

If the history of high performance computing has taught us anything, it is that we cannot focus too much on compute at the expense of storage and networking. Having all of the compute in the world doesn’t mean diddlysquat if the storage can’t get data to the compute elements – whatever they might be – in a timely fashion with good sustained performance.
Many organizations that have invested in GPU accelerated servers are finding this out the hard way when their performance comes up short when they get down to do work training their neural networks, and this is particularly a problem if they have shelled out the $149,000 that Nvidia is charging for a DGX-1 appliance packed with eight “Volta” Tesla V100 GPU accelerators. You can’t let the flops go up the chimney with the smoke from the money you burned.
The problem is that the datasets that are needed for storing the largely unstructured data that feeds into neural networks to let them do their statistical magic is growing at an exponential rate, and so is the computational requirement to chew on that data. This is not precisely a causal relationship, but it is a convenient one and something that Jensen Huang, co-founder and chief executive officer at Nvidia, picked as one of his themes during the keynote at the GPU Technical Conference this week. “Over the next couple of years, it is going to be utterly incredible because we are just picking up steam,” Huang explained. “This is some new type of computing. The amount of data is growing exponentially, and there is evidence that with GPU computing, the computation is growing exponentially, and as a result, deep learning networks and AI models are growing in capability and effectiveness at a double exponential. That is one of the reasons why it is moving so fast.”
There is a lot of system architecture work that still needs to be done, including getting the right hardware underneath a fast-changing software stack that probably will not settle down for a few years yet. The software tuning is dramatic, as was demonstrated with some benchmarks that Nvidia showed off as part of its launch of the NVSwitch memory fabric switch, which is at the heart of the new DGX-2 AI supercomputing node that will be available in the third quarter. If you look at the Fairseq neural network training benchmark that Huang showed off comparing last year’s DGX-1 with eight Volta accelerators and the new DGX-2 with sixteen of them, you get a little bit more than 2X more performance from the scaling out of the underlying iron, and the remaining additional 8X in performance for training came from tweaks to the underlying PyTorch framework and various libraries such as NCCL from Nvidia, which distributes the workload across multiple GPUs, and the very high bandwidth interconnect between those Volta GPUs in the DGX-2 embodied in the NVSwitch. We don’t know how much of that 8X performance piece was due to the new memory fabric – we think it was the bulk of the improvement – and how much was due to software. But it illustrates the point that having fast hardware is only half the battle.
So do some benchmarks that Pure Storage, which peddles its FlashBlade all-flash arrays for unstructured data and which is seeing its use on the rise among both traditional HPC centers doing simulation and modeling as well as those organizations that are trying to do machine learning like the hyperscalers. Just like GPU computing is offloading the parallel processing embodied in both HPC and AI applications from the CPU, flash arrays are providing the kind of I/O performance that it would take a very large number of disk arrays to deliver. The combination of the two, with some sophisticated networking that supports the Remote Direct Memory Access (RDMA) capability that got its start with InfiniBand in the HPC arena two decades ago and that is now more common on Ethernet through the RDMA over Converged Ethernet (RoCE) protocol, is what Pure Storage considers a baseline hardware stack.

To that end, Pure Storage has put together its own AI hardware stack, called AI Ready Infrastructure, or AIRI for short, and is working with Nvidia and Arista Networks to put together the stack and sell it through selected channel partners that have expertise in machine learning. The company has also run some benchmarks on the AIRI stack to show that just weaving together hardware is not even close to sufficient to getting good performance out of machine learning training applications, and that companies adopting any framework to train neural networks have to get into the guts of the code and find the bottlenecks to get the most of that blazing fast compute, storage, and networking.
Suffice it to say, this is not a job that can be cheaply done, and certainly not on traditional web-scale or HPC systems with just CPUs and disk drives. But up until now, those building AI platforms have been largely doing it themselves, with a couple of academics with experience trying to cobble together whitebox servers or running these workloads on legacy systems. Even large enterprises that have expertise in traditional HPC are trying to figure out how to use GPUs and flash to architect better machine learning systems. The AIRI system, Matt Burr, general manager of the FlashBlade line, tells The Next Platform, has its origins with Zenuity, a partnership between car maker Volvo and auto safety systems maker Autoliv, that is working on self-driving cars.
When Zenuity got its hands on a DGX-1 to start doing machine learning training, it hooked the device up to a large disk array, and because the disk array could not pump in data fast enough, the GPU accelerators in the DGX-1 were idle 50 percent of the time when machine learning training runs were being done. Pure Storage was brought in during a bakeoff of ten vendors, and when it hooked up a FlashBlade array to the DGX-1, it could push data fast enough to keep the GPUs running at close to 100 percent of their computational capacity, but that FlashBlade was only consuming about 25 percent of the I/O bandwidth embodied in the flash inside its system.
So right there, you can see why the AIRI stack has four DGX-1 compute nodes and one FlashBlade array. The idea is to keep both the compute and storage elements busy all the time and waste no compute or I/O cycles.
On the hardware front, the AIRI stack has those four DGX-1V machines, which each have the Volta SXM2 Tesla accelerators, each with 16 GB of HBM2 stacked memory. The system has two 20-core Intel “Broadwell” Xeon E5-2698 v4 processors, which run at 2.2 GHz, 512 GB of 2.4 GHz DDR4 main memory (four times the base configuration) plus four 100 Gb/sec ConnectX-5 server adapters from Mellanox Technologies. For storage, the machine has a FlashBlade array with the full complement of 15 flash blades (hence the name of the product, which we analyzed here), each with 17 TB of capacity and presenting 179 TB of usable capacity before data reduction kicks in. The FlashBlade is running the Purity//FB file and object storage software layers atop the flash, and the DGX-1 machines make use of the integrated Ubuntu Server 16.04 operating system and GPU-aware Docker container environment and containerized machine learning containers that Nvidia stores out on the Nvidia GPU Cloud. To make scaling easier across the DGX-1 nodes, Pure Storage has taken the Horovod scale out software for machine learning frameworks, developed by Uber, which merges the Message Passing Interface (MPI) memory sharing protocol created decades ago in the HPC realm with the Nvidia collective communications library (NCCL), and made it easier to use and integrated it into the Purity environment as something called the AIRI Scaling Toolkit.
The whole shebang is linked together by a pair of DCS-7060CX2-325 switches from Arista, which each have 32 QSFP100 ports running at 100 Gb/sec. The eight links downlinking to the FlashBlade array runs at legacy 40 Gb/sec speeds without RDMA – something Pure Storage needs to tweak – while the four links that run to each server run at the full 100 Gb/sec speed and have RoCE turned on to reduce the latencies between the network storage and the compute complexes on the CPUs and GPUs.
Here is the central idea of the AIRI stack: The four Nvidia DGX-1 compute servers do the work of 40 racks of two-socket servers using middle of the line Xeon SP processors from Intel, and the FlashBlade has the I/O capability of ten racks of disk arrays. That’s 50 racks of compute and storage I/O jammed down into 50 inches of rack space, and the skinny configuration of the FlashBlade has enough capacity to be suitable for a lot of machine leaning workloads. (Zenuity actually went all in an configured its production FlashBlade with the 52 TB blades, boosting its usable capacity to 547 TB before data reduction techniques kick in. This is a lot more capacity than is possible with the new DGX-2, which tops out at 60 TB across sixteen peripheral slots in the single Xeon server node in the clustered system.
Pure Storage has, as we pointed out above, done a lot of work trying to figure out where the bottlenecks are in image recognition machine learning training workloads, and has done a bunch of tests with various frameworks in a synthetic data mode, which basically means giving the system blank fuzzy images with randomized pixels on them so the framework has no images to recognize but still goes through the motions of moving data through the layers of the neural network and back again. This gives a sense of peak theoretical performance of the hardware and software doing the image recognition training. Here is how the AIRI stack scaled as DGX-1 units are progressively turned on using the ResNet-50, Inception3, and VGG16 neural networks on the TensorFlow framework and against the ImageNet library of images.
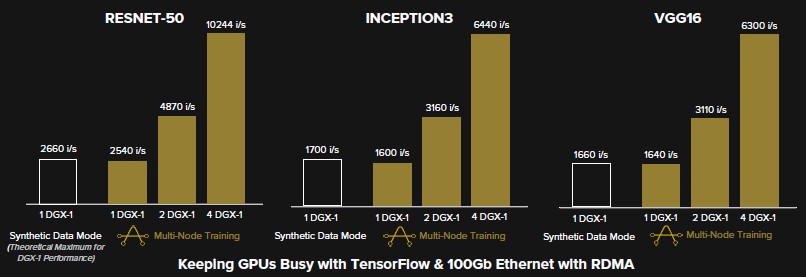
As you can see, the AIRI stack is showing pretty linear performance as DGX-1 nodes are added, and that the first DGX-1 node is getting pretty close to the peak theoretical performance. This performance level is a lot harder to attain than it looks, and Brian Gold, who worked at NASA many years ago on artificial intelligence relating to doing predictive analysis on control systems and then who left that field to work on flash storage, has come full circle back to AI by coming to Pure Storage and now doing performance analysis on flash arrays tat are supporting machine learning training workloads.
Gold started out his presentation talking about storage bottlenecks in machine learning stacks humorously by pointing out that papers written on machine learning do not take into account the very complex data ingest processes – whether they are working on image, video, text, voice, or other data – that have to be performed before the framework can start doing its statistical magic. They just fast forward to the part where the image is ready in a format that a neural network running on a framework can process. But this is a complex process, and to make his point, Gold showed this graph of the input pipeline on a ResNet image recognition neural network running atop the TensorFlow framework using the ImageNet database with 1.3 million images and 1,000 categories:
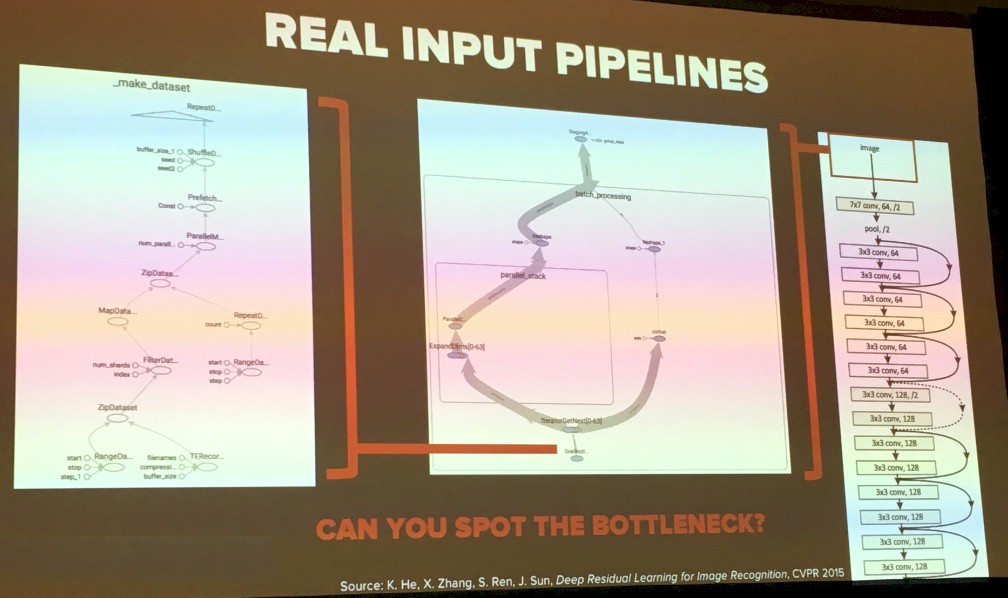
Gold jokingly asked the attendees of his session at GTC18 if they could spot the bottleneck in that image, and then conceded that actually he had no idea, based on simple inspection of the workflow, where it might be – which was precisely the point of the benchmarks that Gold has run and that were simplified for marketing purposes in the pretty slide higher up in the story. The issue is far more complex, and one that is important as datasets get larger, neural networks get larger and more complex, and the number of GPU accelerators in a system and the number of systems in a cluster both grow.
For those not familiar with the workflow in the data input pipeline, transforming images to tensors, there are five basic steps that have to be done. The first step is to enumerate the base files in an image library upon which external images will be compared, and organize them into a file structure by type or whatever method is appropriate. Once that is done, the labels for these categories are bound to the images themselves, and then the images are then shuffled to improve the accuracy of machine learning training because the images are scattered across types. This is all metadata. Then the images are read into the framework, they are cropped to a specific size, and – here is the important bit – they are intentionally distorted, by changing colors or rotating the image, to amplify the number of different images that are identified and thereby also improve the accuracy of the image recognition by the neural network. (This was a key innovation that made neural networks more accurate.) These files are created on the fly and are not generally stored on file systems because of the performance hit this would take and the capacity it would require. This is the work that the CPUs in the system do, and it is at this point that the labeled, cropped, and distorted images are loaded into the GPU memory to train the neural network. These are fed into the GPUs in batches and run back and forth as a group as epochs. While this example related to image preparation, the same basic input pipeline remains for other data types and other neural networks.
“What we have found is that any of these steps could end up being the bottleneck in machine learning training, and if you deploy large number of DGX-1s or other high performance GPU servers and you end up bottlenecked by storage or compute on the way to the GPU, you are not going to be very happy,” said Gold.
The tests that Pure Storage ran had Ubuntu Server 16.04 on the DGX-1 CPUs, and layered this up with CUDA 9.0 and NCCL 2.12 and then added CUDNN V7 and TensorFlow 1.4.0 on top of that. The work was spread across the nodes using OpenMPI 3.0 and the Horovod management layer, and the Datasets API for TensorFlow was used as the input pipeline to get the image data tensors into the GPUs for training.
To get a baseline, a training run was done on just one of the DGX-1 machines, and it was able to process 216 images per second. Using the synthetic data – meaning feeding it static on purpose just to see what the peak performance would be – the single DGX-1 machine was able to process 228 images per second. Pure Storage figured out that if it added a prefetch queue to the input pipeline, it could boost the performance to 225 images per second, which is within 5 percent of the peak theoretical performance using synthetic data. A 5 percent problem is not something people normally care all that much about, but when you scale out the workload across multiple server nodes, it becomes apparent why you need to care.
Gold scaled the benchmark across all four DGX-1 nodes, and immediately, there was a 42 percent gap between the 7,200 images per second that the machines could do in theory and the 4,143 images per second that the software stack did using the default settings; there was a slightly smaller gap of 37 percent between the 6,580 images per second it could do using synthetic data and that actual performance using the default settings on the software. This quantifies the overhead associated with the network in the scale-out scenario a bit. Adding that prefetch queue boosted performance to 5,335 images per second, which means it matters a lot more in the scale-out scenario than in the single-node case. Setting a thread pool limit so the CPU threads in those four server nodes were not oversubscribed help to increase the performance a bit more to 5,527 images per second.

Just for fun and to see what the overhead was for the distortion creation phase of the image preprocessing, Gold turned this off and the performance of the image recognition workload went up to 6,440 images per second, pretty close to the synthetic data performance but not a realistic configuration given that it would lower the accuracy of the image recognition. (You can do it faster, but it is also sloppier. Which stands to reason.) The point is, distorting the images is a performance bottleneck, and this definitely would not have been obvious looking at that flow chart above.
Gold’s advice to those building AI systems is to do their own tests, using both their machine learning workloads and standard benchmarks to stress test the systems to the max and to see where the bottlenecks could crop up.




Hi,
thanks for this very nice article.
Would be nice to post an update since DGX-2 was released !