

Here at The Next Platform, we tend to keep a close eye on how the major hyperscalers evolve their infrastructure to support massive scale and evermore complex workloads.
Not so long ago the core services were relatively standard transactions and operations, but with the addition of training and inferencing against complex deep learning models—something that requires a two-handed approach to hardware—the hyperscale hardware stack has had to quicken its step to keep pace with the new performance and efficiency demands of machine learning at scale.
While not innovating on the custom hardware side quite the same way as Google, Facebook has shared some notable progress in fine-tuning its own datacenters. From its unique split network backbone, neural network-based viz system, to large-scale upgrades to its server farms and its work honing GPU use, there is plenty to focus on infrastructure-wise. For us, one of the more prescient developments from Facebook is its own server designs which now serve over 2 billion accounts as of the end of 2017, specifically its latest GPU-packed Open Compute based approach.
The company’s “Big Basin” system unveiled at OCP Summit last year is a successor to the first generation “Big Sur” machine that the social media giant unveiled at the Neural Information Processing Systems conference in December 2015. As we noted at the release in a deep dive into the architecture, the Big Sur machine crammed eight of Nvidia’s Tesla M40 accelerators, which slide into PCI-Express 3.0 x16 slots and which has 12 GB of GDDR5 frame buffer memory for CUDA applications to play in, and two “Haswell” Xeon E5 processors into a fairly tall chassis. Since then, the design has been extended to support the latest Nvidia Volta V100 GPUs.
Facebook also claims that compared with Big Sur, the newer V100 Big Basin platform enables much better gains on performance per watt, benefiting from single-precision floating-point arithmetic per GPU “increasing from 7 teraflops to 15.7 teraflops, and high-bandwidth memory (HBM2) providing 900 GB/s bandwidth (3.1x of Big Sur).” The engineering team notes that half-precision was also doubled with this new architecture to further improve throughput.

“Big Basin can train models that are 30 percent larger because of the availability of greater arithmetic throughput and a memory increase from 12 GB to 16 GB. Distributed training is also enhanced with the high-bandwidth NVLink inter-GPU communication,” the team adds.
Facebook says the shift to “Big Basin” has led to a 300 percent improvement in throughput over Big Sur on ResNet-50 as one example and that while they are pleased with these results they are still evaluating new hardware designs and technologies.
For now, however, their machine learning infrastructure is comprised of standard CPU and GPUs only. While it is no surprise they have not taken the Google route to building their own custom ASICs for deep learning at scale given the differences in business objectives, it is safe to say that Facebook is sticking to its Nvidia and Intel guns for the time being as other hyperscalers look to diversify on the CPU front with AMD’s Epyc.
In a detailed description Facebook just released of their current hardware infrastructure, the social giant outlines how they support eight major compute and storage rack types that map to specific services.
“New services tend to get mapped to existing rack types until they rise to the level of warranting their own rack design,” infrastructure designers note, pointing to the example below of the 2U chassis that holds three slides with two different server types. One has a single socket CPU supported for the web tier, which is a throughput oriented stateless workload and can run efficiently on a lower power CPU like the Xeon D with lower memory and flash. The other sled option is a larger dual-socket CPU server with a beefier Broadwell or Skylake processor and far more DRAM to tackle more computationally and memory-heavy workloads.
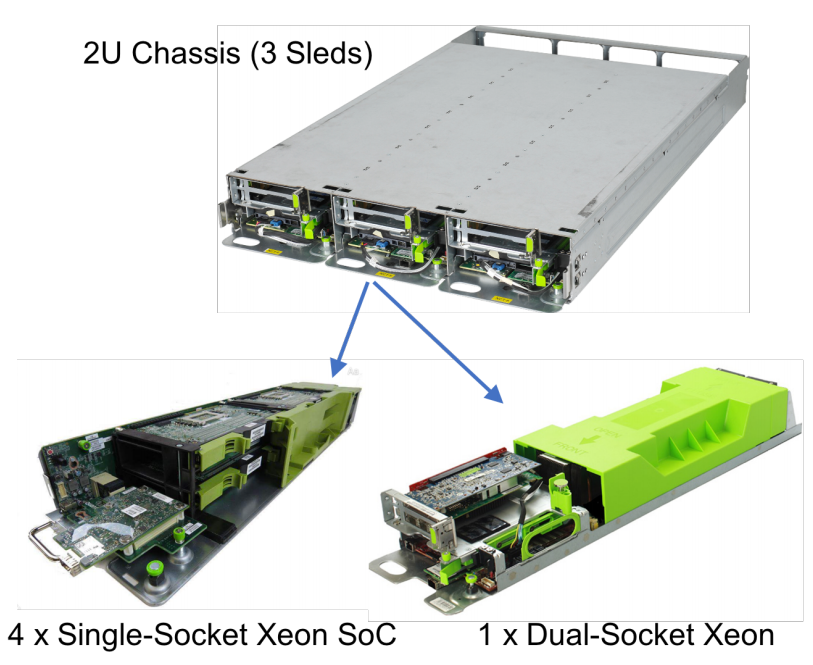
4 Monolake server cards, resulting in 12 total servers in a 2U form factor.
The dual-socket server sled contains one dual-socket server, resulting in three
dual-socket servers in a 2U chassis.
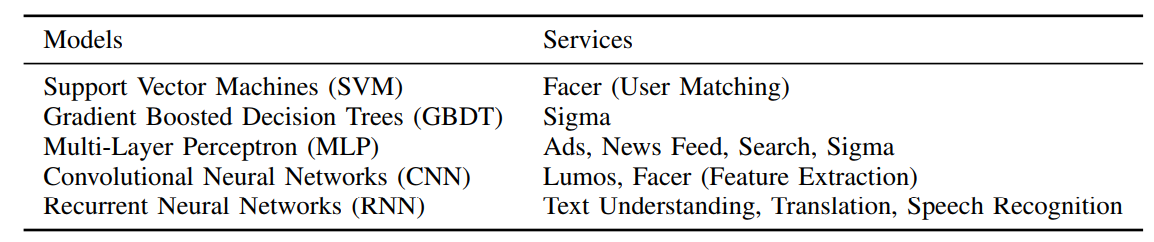
Beyond using machine learning in established services like search, news feeds, and ad delivery, Facebook has also implemented homegrown tools like Sigma, the general classification and anomaly detection framework for many backend operations including spam and fraud detection and overall security. The Lumos suite pulls image and content that machine learning algorithms interpret and pass on to improve services. Further, the company’s own face detection and recognition engine, Facer, is part of its larger machine learning infrastructure. The company has its own language translation and speech recognition tooling as well. Below is Facebook’s accounting of both the deep learning framework approach to each of these services and the corresponding hardware environments for training, inference, or both.
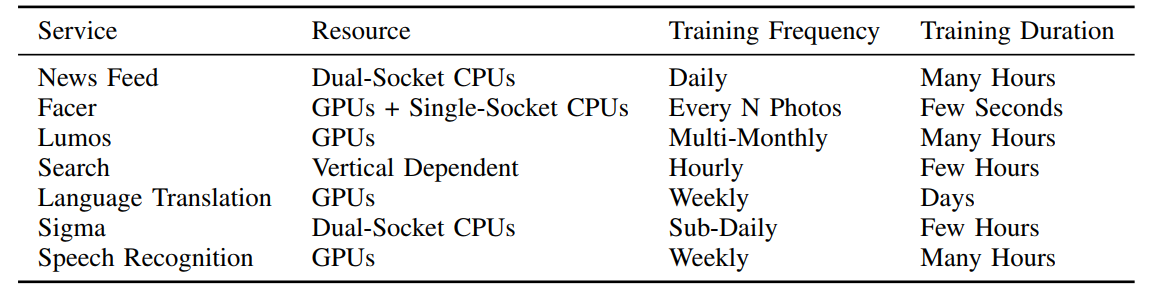
Facebook explains that currently, the primary use case of GPU machines is offline training, rather than serving real-time data to users. This flows logically given that most GPU architectures are optimized for throughput over latency. Meanwhile, the training process does heavily leverage data from large production stores, therefore for performance and bandwidth reasons, the GPUs need to be in production near the data accessed. The data leveraged by each model is growing quickly, so this locality to the data source (many of which are regional) is becoming more important over time.
“While many models can be trained on CPUs, training on GPUs often enables notable performance improvement over CPUs for certain use cases. These speedups offer faster iteration times, and the ability to explore more ideas. Therefore, the loss of GPUs would result in a net productivity loss for these engineers.”
“Training the models is done much less frequently than inference – the time scale varies, but it is generally on the order of days. Training also takes a relatively long time to complete – typically hours or days. Meanwhile, depending on the product, the online inference phase may be run tens-of trillions of times per day, and generally needs to be performed in real time. In some cases, particularly for recommendation systems, additional training is also performed online in a continuous manner.”
The full paper from Facebook can be accessed here.


Vertically Unchallenged
Components make compute and storage servers, and servers with application plane, control plane, and data plane software running atop them or alongside them make systems, and workflows across systems make platforms. The end state goal of any system architect is really creating a platform. If you don’t have an integrated …
The Perfect AI Storage: Trino From Facebook And Iceberg From Netflix?
When it comes to solving data analytics problems at scale, it is tough to beat the hyperscalers. And that is why a combination of technologies that were originally developed at Facebook (now Meta Platforms) and Netflix could end up being the perfect pairing to create a “lakehouse” underpinning AI training …
Meta Platforms Hacks CXL Memory Tier Into Linux
We have been excited about the possibilities of adding tiers of memory to systems, particularly persistent memories that are less expensive than DRAM but offer similar-enough performance and functionality to be useful. In particular, we have been strong advocates for disaggregating DRAM memory from the CPUs that make use of …
Be the first to comment