

Distributed applications, whether they are containerized or not, have a lot of benefits when it comes to modularity and scale. But in a world of feature creep on all applications, whether they are internally facing ones running a business or hyperscale consumer applications like Google’s search engine or Facebook’s social media network, these distributed applications put a huge strain on the network.
This, more than any other factor, is why network costs are rising faster than any other aspect of the datacenter. Gone are the days when everything was done in three or four tiers, with a Web server like Apache, possibly front ended by a caching server like Memcached, and back-ended by a database like MySQL, Oracle, MySQL, or DB2. Applications are richer, and draw on many different applets running all over the place on clusters of servers, with all kinds of media – images, video, sound – interwoven with the applications. Any particular page of an application might have hundreds of different applets and pieces of data from all over the network that it calls, and you have 200 milliseconds to get it all done before end users get annoyed. This was easy – well, relatively easy – in a three tier network that often had Web and application servers on the same physical machine and database servers in the same racks as these machines. You just talked up and down the north-south axis between the database on the backend and the end user on the front end.
We live in the future, and it is a wonder that all of this hodge-podge works at all. It is a good thing that growth bandwidth is back on track, too. Right now, 10 Gb/sec out of the server is essentially free and 25 Gb/sec is now mainstream and affordable, with 50 Gb/sec and even 100 Gb/sec server ports available for those applications that are bandwidth hungry. Similarly, 100 Gb/sec Ethernet and InfiniBand are now mainstream, and stepping stones to 200 Gb/sec and 400 Gb/sec are in the works for top of rack and aggregation switches and for backbones that link datacenters and regions.
But bandwidth alone is not enough. At some point, the distributed nature of the applications and the operational aspects of running the IT organization overwhelm the network, leaving the pipes out to the end users clogged. Facebook hit that point quite a while ago, and about a year ago, as it was in the middle of its transition to homegrown 100 Gb/sec switching for its datacenters, it decided to do something about it. And the lessons that Facebook has learned will be relevant for any business that creates modular, distributed applications that have lots of east-west traffic between servers and storage within the datacenter and sometimes across datacenters and comparatively modest traffic out the north-south axis to end users.
The difference in traffic going east-west and north-south is dramatic, and the gap is growing at Facebook and very likely at any organization that builds applications like a hyperscaler. Take a look:
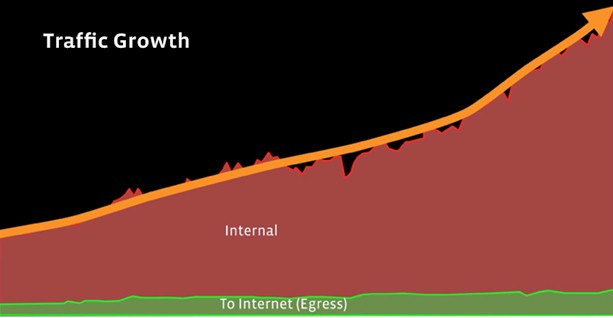
Back at the beginning of this dataset, which does not have precise years on it on purpose because Facebook is trying to obscure the time factor, the internal internet traffic was about five times as high as the traffic out to the Internet where the people sit on the Facebook backbone, which links datacenters and regions to each other and to points of presence and edge cache machines much as other networks link gear together within a datacenter. By the end of this period of data, the east-west traffic across the backbone had tipped up into an exponential curve and was about ten times as great as the traffic out to the Internet across the backbone.
Over the past decade, this backbone – now called the Classic Backbone or CBB for short – has move from 1 Gb/sec through to 10 Gb/sec to 40 Gb/sec and a year and a half ago was upgraded to 100 Gb/sec, so this is not just a bandwidth issue, Omar Baldonado, manager of the network team at the social network, tells The Next Platform.
“East-west traffic is growing hugely, and we wind up having to be very careful about what leaves a datacenter or region,” explains Baldonado. “Within a datacenter, you want to have as much fast connectivity as you can, but it is a different consideration when you start going between datacenters, even if you have all of the bandwidth you want, it is across the oceans potentially and latency is an issue. You can make as big of a lane as you want, but it will take a while to get it. So we try to be as efficient as possible with what goes across the backbone between regions. The new Express Backbone allows us to do global traffic engineering and have better control over how we move around photo and video backups and how we move all of the Hadoop namespaces between the different datacenters.” The rise of machine learning is also putting a strain on the Facebook network because training algorithms means moving datasets across the backbone from different regions, and this tends to be bursty and therefore can affect the running of the actual Facebook application both internally where pages are composed and as it faces the outside world.
In other words, it was not just a simple task of segmenting the network, which hyperscalers are loathe to do because they always want the biggest single thing, all homogenized, they can get because this generally scales more cheaply. (Right up to the point where it doesn’t, of course.) It is also not as simple as having two networks that can be independently upgraded, but this is also a plus.
The new Express Backbone, which has been rolled out in the past year, is used to manage all of that east-west traffic between datacenters and regions on the Facebook network and to the many points of presence where it caches pages worldwide, has two salient features. The first is a new centralized traffic controller and the second is a distributed routing platform called Open/R, which was a routing system originally created for its Terragraph multi-node wireless network aimed at providing Internet coverage in urban areas thick with wireless hotspots. Facebook could have just split its backbone, but remember the goal is not just to segment traffic but to do a better job managing the backbone traffic and do a better job of managing the massive backups from the Haystack object storage where all of those photos and videos live to cold storage and all of the namespaces updates on its massive distributed Hadoop data muncher.
The Classic Backbone was based on a number of protocols, including the ill-named Intermediate System to System (ISIS), Multi Protocol Label Switching (MPLS), and Resource Reservation Protocol – Traffic Engineering (RSVP-TE) with Auto-Bandwidth. All of these, says Baldonado, were fairly complex to use and did not give Facebook the control that it needed. And so, by engineering Express Backbone, Facebook was looking to simplify the protocol mumbo jumbo and get more control because the company stresses operational control over feature creep – something you have to do as a hyperscaler. In fact, hyperscalers prune out unneeded hardware and software wherever they can, and this is wise at any scale, to be honest, but critical when you have hundreds of thousands to millions of anything.
The initial iteration of the Express Backbone was built using the Interior Gateway Protocol (IGP) with an Internal Border Gateway Protocol (iBGP) topology for implementing the packet routing across the backbone. This was a static topology, but Facebook wanted something a bit more dynamic and also to add a central controller and a traffic matrix estimator, and so it pulled out IGP and dropped in a modified version of Open/R. Here is what the Express Backbone topology looks like:
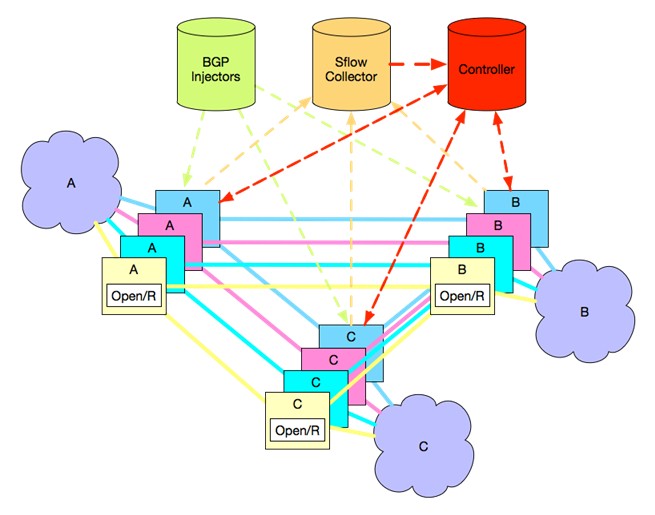
The neat thing about Express Backbone is that it has distributed control agents and a central controller, which allows Facebook to exercise top-down traffic shaping across the WAN while at the same time allowing a certain amount of intelligence in the Express Backbone’s distributed control plane to allow for parts of the network that have congestion to deal with it as it is happening, where it is happening. The Open/R agents are what tell the controller what the live state is of the network, and when an element of the network fails, traffic is routed around that dead gear by the Open/R agents.
The central controller needs to know what the totality of traffic is at any given time, and that is what the traffic matrix estimator part of the Express Backbone stack does. Each device kicks out an sFlow snippet of current traffic into and out of that device, and this data is collected and sent back to the controller. Label Switch Path (LSP) agents take the MPLS segment routes created by the controllers and update the forwarding tables in the network devices. Here is how the Express Backbone controller is architected:

If you want the nitty gritty of how this all plugs together, check out this blog post. The issue that Facebook ran into initially was keeping the state of the network consistent and stable, and this is always the issue with any kind of distributed control. (Google has had similar issues with its Borg and Omega cluster controllers, for instance, as well as with its own B4 WAN backbone.) In the future, Facebook is looking to add a bandwidth allocation scheme to the stack that would allow it to pin a specific network bandwidth and quality of service between the network and that service. The company is also working on a job scheduler for large batch transfers across the new backbone, allowing for transfers that can wait to wait rather than competing for network capacity with jobs that can’t wait.
The obvious question, given how much traffic is on the Express Backbone, which took a year to develop and implement, and how little is now on the old Classic Backbone, is whether Facebook will further segment its network. Maybe Hadoop clusters should have their own backbone?
“Never say never, but what we are finding is that this split between internal and external traffic gives us the break we need, and then Express Backbone allows us to do partitioning of traffic within it,” says Baldonado.
It would be interesting of Facebook opened up all of the Express Backbone stack so others could use it, but thus far, it is only open sourcing the Open/R protocol. It is unclear when and if the tweaks it made to put it at the heart of Express Backbone will be put out. The main thing is that Facebook has shown that it can be done, and now others can emulate it.


The Iron That Will Drive AI At Meta Platforms
If there is one thing that is consistently true about HPC clusters for the past thirty years and for AI training systems for the past decade, it is as workloads grow, the network becomes increasingly important – and perhaps as important as packing as much flops in a node as …

Presto Is The Third Time Charm For Federated Databases
Users of relational database management systems are accustomed to sub-second response for relatively simple online transaction processing, and have been able to enjoy those zippy responses for decades. The big caveat there is relatively simple transactions – looking up data or processing an order – and against fairly modest databases …

The Once And Future Federated Database
There are many different schools of thought when it comes to databases, which is one of the reasons that we launch our inaugural event focused solely on database technologies this year. But if you had to sum it up, it would look a bit like the following. After deploying a …
Be the first to comment