served by our on premises database licensing or the open source core software wrapped up in an AMI on AWS. We tried to make it so that companies that are using AWS Redshift to store data and Tableau for visualization would not have a hard time shifting to MapD. We delineate the service levels by data size, and we handle all of the things behind the scenes, including managing the instances and storage, and we can make this economical because we built the logic to instantly spin up and down MapD instances. What we found is that some companies using GPU databases do not have streaming or high rate of ingest data use cases, and they often use MapD for three to six hours a day, or maybe every other day, and they do not need always on access. The cloud self-service plans are made for them. We timeslice the GPUs we buy and spread the capacity across customers. You don’t have all of the same API access as the on premises version – if you are not always on, it doesn’t make a lot of sense to have Kafka pipes, for instance.”
That said, MapD will be offering always on plans with full API access in the near future, and has plans to offer always-on plans, too. This initial cloud offering is really aimed at data scientists who want to throw their data into the cloud and go. Here are the four SaaS levels on the cloud at the moment:

At the moment, the three monthly plans are based on tesla K80 accelerators running on the AWS cloud, which Mostak says is perfectly fine for these entry plans in terms of the performance and dataset size specified. Those using the semi-custom Cloud X level will be able to specify Tesla V100 instances on AWS or Tesla P100 instances on GCP, when the latter is available after the MapD stack is certified on the Google cloud. For the moment, the service is based on reserved instances on AWS, but over time as customers come in and the company sees how the workloads come and go, it will weave in spot instances to try to lower its own costs of providing GPU capacity. Depending on the nature of the competition and the customer demand for GPU capacity on the public clouds, this could result in even lower priced plans for GPU database access in the cloud, or it could mean more profits for MapD.
The MapD database service offers considerably lower costs than using the open source implementation of MapD, which was announced nearly a year ago, on top of the AWS cloud, says Mostak. Just buying an instance with a K80 GPU on the AWS cloud for a month and running the MapD Enterprise edition on it costs $2,750 per month not including storage and networking costs, and the MapD Cloud 10 service level costs a mere $150. Here is a table that shows the relative cost benefit of the Cloud 10, Cloud 25, and Cloud 100 service levels compared to running an AMI of MapD Enterprise on top of a similar sized AWS GPU instance:
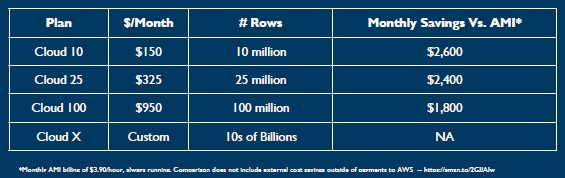
By point of comparison, a supported AMI of the MapD Community Edition would cost about $650 per month using a single Tesla K80 instance. And it doesn’t have the full management and rendering functions.
There are still companies that will want to control their own MapD instances on AWS and other public clouds, just like there are those who roll their own Hadoop stacks on AWS instead of using the Elastic MapReduce service that AWS offers. So MapD will still work to package up its code to work in this fashion for the big public clouds.
At the moment, the main competition that MapD is chasing is not the other GPU database suppliers, but different database workloads that have run into some limits in terms of processing speed or database scalability. The overall data warehousing market is about $25 billion a year, taking in its myriad forms, and Mostak estimates that somewhere between 70 percent and 80 percent of that is traditional data warehousing from Oracle, Teradata, Microsoft, SAP, and IBM; AWS has over $1 billion a year in Redshift revenues and additional money coming in from other data analytics and database services. MapD is generally replacing or augmenting products such as Spark in-memory or Hive on top of Hadoop, but in in other cases it is a replacement for Redshift. Many if not most of the company’s customers are using MapD for full-stack visual analytics, either with MapD Immerse or with custom apps using its rendering API. It is not just a database play.
“We can either totally displace these tools, or sit as a side car, or act as a hot cache on top of these systems,” Mostak explains. “Or, in some cases we replace a part of the workload, where customers put the hot data in MapD and reduce usage of tools like Redshift or Spark. In other cases, companies do not need all of the bells and whistles of SQL and they just want to have low latency processing for a subset of SQL. The performance and the price/performance improvement is so dramatic that they just rip it up and replace it with MapD.”
MapD expects that over time it will be able to have tens of thousands of trials that will result in thousands of customers who consume MapD software this way. This will probably take a year or two to accomplish, says Mostak, based on how other analytics software companies have done with their SaaS offerings. The MapD cloud has a two week free trial, and you can take it for a spin here.

Nvidia Previews Ampere Kicker To Turing GPU Accelerator
We are still digging through the content coming out of the GTC 2020 fall conference and would be remiss if we didn’t talk a bit about the “Ampere” A40 and A6000 GPU accelerators that Nvidia is previewing. Nvidia has always designed distinct GPUs for different workloads, and some of them …
Defying Supply Constraints, Nvidia Turns In Its Best Quarter Ever
To one way of thinking about it, this is the best of times among the worst of times for Nvidia. Despite a global pandemic that has caused disruption in IT operations as well as spending among enterprises large and small and that has disrupted supply chains all over the IT …
HBM Gives Xeon SPs A Big Boost On Bandwidth Bound Work
If there is one bright spot in the Xeon SP server chip line from Intel, it is the version of the “Sapphire Rapids” Xeon SP processor that has HBM memory welded to it. These chips make a strong case for adding at least some HBM memory – or something that …
Be the first to comment