

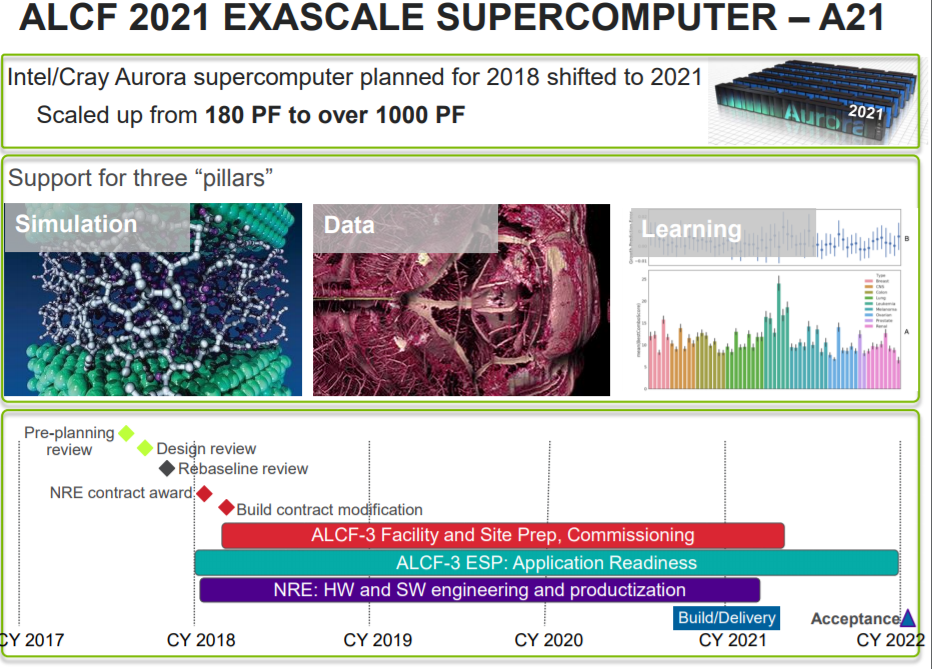
This morning a presentation filtered from the Department of Energy’s Office of Science showing the roadmap to exascale with a 2021 machine at Argonne National Lab.
This is the Aurora machine, which had an uncertain future this year when its budgetary and other details were thrown into question. We understood the deal was being restructured and indeed it has been. The system was originally slated to appear in 2018 with 180 petaflops of peak performance at double precision floating point. Now it is 1,000 petaflops, an exascale capable machine, and will be delivered in 2021—right on target with the projected revised plans for exascale released earlier this year.
When the system’s future was up for debate, some suspected an shift in architectural direction to meet shifting workload needs in HPC—or, as more pessimistic members of the HPC community speculated, to get away from unanticipated ultra-high costs with key vendors. HPE’s The Machine was touted as being a potential replacement for the Cray and Intel partnership but it appears the same vendors on the hook to deliver the system.
Intel and Cray, as we have written before, were originally set to deliver the Cray “Shasta” system with the forthcoming Knights Hill processor in 2018. While we expect Knights Hill to emerge on schedule (we got an in-depth on the status of Knights Mill, a related chip, at Hot Chips in August, but Intel has not said much about Knights Hill), this architecture will very likely be some post-KNH chip. This means high computing potential, but also high power consumption–something important to stay within a 20 megawatt to 40 megawatt boundary.
Our several sources today confirm that this machine is not based on Knights Hill and that, whatever it uses for compute represents a big step in performance. It also comes with a big risk. Considering the DoE is going to invest in a completely new, unseen architecture at this scale to be the first exascale system in the United States is its own risk. The secondary risk is bumping ahead the timeline of exascale delivery from 2023 to 2021.
This future Argonne exascale system very likely does not mean a tweak to the Knights family that puts a more modest number of X86 cores – say, one or two dozen – with super-wide vectors and maybe tons of MCDRAM3 memory and maybe 400 Gb/sec Omni-Path 3 interconnects on the die or in the package. We got the distinct impression from Intel several years ago that it was interested in getting the memory capacity and memory bandwidth back in line with the compute capacity and network connectivity compared to the “Knights Landing” Xeon Phi, which has 72 cores, a pair of 512-bit vectors in each core, a modest amount of MCDRAM1 memory, and on-package 100 Gb/sec Omni-Path 1 interconnects.
Interestingly, the innovation with the Argonne exascale machine may come more in the vector unit, not the X86 core. With a mesh architecture, Intel could even go so far as break the CPU core free from the vector units, creating what comes to an offload model on the die — one that is insulated from the compiler and doesn’t require something like Nvidia’s CUDA development framework to operate.
One other tidbit we gleaned from casual conversations is that the forthcoming architecture is less like a novel approach (quantum, neuromorphic), not accelerated (as in with an offload model from a discrete CPU to a discrete GPU or FPGA), but of a “reimagined” way of designing chips. We are not sure if that means a familiar X86 ISA, but would assume it would be a requirement for productivity. We have also heard that there is an interest in reducing the node count on this future Argonne machine, making it look less like IBM’s BlueGene/Q, which had a large number of modestly powered nodes. The original Aurora machine was set to have around 50,000 nodes to reach its 180 petaflops, which suggests an average of 3.6 teraflops per node. That was not much more powerful than the current top-end Xeon Phi 7290, which does 3.46 teraflops at double precision on 72 cores running at 1.5 GHz and a pair of 512-bit vectors per core. Say that Knights Hill had double the vectors in half the cores but 50,000 sockets to reach that 180 petaflops in the original Aurora, and added in mixed precision down to 16-bit vectors just for fun. It would take 250,000 nodes to kiss exascale with this chip, and breaking the chip apart more would increase the node count and reduce the performance per node unless the vector width was increased radically.
Intel could be going the other way, creating a massive compute complex, perhaps with 3D stacking of compute and memory, with a huge number of cores and very wide vectors in each unit, and many Omni-Path links into this gigantic chip. This would be the only way to reduce the node count, as we are hearing it is trying to do.
We will follow up as we are able to secure interviews and provide much more detail.

Cores, Clocks, And Caches Cranked With Latest NEC Vector Engines
Whenever a process shrink is available to chip designers, there are several different levers they can pull to make a more powerful compute engine. With the latest “Aurora” Vector Engine accelerators from NEC, long-time supercomputer maker NEC is pulling on a bunch of levers at the same time – and …

Intel Aims For Zettaflops By 2027, Pushes Aurora Above 2 Exaflops
Just because Intel is no longer interested in being a prime contractor on the largest supercomputing deals in the United States and Europe — China and Japan are drawing their own roadmaps and building their own architectures — does not mean that Intel does not have aspirations in HPC and …

Argonne Aurora A21: All’s Well That Ends Better
When it comes to a lot of high performance computing systems we have seen over the decades, we are fond of saying that the hardware is the easy part. This is not universally true, and it certainly has not been true for the “Aurora” supercomputer at Argonne National Laboratory, the …
From the sound of it, this could become a famous or an infamous system. I look forward to reading the details.
“…Knights Hill…(we got an in-depth on its status at Hot Chips this year)…”
The Hot Chips talk was titled, “Knights Mill: Intel Xeon Phi Processor for Machine Learning.” See “Conf Day 1” on https://www.hotchips.org/archives/2010s/public-hc29/.