

It might be a bit early to call generative adversarial networks (GANs) the next platform for AI evolution, but there is little doubt we will hear much more about this beefed up approach to deep learning over the next year and beyond.
Like so many other areas where GPUs have a play, much of the early production work is being done in graphics—image and video. This certainly means gaming, which is music to Nvidia’s ears. But as more research emerges, especially from the edges of medicine, it is becoming clear that GANs might be able to go several steps beyond mere recognition and actually generate examples, learn from those (through AI “arguments” between a generator and discriminator), and produce some surprising results.
There is much to be said about GANs from a future applications perspective, but this is one area where even the best general purpose hardware might not be up to the task at any kind of scale. And so far, we have not seen any AI chip startups focused exclusively on that, in part because it is not necessarily the compute, it’s the memory. More on that in a moment.
To put all of this in some context let’s look at one of the first production uses of GANs in biomedicine. Specifically, in drug discovery—a complex workload with a lot of moving parts and points of targeting and manipulating. At the center of this development is startup Insilico Medicine, which has a complex pipeline and distributed big compute to crunch genomic and other data types.
For anyone remotely interested in deep learning in life sciences, it is worth a visit to their publications page. We could detail some of the company’s most recent genomics and chemistry advanced, many of which are driven by deep learning, but for our purposes here at The Next Platform, we want to understand the infrastructure decisions that go into their next-generation research and development efforts.
For starters, some of their work is noteworthy purely from a deep learning framework perspective, namely, their use of GANs to both target key proteins and generate novel molecules for specific conditions. This feeds their decision making for hardware, guiding everything from on-site and cloud-based systems to specific accelerators.
As it turns out, there are quite a few such machines, some of which are quite powerful in terms of GPU counts. And while GPUs might dominate for several of their workflows, hardware experimentation is a priority, whether it is in with TPUs, FPGAs, neuromorphic architectures or its own custom-built systems that are DGX-like but with networking tailored to their own jobs.
So far we have been able to establish a good sense of what companies are buying for more traditional deep learning training workloads (GPUs and for those who can swing the price, DGX-1 or DGX-2 clusters in most cases), but the thing about GANs is that they put quite a bit more strain on systems. Even with all of those GPU cores, memory is a serious bottleneck for GAN training—something that has limited their use at any kind of scale outside of applications in image and video (the gaming environment generation work is the subject of a forthcoming piece since it is quite impressive for relatively little compute power).
In our conversation with Insilico Medicine’s Alex Zhavoronkov we talked through some of the benefits and drawbacks of GANs and how work within those confines in hardware. Specifically, we talked through some of the recent work using GANs for a full drug discovery pipeline and tried to fill in the systems side of the puzzle.
In a nutshell, Insilico uses GANs for both chemistry and biology to focus on end to end drug discovery. The goal is to identify the root causes and drivers of a range of diseases, which in their method, is handled by having GANs identify relevant protein targets before moving the workload into the molecular generation phase to link the appropriate molecules to those target proteins.
“We are solving two main problems in drug discovery with GANs,” Zhavoronkov explains. “The target is identified with GANs and a novel molecule is also generated this way. All of this is done quickly and at a super-human level because there are things we could not do previously, like generating novel molecular structures with specific sets of properties to see something that does not already exist in chemical space, whether synthesized or from the natural world.”
As grand as this all might sound, the GANs are the critical piece but they are not useful without direction. Zhavoronkov says that in order to be useful they have to be combined with reinforcement learning. “If you think of GANs as AI’s imagination, that is one thing, but without strategy, imagination is static. AI has to learn strategy and at the same, imagine things in a directed manner.”
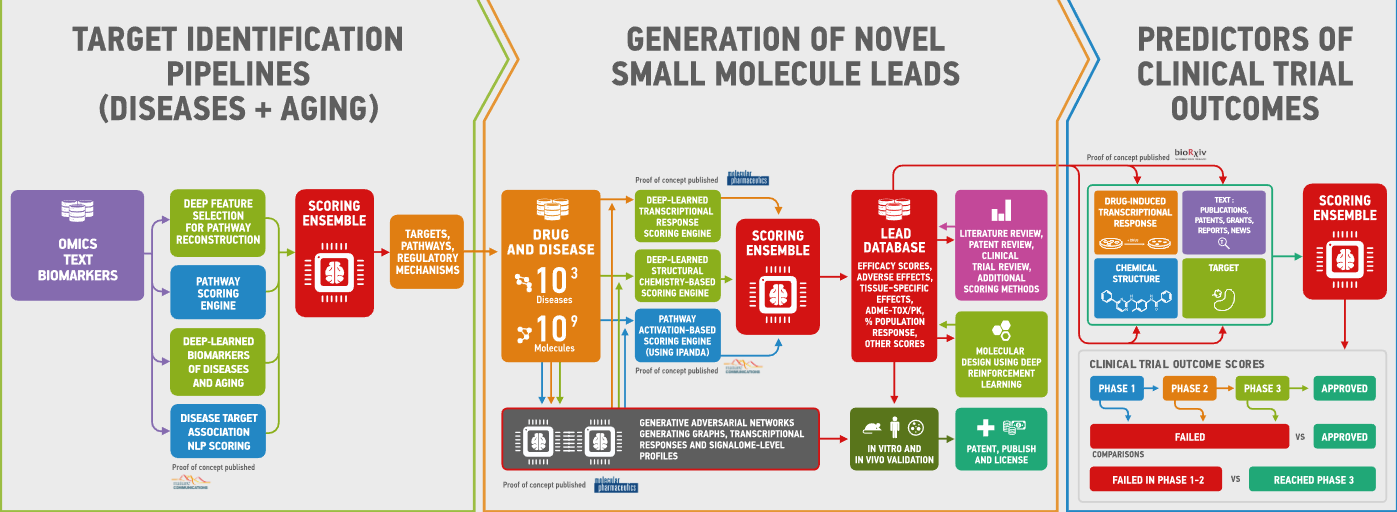
Because of the nature of training and the complexity of both the generator and discriminators, not to mention how these are paired with the reinforcement side of things, Insilico has had to invest big in deep learning hardware across its nine different sites. Because data transfer cannot be done internationally for sensitive data and because the double-digit terabyte datasets are not efficient to move to and from clouds, the company has its own fleet of clusters.
“We have our zoo of GPUs with several different generations—from Tesla V100s to K80s and down. We also have a couple of machines that are the equivalent of the DGX-2. Our largest GPU cluster is Taiwan,” he says, but we do not have a core or node count for that system.
One has to wonder why they would roll their own GPU clusters that function like the DGX-2. The systems they have built have four Volta GPUs per node (not clear how many nodes or interconnect) but eventually Zhavoronkov says they will invest in a couple DGX-2 machines since they have the networking and performance kinks down to a science. The company builds nearly all of its own libraries and much of the work is GPU native.
This might seem like a lock-in against other novel architectures to fit their application bill but Zhavoronkov explains that they are endlessly experimenting with hardware. Of course, this is all hardware that is easy to obtain—no novel architectures from the various AI chip startups that emerged over the last couple of years. However, he says that FPGAs have been used experimentally as have the TPUs from Google, but his teams can only use them for certain workloads since much of their truly mission-critical data cannot touch the cloud.
He also says for certain applications that are more personalized medicine focused or related to their many aging projects, neuromorphic hardware provides a promising angle but is not in production at this time.
He was not prepared to talk about the relative performance between cloud-based GPUs on AWS versus the Google TPU for machine learning workloads but he did note that there are always differences between those depending on workloads—sometimes dramatically in one direction or another based on the specific application. But as far as drawing comparisons about overall performance there was no word.
Zhavoronkov says that there are plenty of workloads at Insilico that do not need the massive compute horsepower of Volta GPUs but still need accelerators for the job. Here, cloud-based blockchain GPU companies have been useful. He says this with the disclaimer about the reputation of the entire blockchain ecosystem but says that for sheer power in numbers compute, these services with older generation or less powerful gaming-class GPUs fit the bill in a suitable price envelope.
“Some of our systems do not require a lot of GPU compute, like when working with medical imaging data, for example. Those are very heavy datasets, multimodal and noisy but for genomics and chemistry, nobody in their right mind would use a CPU.”
For a former medical researcher, Zhavoronkov has keen insight into the hardware and IT resources needed to do the heavy lifting of an emerging deep learning workload like the GAN/reinforcement combo his teams are working with. He says that they will continue to experiment with anything promising but for now in terms of availability and suitability, GPUs are still winning the AI hardware game. This is in part due to the fact that the same hardware paradigm can be applied across many generations of devices with varying price and performance points.
In terms of GANs, this will be a critical year, at least based on what we see from a fresh, big wave of new research that goes beyond more standard image and video use cases.
And in terms of GANs in a more mainstream sense, this will be one of those technologies that hits the news from time to time. Deepfakes and incredibly convincing images generated by machines are all part of this conversation. That’s not our domain to delve into, but it’s worth noting that there are security implications with the use of these networks. For instance, just recently researchers discovered how to create entirely unique fingerprints using GANs.
Just as with quantum computing and the looming threat of encryption invasions in the next decade, the threat is mitigated by the lack of real hardware for the job. Insilico had luck but for most companies, the massive training sets limit cloud use for GPU-driven training and the investment in on-site hardware is also a limitation. And even with that hardware, these neural network types need more memory—and they need a big pool of shared memory, which means getting a pricey DGX-2 or DGX-1 machine with the requisite NVswitch/NVlink and other communication protocols in place for fast communication and large reservoirs to store weights and such.
We expect GANs in security and intelligence as well as medicine will drive development of those algorithms—and push hardware makers for devices designed for the compute-intensive part of this workload.
But we can relax for now. It’s early days.
For deeper insight into the actual code, take a look at this example of how a GAN-driven autoencoder for drug discovery works or take a look at how it the company’s systems identify particular proteins in cancer and generate molecules that target these specifically in key cell types.

Intel Chip Research Pushes Power Efficiency And Performance
Since Pat Gelsinger’s return to Intel as chief executive officer in early 2021, the company has bet big on bolstering its manufacturing processes and foundry business, expanded its fab footprint in the United States, and advocated for expanding the country’s chip making capabilities. Intel’s success – or failure – in …

2021 Could Be the Year of Quantum Drug Discovery
While this new year might not mark the moment when the first drugs are discovered via molecular dynamics simulations running on a full-scale quantum, there are several signs that a number of important collaborations between the few quantum vendors and major biotech companies are announced. This means more internal labs …

How Multi-Scaled HPC-Enabled Genomics Will Help Save Your Life
A combination of Lenovo HPC and system optimization could help genomics detect and defuse healthcare timebombs Sponsored Feature The concept of precision medicine is revolutionizing healthcare by ‘personalizing’ treatment using genomics to provide insights into a patient’s genetic make-up gleaned from study of their own DNA. This subfield of bioinformatics …
Be the first to comment