
The more things change, the more they stay the same.
While exascale supercomputers mark a next step in performance capability, at the broader architectural level, the innovations that go into such machines will be the result of incremental improvements to the same components that have existed on HPC systems for several years.
In large-scale supercomputing, many performance trends have jacked up capability and capacity—but the bottlenecks have not changed since the dawn of computing as we know it. Memory latency and memory bandwidth remain the gating factors to how fast, efficiently, and reliably big sites can run—and there is still nothing that will tip that scale significantly on the horizon, says Gary Grider, deputy division leader for HPC and Los Alamos National Laboratory.
“Because we know change can only happen at a certain pace, it forces everything else about the decisions we have to make. It forces the size of the machine, how often the system fails, and those thing force the I/O and storage system to be a certain size and capability. We’ve been driven by these same constraints for almost seventy years in computing and will continue to be for the foreseeable future,” Grider explains, pointing to the current generation of pre-exascale supercomputers as a continuation of this same game of push-the-bottleneck.
As he notes, much of the game of catch-up for imbalanced systems in terms of data movement can be played at the storage and I/O layer—an area where Grider has pushed for innovation with the creation of the burst buffer concept among other file system and object storage ideas. With Los Alamos looking ahead to next generation systems to fit the exascale bill (likely sometime between 2022-2025), we wanted to understand how the storage and data movement elements of the exascale might look like paired with the existing timeline for general exascale computing capabilities as seen below.
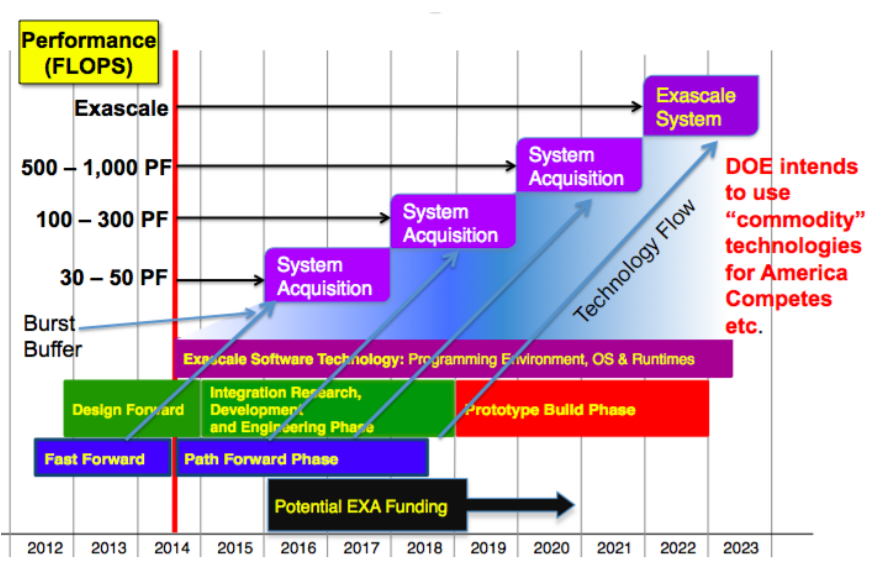
The above timeline clearly marks out various funding initiatives, but the story that is not clear is how the economics of the storage and I/O layers play out. Unlike with CPUs, accelerators, and broader integration, the market forces at play for large-scale capacity and high performance tiers are worth their own rough timeline.
“The question is how many tiers do you want to have and how long will you have them—and that answer is driven purely by economics,” Grider says. “We went with flash and burst buffers on Trinity because the bandwidth got faster than the disks could from an economic standpoint. We probably won’t even have a scratch file system by 2022—we will be entirely flash. The only disks will be for capacity, which is what the concept of campaign storage is all about.”
It is not clear that there will be anything better than flash until the economics begins to make sense for us, Grider explains, noting that such a transition would start small like the burst buffer work and then gradually take over other tiers. Such a move, at the high end of computing anyway, would force the flash providers to after the capacity tier—and that invokes another story about how long can any storage technology have the high margin before it is replaced. If flash ever moves off the top and needs to move into the capacity tier, the question is how many fabs will need to be built to start allowing flash to tackle disk for that capacity as well (and would the margins even be sufficient?).
“We are still in the process of doing economic analysis to figure this out, but we project that by 2020—and definitely before 2025 the largest machines will have moved to an entirely flash-based scratch file system inside the machine.” This means no more external racks full of disks running a parallel file system. Instead there will be some storage system software running but that file system functionality will be completely inside the machine as flash. In the tier below that will be a campaign storage tier (versus parallel file system) that looks a lot like cloud-based object storage in concept.
“These machines are going to get so big and unwieldy with so many nodes that even an in-system flash parallel file system or similar functionality won’t be fast enough. By this time, we are going to need to do things like checkpoint every minute versus every twenty minutes,” Grider says. As the slide he presented last week at the Flash Memory Summit shows, there are numerous other pressures resting on innovations at the storage and I/O layers at exascale.

These considerations are not only relevant for the largest simulation supercomputers, either. Machine learning, graph analytics, and other areas are going to face similar requirements to keep pushing more data to the processor at higher rates.
By 2023-2027 then, the expectation is that something will come along to displace flash and push it into that far lower-margin capacity tier. This could be something like ReRAM or 3DXpoint—whatever it is, it will take a long time to arrive. It takes many years for companies like Samsung, Micron, and others to get to a new device and create enough margin to invest in fabs to create enough bits of flash tech to challenge the disk manufacturers that will likely still be hanging to the slim bits of the capacity tier. Grider says he can see a day in the coming years where the diskmakers hold the position that tape does today—a niche capacity layer for key markets with specific needs. “It used to be 20 years for cycles to change, it’s more like ten now,” Grider adds.
There is always some margin to be gained when there is just a bit more functionality than what is just above you. Flash has that over disk because the bandwidth and agility but the durability is a weak spot. Of course, when going to the capacity tier, durability isn’t the issue, but the minute those margins start to drop, flash ends up where disk is today. Grider things within 5-6 years the woes of the flash market will look a lot like disk does today. And so, where might that leave us?
“The users themselves may end up being the manufacturers to squeeze whatever little bit of margin is there,” Grider says. “The Google, Microsoft, Facebook companies could eventually own a fairly major piece of the making of these devices and keep squeezing out margin where others can’t or won’t.”
This is not so far-fetched based on what we’ve seen with the big hyperscalers and their motherboards in the last couple of years, but where does that leave the market?
Such a shift could cut down on the incentive for smaller companies to enter the market and take the risk, and it could also mean that large research centers will have to approach the webscale giants to get massive scale computing done. This could especially be the case if budget woes persist into the 2020s and after the first wave of exascale machines come online.


Peeling The Covers Off Germany’s Exascale “Jupiter” Supercomputer
The newest of the exascale-class supercomputer to be profiled in the Top500 rankings in the June list is the long-awaited “Jupiter” system at Forschungszentrum Jülich facility in Germany. We finally have a sense of how this hybrid CPU-GPU machine will perform, although some of the details on its configuration are …

China’s Exascale Quantum Simulation Not All It Appears
And actually, one could say it is also far more than it appears. Three years ago, a team from Oak Ridge National Laboratory (ORNL), Google, and NASA Ames published a paper showing the first glimmer of quantum supremacy. For those who don’t follow quantum computing, in a nutshell this means …

The Nitty Gritty Of The Sunway Exascale System Network And Storage
We took a look recently at the compute engines at the heart of the future – and as yet unnanmed – Sunway exascale system that will be installed at the National Supercomputing Center in Wuxi, China. This exascale machine will be a follow-on to the current Sunway TaihuLight system, both …
Be the first to comment