

Having a proliferation of server makes and models over a span of years in the datacenter is not a huge deal for most enterprises. They cope with the diversity because they support a diversity of application and can kind of keep things isolated and, moreover, IT may be integral to their product or service, but it is usually not the actual product or service that they sell.
Not so with hyperscalers and cloud builders. For them, the IT is the product, and keeping things as monolithic and consistent as possible lowers the cost of goods purchased through higher volumes and makes the support matrix less complicated and therefore support simpler and, relatively speaking, cheaper. It is interesting, therefore, to watch how hyperscalers and cloud builders are struggling with increasing diversity in compute and storage. We discussed this diversity with Google recently, and saw it in action again last week at the Open Compute Project Summit when Microsoft unveiled the Xeon, Opteron, and ARM variants of its “Project Olympus” machines. Facebook, which started the OCP six years ago, is also setting the pace in OCP iron, and it also unveiled its latest server refresh to the OCP faithful.
Both Microsoft and Facebook rolled out special server variants aimed specifically at accelerating machine learning workloads, and we will examine those separately. For now, let’s look at the more generic systems that Facebook has designed and contributed to the OCP so others can employ them or tweak to suit their purposes.
This time last year, we went over the then-current lineup of Facebook iron, which was comprised of six different configurations of systems based on its “Leopard” two-socket and “Yosemite” single-socket server sleds for Open Rack enclosures. These different configurations of the two basic servers are aimed at Web front ends, database, Hadoop data storage and analytics, Haystack object storage, cache-heavy New Feed, and cold storage portions of the Facebook application. (It really kind of is one big application, if you think about it.)
It is a year later, and Facebook has hit refresh on its server and storage iron with three new standard machines and another aimed specifically at machine learning workloads (the latter of which, as we said, we will cover separately because of the unique approaches that Facebook and Microsoft have taken to solve similar compute problems relating to machine learning).

The kicker to the Leopard platform is code-named “Tioga Pass,” and like Leopard it is a two-socket machine but one that sports more memory capacity and I/O bandwidth and therefore enabling more efficient use of the compute capacity in the box.
The Tioga Pass machine is based on Facebook’s fourth generation of motherboards based on Intel’s Xeon processors, the block diagram of which is shown below:
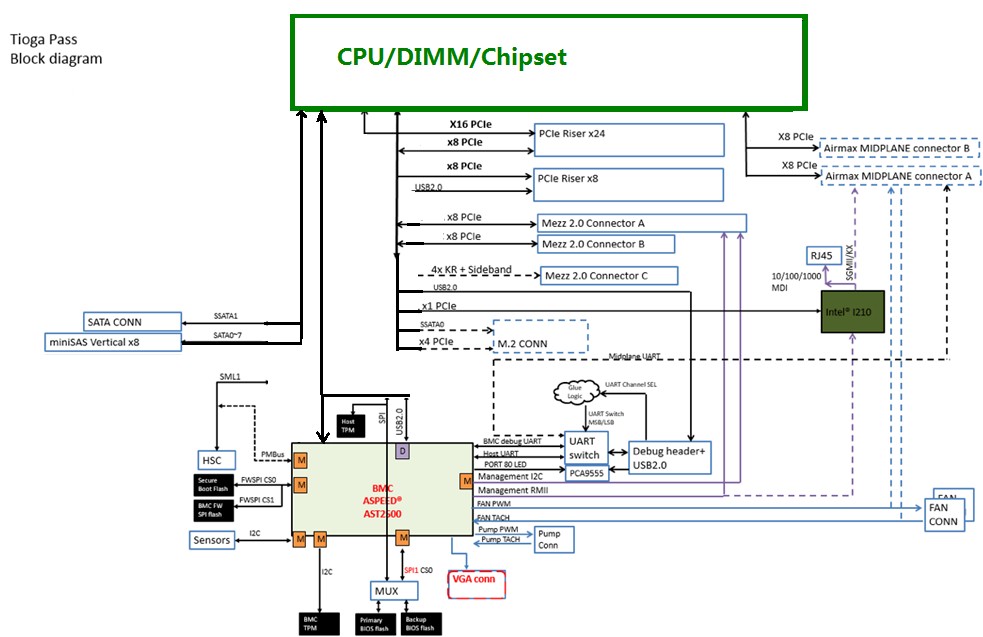
The Tioga Pass motherboard comes in the same form factor as the Leopard motherboard, which measured 6.5 inches by 20 inches, and it slides into the same Airmax midplane connectors that are used by Leopard servers. The Leopard and Tioga Pass machines allow Facebook to slide three servers into the Open Rack enclosure, side by side. The Tioga Pass motherboard is explicitly designed to make use of features of Intel’s future “Purley” server hardware platform, including its first instantiation with the “Skylake” Xeon processors due around the middle of this year or so. The Tioga Pass is a two-socket motherboard, but it is also designed to support a single-socket mode, presumably to allow Facebook to employ hotter and faster Skylake Xeons for selected workloads. If history is any guide, at least two generations of Intel processors will slot into the Tioga Pass machines, but we think Intel might try to stretch this to three give issues with the ramp of 14 nanometer and 10 nanometer processes for etching chips.
The Tioga Pass motherboard supports DDR4 memory on its 288-pin memory slots, and it comes in two flavors, with circuits soldered onto it on one side only or a two-sided variant that has more stuff. By printing on two sides, Facebook can use airflow over both sides to cool the components not try to jam it all on a one-sided motherboard. The double sided Tioga Pass board supports one socket and 12 memory slots on each side with two PCI-Express x16 slots on a riser card that plugs into a PCI-Express 2X slot that supports 32 lanes of I/O traffic. (The Tioga Pass document cleverly does not say if these are PCI-Express 3.0 slots or doubled up 4.0 slots, but the roadmaps we have seen show Skylakes supporting only PCI-Express 3.0 lanes.) The single-sided variant of the Tioga Pass board has one socket and 12 memory slots on one side of the board and has the option of either two PCI-Express x16 slots or one x16 and two x8 slots, allowing for variation in the peripheral links. The x16 slots are important for accelerators and certain I/O devices like flash cards, and the prior Leopard card had only a single x24 slot under the riser, which means it could not support two x16 slots on the riser options. Facebook says that these extra slots make it a good option to deploy the Tioga Pass server as the head node linking to its “Lightning” all-flash nodes and its “Big Basic” all-GPU nodes, neither of which have their own compute. The Tioga Pass board has an integrated 100 Gb/sec Ethernet network interface, which makes a fast pipe out to the Lightning flash arrays that debuted a year ago.
It looks like Facebook is deploying Skylake processors with two DIMMs per memory channel, which will run at 2.13 GHz and 2.4 GHz, but there is the option on the Skylake machines to support only one DIMM per channel that runs at 2.67 GHz.
Here’s another interesting tidbit: The Tioga Pass machines have to be able to support NVDIMM memory on each and every DDR4 memory slot. Also, the mSATA peripheral connector for linking to local flash devices has been replaced by an M.2 flash memory stick, a form factor that Microsoft has been using in its Open Cloud Server for three years now.
The Tioga Pass system makes use of the OpenBMC baseboard management controller that was initially created for the “Mono Lake” uniprocessor Xeon D node that debuted with the original “Yosemite” microserver design back in 2015.
Revisiting Yosemite Microservers
Speaking of microservers, Facebook has made a bunch of tweaks to the Yosemite platform, which is two years old now. The new Yosemite V2 chassis will still the older Mono Lake single-socket server, but also includes a new node called “Twin Lakes.” The new power subsystem in the Yosemite V2 enclosure and Twin Lakes server nodes allows for hot plugging of the nodes during service, which is a big plus. The Yosemite V2 enclosure has also been tweaked to allow four processor nodes (like the prior Mono Lake setup) but also allows for two processors and two accelerators (GPUs and FPGAs were mentioned) or flash cards to be put into an enclosure as well.
The device carrier cards are code-named “Glacier Point” for flash cards and “Carrier Flat” for other peripherals, if you are playing code-name bingo, and they max out at 75 watts of power draw. So you ain’t putting a 250 watt or 300 watt accelerator in there. Separately, however, in the Facebook documentation, it says that each server node or device carrier could support up to 192 watts of total power, with a combined maximum of 600 watts per Yosemite V2 sled.
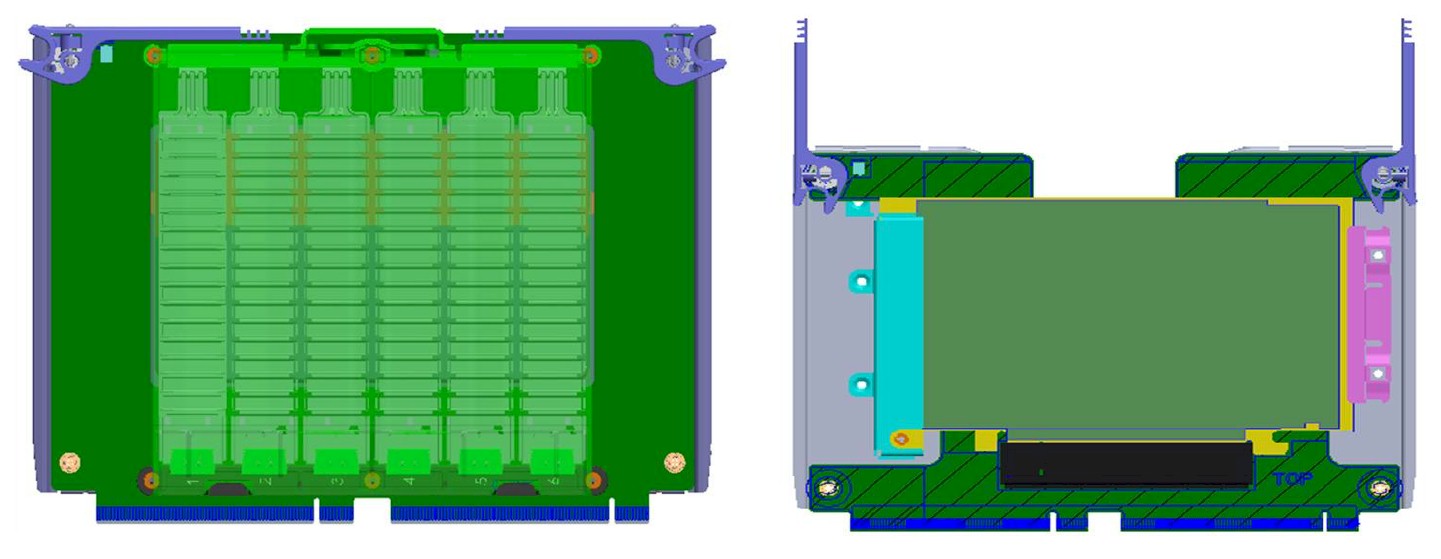
Each of the four Twin Lakes server nodes in the Yosemite V2 enclosure can link to a shared 50 Gb/sec or 100 Gb/sec multihost network interface card.
Here is a single sled of the Yosemite V2 with its Twin Lakes node sticking up:

And here is what the sleds look like all plugged into the Open Rack vCubby:

The new vCubby is four Open Rack units tall, which airs it out a bit and allows for more capacious and hotter devices to be slotted into the enclosure.
The Mono Lake and Twin Lakes nodes have integrated four-port network interface that runs at 10 Gb/sec to hook directly to the top of rack switch in the Open Rack if the 50 Gb/sec and 100 Gb/sec shared ports are not necessary. For those that do, a PCI-Express 3.0 x4 slot is used to link to the multihost controllers in the Yosemite V2 chassis; the Facebook-designed four-port controller is also an x4 mezzanine card, by the way.

A pair of PCI-Express x16 connectors are used to link the Mono Lake and Twin Lakes server nodes to the Yosemite V2 enclosures. The one thing that Facebook did not talk about is what processors are being used on the Twin Lakes nodes. But as Facebook has pointed out in the past, the Yosemite platform was created to support a wide variety of processors, and we would not be surprised to see a Qualcomm Centriq 2400 ARM processor and an AMD Naples Opteron as options alongside a Xeon D or Skylake Xeon E3 for compute.
Coming Hinged
Facebook created its own super-dense storage array, called “Knox,” way back when it built its first datacenter in Prineville, Oregon and opened up the design of that datacenter and the servers and storage in it six years ago. Knox was interesting in that it had two layers of 3.5-inch disk drives on a giant, hinged tray that folded up. The “Honey Badger” storage array follow-on added compute elements from its “Group Hug” microserver platform, which was never really deployed in volume and which was the predecessor to the Yosemite microserver from 2015.

It has been two years now, and Facebook is that much more dependent on video as a method of communication, and video is a lot fatter and finickier than static media, so it is time for a new storage platform. This one is called “Bryce Canyon,” and it offers 20 percent more hard disk drive count and four times the compute capacity of the Honey Badger variant of the Open Vault array.
Bryce Canyon looks surprisingly like storage servers from Supermicro, Dell, and Hewlett Packard Enterprise in its design – including not having a giant hinge between disk trays, which seemed pretty cool at the time but which is probably a pain in the neck to manufacture and use.

Bryce Canyon has room for 72 top-mounted 3.5-inch disk drives, which can be SATA devices supporting either 6 Gb/sec or 12 Gb/sec links. The storage array can be shared as a single 72-drive platform or partitioned into two 36-drive arrays. For compute, it uses the Xeon D-based Mono Lake card from the original Yosemite microserver platform, and depending on the load, it can have one or two of these compute cards installed.
Jason Adrian, a hardware engineer on Facebook’s Infrastructure team, explains: “We discovered that for certain workloads, such as web and storage, a single-socket architecture is more efficient and has higher performance per watt; we previously moved our web tier to utilize this architecture and have implemented the same Mono Lake building blocks in the Bryce Canyon platform.”

Drive connectivity for Bryce Canyon is provided in a number of different ways. The storage controller card (SCC) provides 6 Gb/sec and 12 Gb/sec SATA links to servers, and there is also an Input/Output Module (IOM) that has one of the OCP networking mezzanine cards as a front end, which in this case supports both 25 Gb/sec and 50 Gb/sec Ethernet NICs. The IOM has two different back-ends, including two PCI-Express 3.0 x4 M.2 ports or one 12 Gb/sec SAS controller. Facebook says that by populating different compute and I/O modules in Bryce Canyon, it can be configured in ways to optimize for various use cases such as JBOD, Hadoop, cold storage, and other scenarios. Bryce Canyon also makes use of the OpenBMC controller for management.
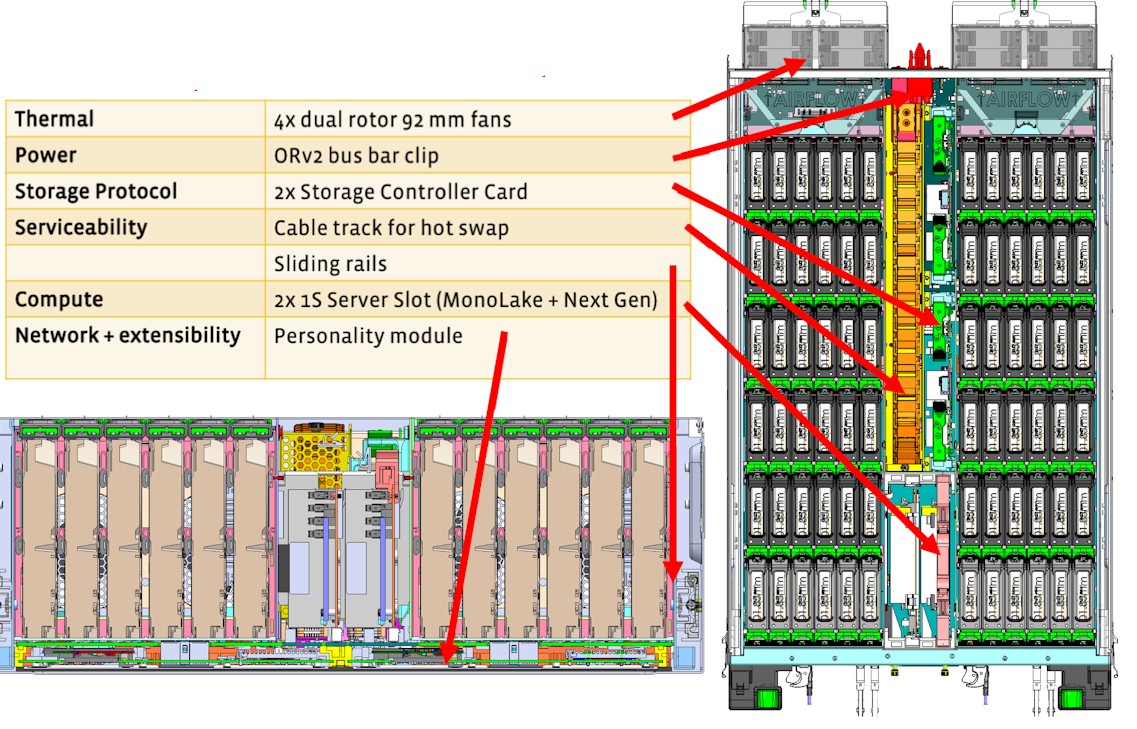
“Due to the modular design, future generations of the platform can adopt next-generation CPU modules to increase performance as new technologies arrive,” says Adrian. “If other input/output interfaces are needed, a new I/O module can be designed to meet the needs. With 16 lanes of PCIe going to the IOM, plenty of bandwidth is available to support a variety of possibilities. The system is designed to be protocol agnostic, so if an NVMe system is desired, the storage controller card can be swapped out for a PCIe switch-based solution. For a high-power configuration, such as the one used for our disaggregated storage service, Bryce Canyon is populated with two Mono Lake CPU modules to create two separate 36-drive storage servers within the same chassis. The I/O module used in this configuration supports two PCIe M.2 slots with four lanes of PCI-Express 3.0, in addition to the OCP mezzanine NIC. The M.2 slots can be leveraged for caching or small write coalescing.”


Will Open Compute Backing Drive SIOV Adoption?
Virtualization has been an engine of efficiency in the IT industry over the past two decades, decoupling workloads from the underlying hardware and thus allowing multiple workloads to be consolidated into a single physical system as well as moved around relatively easily with live migration of virtual machines. It is …

Inside Facebook’s Future Rack And Microserver Iron
The hyperscalers and cloud builders have been setting the pace for innovation in the server arena for the past decade or so, particularly and publicly since Facebook set up the Open Compute Project in April 2011 and ramping up as Microsoft joined up in early 2014 and basically created a …

Vertically Unchallenged
Components make compute and storage servers, and servers with application plane, control plane, and data plane software running atop them or alongside them make systems, and workflows across systems make platforms. The end state goal of any system architect is really creating a platform. If you don’t have an integrated …
Be the first to comment