

Last week, in an article on the pending death of the parallel file system, a note was made about an effort out of Los Alamos National Lab (LANL) called MarFS, which will serve as the intermediary solution to allow very large centers to take advantage of cloud-style object storage using a more familiar POSIX approach. In that piece, we talked about storage hardware evolution to frame the concept, but the other piece, MarFS, is the stepping stone to that eventual parallel file system death.
The goal of MarFS, which has been in development for over two years at LANL under the watch of the lab’s chief storage architect, Gary Grider, is to allow the use of off-the-shelf cloudy object stores (and all the economic benefits those provide) by putting a namespace over it so it behaves like POSIX, at least from the user point of view.
The driver for much of this development has been the upcoming “Trinity” supercomputer, a $174 million Cray-built system that will be optimized for nuclear stockpile simulations and other energy research. As Grider and the LANL team looked at the capabilities against their projected workloads, which matched 2 to 3 petabytes of main memory with single job sizes in the one petabyte range, along with the need to keep the data around for the entire duration of the simulation (generally years) it was clear that existing approaches to parallel file systems were going to be stretched. As they looked closer, the idea of using RAID-based approaches wasn’t effective either since teams needed erasure, hence MarFS was born to serve as what is best defined as a “data lake” (something we’ve been hearing about in large-scale analytics circles more than from pre-exascale supercomputing sites).
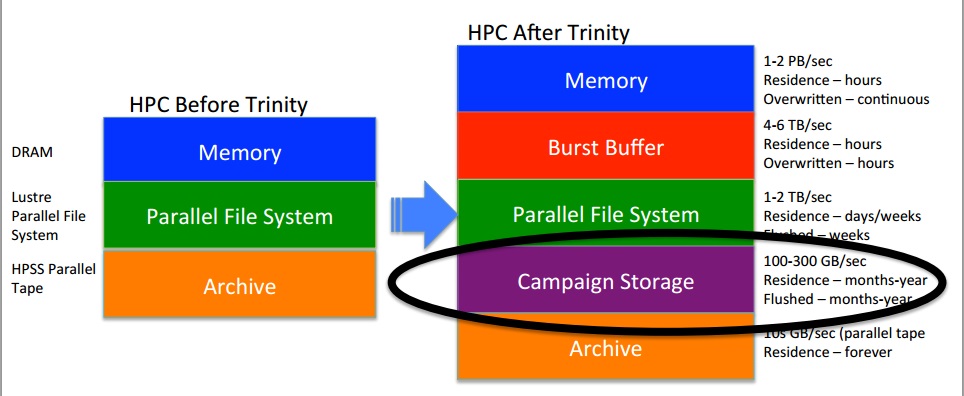
The solution of using highly erasured cloud-style objects against cheap disk technology and software defined storage made more enterprise object storage efforts from Cleversafe, Scality, and OpenStack Swift attractive, but the namespace over these was designed more to suit the needs of web-native companies versus users with a rich POSIX environment and a lot data. The goal was to use MarFS to put a namespace over cloud-style objects and use that as the capacity tier.
“There are many challenges to provide this capability, including the mismatch of POSIX and object metadata, security, update in place semantics, and efficient object sizes. Further, the need in HPC comes with billions of files in a single directory and single files that are even zettabytes in size, so scale is a huge factor.”
As Grider tells The Next Platform, the need for something that provides a POSIX approach to more economical cloud-style object stores became clear a year ago during a storage conference where the few major object storage vendors sat on a panel and answered questions from audience members, including United Healthcare, who said they understood the benefits and savings of object storage as a new approach but were tool tied to POSIX to make the transition without a major rewrite of legacy applications. It is in this area that MarFS might gain larger ground—and possibly even find some commercial support and footing. “Companies with a lot of data that have been around for a long time are locked out of using a Scality, for example, because it would be too difficult to just decide to this overnight.”
With MarFS as an open source project, the possibility to use this as an intermediary solution to get the economic benefits of cloud-style storage approaches without sacrificing the POSIX approach entirely, one might expect broader interest. Grider says there are a number of companies looking at it already, particularly at long-standing companies with vast wells of data (oil and gas is one of the best examples) and that as it rolls into production this month and LANL shares details about how it functions in practice, interest will increase.
“For companies with a billion dollars of POSIX, there’s no way to rewrite quickly. There are users out there who want to use cloud-style object storage because it would save an incredible amount of money, including all they fork over to the RAID vendors when in some cases, they don’t even need the performance the RAID vendors provide,” Grider explains. “There is a need to use colder storage but they can’t just use the object stuff the namespace doesn’t exist over it, the access method is wrong, and their applications aren’t written to do that—they’re written to make folders and change the ownership of folders and share things with POSIX mechanisms.” The problem with existing object storage approaches, however, is that when coming from a national lab supercomputer perspective, they aren’t designed to scale in the same way, which is the workaround MarFS offers.
Although MarFS is open source, it is not to the only effort that is reaching toward the same end. For example, this is one of the capabilities EMC now has with its recent acquisition, Maginetics, with a few other smaller players trying to do the same. However, seeing MarFS in production at extreme scale—and against some challenging data sizes and retention limits will be interesting.
Ultimately, Grider says that as 3D NAND and other technologies become cheaper and more ubiquitous, what we think of as a very fast scratch file system that’s already close to the machine (but capable of going beyond the basic burst buffer capabilities of today) will move inside the machine in the 2022-2023 exascale timeframe.
After it goes into production this month, Grider’s team will do a demo showing something around a trillion files in a file system and a billion in a directory using MarFS. While that will be noteworthy, watching how it operates as the capacity tier for a large DoE supercomputer might be the best of all tales to tell about the future of storage at HPC scale with a parallel file system, coupled with a burst buffer, all of which will merge into one tier when the next generation of systems hits after 2020.

Los Alamos Taps Seagate To Put Compute On Spinning Rust
High performance computing workloads simulating all manner of things can produce a veritable mountain of data that has to be sifted through. In fact, that is what makes HPC the opposite of AI: You take a small amount of data and explode it into a massive simulation. AI takes a …

Squeezing Every Drop Of Value Out Of Data
To Patricia Harris – like most people in the rapidly changing worlds of IT and business – data is central to what she does. Data is what is driving innovation and business decisions, accelerating the development of products and services that quickly are finding their way into the hands of …

Intel Targets DAOS Object Storage At More Than HPC
Intel is looking to position itself as a leader in AI and HPC through a holistic approach that plays to the company’s strengths across a broad swath of the IT ecosystem. This covers not just silicon hardware such as CPUs and ASICs, but also the firm’s expertise in open software …
Be the first to comment