

Burst buffers are a hot topic these days. At the most simple level, a burst buffer consists of the combination of rapidly accessed persistent memory with its own processing power. Specifically, this persistent memory is packaged between a set of processors with their non-persistent memory (for example, DRAM) and a chunk of symmetric multi-processor (SMP) compute through high bandwidth links (such as PCI-Express). This burst buffer also sits between the non-persistent memory and slower, but significantly larger persistent memory, for use as more permanent storage.
The burst buffer’s purpose is allow applications running on an SMP’s fast processor cores to perceive that the application data – data first residing in the SMP’s local and volatile memory – will be quickly saved on some persistent media. As far as the application is concerned, its data, once written into the burst buffer, had become persistent with a very low latency; the application did not need to wait long to learn that its data had been saved. If the power goes off after the completion of such a write, the data is assumed to be available for subsequent use.
The data residing in the burst buffer is not the data’s ultimate destination, but the application need not perceive that. The application believes that the quickly written data is held persistently, and then it becomes the responsibility of the burst buffer device to forward this same data to the larger and slower storage media. You can see this effect in this silly burst-buffer animation link (supported by MIT’s Scratch); the left side is the application data, the right side (the goal) are the persistent storage, in this case, say, hard drives.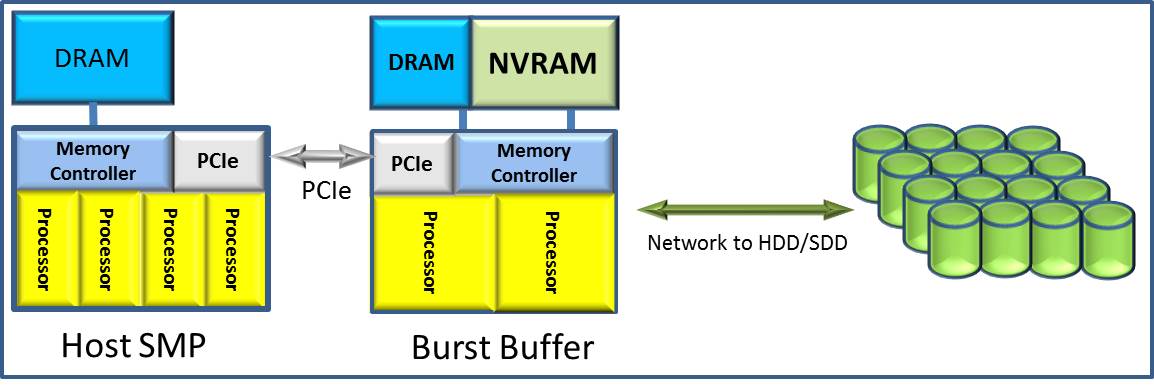
Why the term burst buffer? In comparison to the total size of target persistent storage, the burst buffer is small. But perhaps more important, the bandwidth into the burst buffer is often much larger than the bandwidth out of the burst buffer. Picture, for example, constantly filling up that animation’s bucket with a big hose and draining it with a smaller one; it would not take long before the bucket fills up and you need to turn off the big hose. So, if your application was capable of consistently writing data into the burst buffer at a rate exceeding that of the bandwidth out of the burst buffer, the buffer would fill up and your application would need to wait. Instead, if you are occasionally turning on the big hose – turning it on in bursts – even the small hose left on – emptying the bucket consistently – can avoid having the bucket fill up. The “burst” in burst buffer says that your application can occasionally write data blocks as bursts into the burst buffer at very fast rates, and so with lower latency. But on average – over longer periods of time, the average rate of data being written can be no faster than can be read out of the burst buffer and into longer term persistent storage. Referring again to our animation, for a while, the application-cats can very quickly fill the bucket, but then they need to either stop or write slower into the buffer; the goal-cat needs to have the time to empty out the bucket to make space.
But it’s not just bandwidth that we are playing with here. We are also talking about the latency of a write into persistent memory. Certainly a high bandwidth link from the SMP’s memory to that of the device containing the burst buffer’s persistent memory is key, but suppose that this persistent memory were just a set of spinning disks? The data would get across the link fast but then would need to wait for the usual HDD latencies; these longer latencies are related to positioning the head over the correct cylinder and sector to actually do the write. So, within the burst buffer device, we are also implying the use of more rapid forms of solid-state memory acting as the persistent memory. To empty the burst buffer, we’d also want relatively rapid reads of this same memory when the burst buffer device forwards its data to the longer-term storage devices.
OK, got it. But why bother with a burst buffer in the first place? As best I can tell, this notion recently reached its greatest interest in support of HPC’s need for data checkpointing. Because of the potential for failure of some type in really large systems driving massively parallel algorithms, these same algorithms need to occasionally checkpoint their state. This was just in case the algorithm needed to be restarted after such a failure; it wanted to restart where it left off, not the beginning. The pipe to persistent memory just was not wide enough nor fast enough with traditional types of persistent storage devices to allow for this checkpointing period to be perceived as being a small fraction of the processing time. The aforementioned burst buffer helped this out a lot. There are, though, other uses.
Comparative Anatomy: External Direct Attached Storage Devices
Before we go on, let’s do a bit of comparative anatomy to help picture this point. Let’s compare this notion of a burst buffer to more conventional external DASD controllers. Interestingly, external DASD also happens to incorporate hardware not dissimilar to that of a burst buffer. As in the figure below, the external DASD controllers also have
- Multiple Processors
- Dynamic Memory
- Non-Volatile Memory and
- Direct connections to many units of HDDs or SSDs.
Communicating with these external DASD controllers, from the volatile memory of the SMPs, requires multiple links, often passing over multiple bus types. When an SMP writes data to the controllers persistent memory, the data flows over these links, into the dynamic and then into non-volatile memory of the controller. Once successfully there, the controller can respond back to the SMP that the write request is now held in a persistent state, again responding over the multiple links. As with the burst buffer, the external DASD controller then stages this data in preparation for writing to the HDD or SSD proper.
At some level, the concept is very similar to that of the burst buffer. But each burst buffer device is very close to the SMP’s memory; typically just one PCI-Express link away and of higher bandwidth and lower latency than that available with the full set of busses and bus types to the external DASD controller. As a result the application, waiting for its data to become persistent, becomes aware of this condition much sooner. This allows the application to more rapidly return to processing.
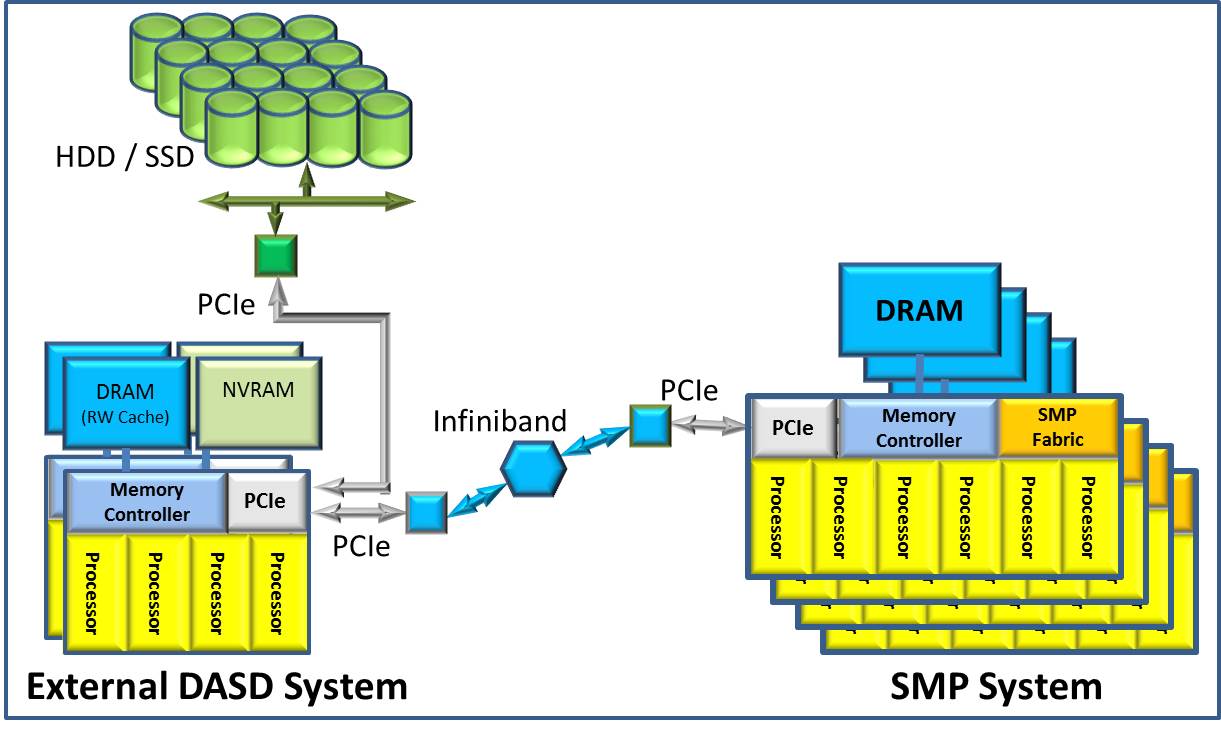
Notice, also, in the preceding figure the use of what appears to be redundant external DASD controllers. They are indeed there for higher availability redundancy. But, as can be seen in the following figure, the NVRAM acts as front-end persistent storage for the other controller. In the event of failure of one, given data had been written to the other’s NVRAM – prior to writing to the HDD/SSD – the remaining controller can pick up the data for the other and forward that data to the HDD/SSD. In that sense, it is a write cache or even a type of a burst buffer. Just like the burst buffer, the data must reside in this NVRAM persistent memory before the controller can respond to the host system that the data really is held in a persistent state.
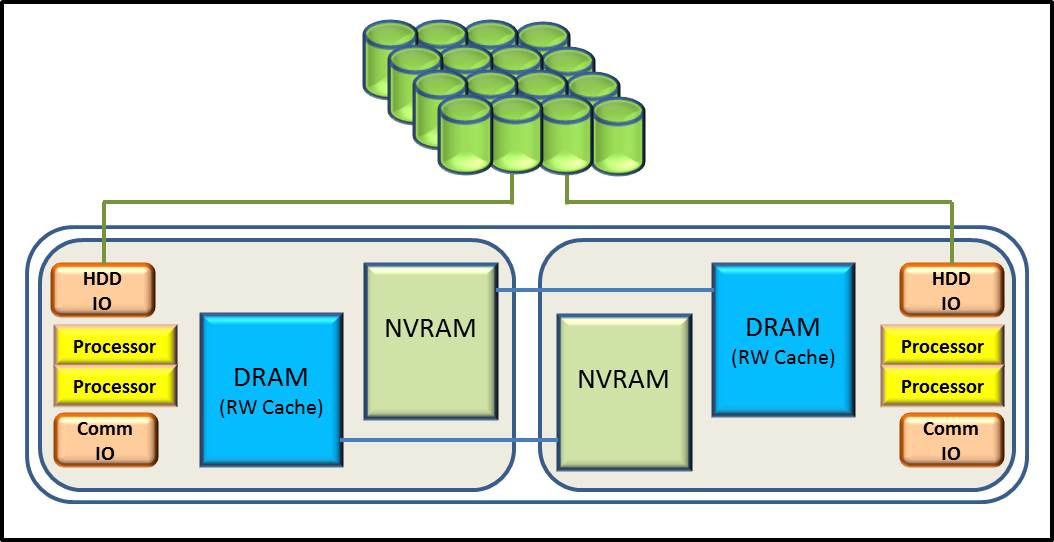
Also, like the burst buffer, performance can become limited by the size of the NVRAM. Notice that the contents of the external DASD’s DRAM – and so its back-up on the NVRAM – is also a staging area for data being written to the HDD/SSDs. Once written successfully, the area used in this memory becomes freed for subsequent use. But if this memory becomes full, subsequent data flowing into the controller must wait; this wait, in turn, becomes visible to the application.
Lastly, let’s recall just why persistent storage devices even exist. If there is a failure, like a power failure, when the controller subsequently returns to an active state, it will continue where it left off, writing the staged data to the HDD/SSDs. Subsequent reads of this same data will find the updated data as though no failure had occurred.
The Burst Buffer Approach
So it would seem that with burst buffers that we have a better solution for a rather specialized form of HPC application; a solution rather looking for a broader problem. But is it useful only there? Couldn’t such a device, one providing very low latency to persistent memory be of more general use as well?
Before going on, let’s again address what we mean by persistent memory. In the event of – say – a power failure, the use of persistent memory implies that any data residing there can be perceived as safe and available for use, no matter the user, once the system is restarted. For example, in a database transaction, if the database manager is told that the data it has written is in persistent memory, the database manager allows the transaction to complete. A subsequent transaction started after the power is restored (and the system restarted) must be capable of successfully using the data from the previously completed transaction. So any data written into a burst buffer and perceived by the database manager as having become persistent, must also be available for use, just as though it were successfully written to the more traditional slower disk drives. For what follows, let’s assume that the burst buffer technology is capable of being responsive to such a system restart.
We chose the notion of a database transaction in the preceding paragraph for a reason. burst buffers can be useful in multiple ways in speeding database transactions as well. To explain, let’s consider a system with a large set of concurrently executing and relatively complex database transactions, ones which just happen to also be changing the database. Think here in terms of thousands of such concurrently executing data-modifying transactions per second. The way that such database transactions often work is that, as each bit of data is accessed and perhaps marked for subsequent change, the database manager is sprinkling locks all over the database. Any concurrently executing transaction subsequently running into a conflicting lock set by another transaction often results in a delay;
- The latter transaction waits for the lock to be freed by the former or
- The latter transaction restarts in the hopes that the lock will later be found to be freed.
The intent of this is to ensure that the latter transaction does not see the results of the former until the former transaction has successfully ended.
The point is, the transactions running into lock conflicts appear to execute for a longer period of time than would have been the case without the lock conflicts. So, when and why do the locks get freed? The rules supported by database management systems often require that before the locks get freed, the data changes associated with each transaction – or actually something representing these changes – have to have first made their way out to persistent storage. Said differently, a transaction’s locks don’t get freed and the transaction doesn’t end until the transactions state is known to be on persistent storage.
So once again, before the locks can be freed, allowing conflicting transactions to make progress, a successfully executing earlier transaction must first wait for writes to persistent memory to complete. Without burst buffers – that is, with traditional forms of persistent memory – the earlier transaction must spend from many microseconds to multiple milliseconds, just waiting on such writes. Once the writes are known to be persistent, the transaction commences, and frees its locks. If this write time were to become much shorter, say via burst buffers, the locks get freed sooner, potentially prior to the point in time where the later transaction first even needed a lock (thereby avoiding lock conflicts).
A few milliseconds delay; no big deal right? Well, no, it happens that it often is. Because this one delay means that other otherwise concurrently executing transactions, transactions which are holding their own locks, are also holding their locks longer. This, in turn, results in still other transactions waiting still longer. It’s not just one transaction leaving its locks around, it can be thousands and they begin conflicting with each other because of the increasing length of time they are being held. These can occasionally turn into a real train wreck. A massive system with a lot of processors, all ideally busy driving database transactions up to the limit of their compute capacity, are instead largely simply idle, waiting themselves for the still waiting database transaction locks to free up. Of course, these now waiting transactions aren’t generating writes to disk, allowing the NVRAM to empty some. But would you rather hurry up and wait, or run fast most all of the time?
In the ideal, picture now an in-memory database – one where reads from disk are minimal – residing in a many multi-terabyte memory of – say – a large NUMA-based SMP system. Let’s also assume that we want the DBMS to maintain ACID properties. The transaction state of thousands of currently executing transactions – and subsequently their changed database data itself – is flowing quickly and at various rates into burst buffers. The trick for these devices is to ensure that it is also flowing data into slower backing-store devices at a rate sufficient to keep some burst buffer storage always available.
A Possible Future?
Published musings on the upcoming Power9 suggest that not only is it possible for PCI-Express-linked persistent storage, but future persistent storage could be directly attached to the processor chip’s memory bus. Instead of asking some device to asynchronously copy data from the host system’s DRAM and into the burst buffer device, it would then seem possible to make data persistent with nothing more than a process-based memory copy operation (along with flushing the copied data out of the cache.) Once out of the cache and residing in this storage, the data suddenly becomes persistent. Talk about a fast burst buffer!
Fast persistence, yes, but it is not quite that simple. Keep in mind why we are making the data persistent in the first place. We are placing the data there with the intent that it be available after, say, the power gets cycled; this is after the point that the OS was shut down. So suppose the OS that just wrote the data to this fast persistent storage just woke up. How does that OS know that the last time it was awake it had just completed a write which it wanted to save in case of such a calamity? Is this directly attached persistent memory somehow associated with a file system, or perhaps with a database log? Suppose also that this OS failed on this hardware system, but its replica woke up (or simply took over) over on another system? What then of the data still residing in the persistent storage in the now failed system? Can it be accessed?
I think you get the idea. It’s going to be great to have such rapidly accessible persistent storage in the relatively near future, but the normal expectations for persistent storage might need to change some if we also want to use such truly rapid persistent storage.
Single-Level Object Store And Burst Buffers
And now for something completely different. Most of us have got it into our head that persistent storage implies some form of a file system. Whatever we want to remain persistent goes into something like a file. Those of us who are programmers know that our data – our objects – resides in various address spaces, but then when we want to make it persistent, we flatten it out, remove it from our address space, and write it into a file. How inefficient is that? Why can’t we just place our objects directly into persistent storage and know – even after a power cycle – that our objects are just there where we left them?
Interestingly, there is an operating system that does just that, although that fact tends to be hidden within the operating system itself. This OS is very definitely object-based. It has a file system, of course, but files, directories, and libraries – and everything else for that matter – just happen to be objects of types known to this OS. This OS is now called IBM i, but for those who have been around for a while it was the System/38, then AS/400, iSeries . . . damn those marketers. But still better, from the point of view of burst buffers and persistent storage in general, those objects reside persistently at a unique virtual address. Yes, no matter the location of that object, be it in DRAM, a burst buffer, SSD, HDD, you name it, that object is represented by an address. Even if that power is off and the OS inactive, that object is still subsequently accessible using that address. Indeed, from the moment that the object is created, that object is bound to its address. They call this notion Single-Level Store (SLS), a completely appropriate name.
Why do I bring that up here in a discussion on burst buffers? At the time that this architecture was first being created, the basic storage model was one where volatile memory (a.k.a., DRAM, main store) was where the programs ran and objects were modified, and then something else wrote the data into persistent storage (also known as HDD, DASD) and it took a while to get there. It is one we are all used to. As a result, the OS would allow some data to be explicitly committed to persistent storage. But, recalling that every byte in SLS has an address and that physical memory is managed as pages, as the pages are aged out of the DRAM, the objects residing there are also aged into persistent storage (and subsequently re-accessible from there using that same address); in the fullness of time, any changed objects just automatically became persistent.
So, from a read point of view, aside from performance, SLS makes the distinction between volatile and persistent memory transparent; you want it, no matter the location, the OS finds it using its persistent address. It follows that with objects being staged via burst buffers – for ultimate write to, for example, HDD – if the application subsequently needed that object back in DRAM, the OS would use the object’s address and find that the object still existed in the burst buffer; as a result, it would access the object more rapidly from there.
The location transparency provided by SLS, and which historically has suffered from the performance penalty of HDD accesses, now also becomes more performance transparent as well. Object writes to burst buffers are done more rapidly. And for read accesses, if that object happens to still reside in the burst buffer, the reads are done more rapidly as well.
So, coming full circle, if you have an object that we want to be persistent, with a capability like SLS supported, you write it as an object, keeping the object’s organization as it is. And if that object store happens to be augmented by something like a burst buffer, you can be assured that it won’t take too long for your application to know that the object really is persistently held. And, by the way, if you want that object to stay in DRAM in the meantime, you can have that advantage as well.
Additional Reading
- Benchmarking a Burst Buffer in the Wild, Nicole Hemsoth, March 26, 2015, http://www.nextplatform.com/2015/03/26/benchmarking-a-burst-buffer-in-the-wild/
- Burst Buffers Flash Exascale Potential, Nicole Hemsoth, May 1, 2014, http://www.hpcwire.com/2014/05/01/burst-buffers-flash-exascale-potential/
- Perspectives on the Current State of Data-Intensive Scientific Computing, Glenn K. Lockwood, June 24, 2014, http://glennklockwood.blogspot.com/2014/06/perspectives-on-current-state-of-data.html?spref=tw
- NERSC Burst Buffer, http://www.nersc.gov/research-and-development/storage-and-i-o-technologies/burst-buffer/
- On the Role of burst buffers in Leadership-Class Storage Systems, April 2012, http://www.mcs.anl.gov/papers/P2070-0312.pdf
After degrees in physics and electrical engineering, a number of pre-PowerPC processor development projects, a short stint in Japan on IBM’s first Japanese personal computer, a tour through the OS/400 and IBM i operating system, compiler, and cluster development, and a rather long stay in Power Systems performance that allowed him to play with architecture and performance at a lot of levels – all told about 35 years and a lot of development processes with IBM – Mark Funk entered academia to teach computer science. He is currently professor of computer science at Winona State University. And, having spent far and away most of his career in the Rochester, Minnesota area, he continues that now working in IT for a major medical institution that is also located there.
Reprinted with permission of Mark Funk. Original story posted here.




What is the key difference in Burst Buffer and cache tiering, used by i.e. EMC (VNX FAST – Fully Automated Storage Tiering)?