
Rumors of the death of the monolithic parallel file system are not exaggerated.
It will not be this year. Real inklings of its demise will be clearer in 2017. And by 2018 and beyond, there could very well be a new, more pared down storage hierarchy to contend with, at least for very large systems as found at national labs and some of the world’s largest companies. And yes, even those who will cling to their POSIX past because, as it turns out, there’s a workaround for that.
John Bent, who has worked on innovative storage system hacks at Los Alamos National Lab (LANL) for the better part of his career alongside one of the pioneers of modern supercomputer-scale storage, LANL’s Gary Grider, forecasts to The Next Platform how the death knell will go. The end will begin in earnest with the arrival of the burst buffer to the storage stack—something that is already happening at several high performance computing centers, including at LANL with the massive “Trinity” supercomputer, which will take a very novel approach to how it faces a future with trillion entry namespaces.
Bent, who now works for EMC out of his offices at LANL, agrees it may be a bit ambitious to completely reimagine storage to the point that the POSIX bricks fall in 2017, but argues that the end is not much farther off. “If you look at the really large systems, the idea that they will all be running a monolithic, persistent file system has to change. As you look at the sizes and the amount of persistent storage needed and more important, look at the amount of storage class memory actually on the compute boards, whether NVME, phase change memory, or other types of non-volatile memory, it’s hard to imagine how anyone will want that single monolithic parallel file system to run on the storage and compute nodes—the reliability and resiliency issues are just two problems that come to mind.”
But to put some of this in context. Let’s back up for a moment and think about the evolution of the storage stack on the hardware side.
From the early 2000s until 2014, despite an ever-changing compute environment, the storage stack remained pleasantly static, at least for very large systems – those used by very large companies and national labs. Users had their compute bundled to a parallel file system and a tape archive system—something that remained constant for this class of system until more recently, with the addition of burst buffers in 2014. We’ll get to that last element in a moment, but the trends were driven by two basic demands of storage infrastructure; capacity and performance. The balance between those two wasn’t difficult for a time when adding disks for capacity brought the relative benefit of also adding more bandwidth. This trend eventually petered out since disks can only spin so fast and capacity needs only grow so high, hence we are brought to the present of flash-based (or hybrid) systems for greater balance.
That period up until 2014 or so wasn’t bad for users and administrators, Bent says, referring to the early release slide below from his upcoming USENIX talk in Santa Clara with burst buffer pioneer Grider, among others. But as the number of tiers starts to mount, the question of what next—in this case, a burst buffer—starts to offer ways to pare down those tiers. With the burst buffer absorbing all the complex, highly concurrent, parallel I/O and putting it out in a nice, tame stream for and by the storage system, what is the use of a parallel file system at all?
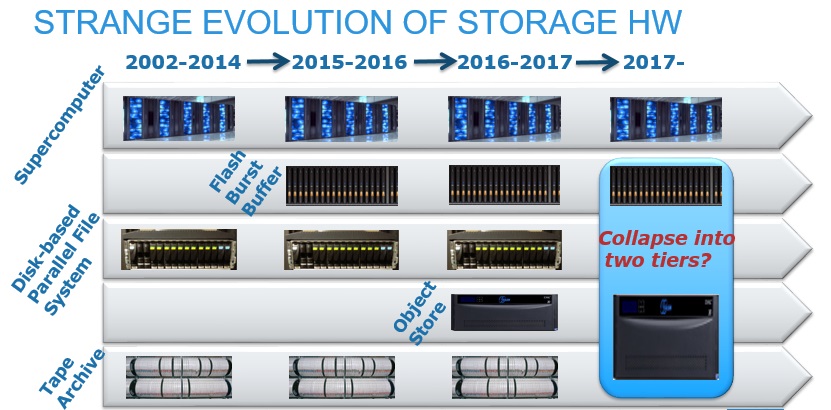
With the addition of burst buffers on the I/O nodes, storage on the compute nodes, the case for the massive single file system does, indeed, sound weaker. Further, while the latency for accessing storage class memory on the boards will be quite outstanding, if it’s necessary to hit a centralized metadata server anyway, where would there be a gain?
“Think about it. We have supercomputers with allocation models where people show up to the scheduler, request their resources, and those are given private and solely to them. They run on a portion and that portion doesn’t interfere with another. We have that on all aspects of big systems except for the parallel file system.”
Coupled with the burst buffer, enter the object store—the real game changer, even for supercomputing sites that have not been a target market for companies like Scality, who has been working with LANL. As we’ve talked about this before in reference to Grider’s work on the DAOS exascale storage approach, among other things, an object store can handle the downstream IO from the burst buffer and it turns out is also very good for both long-term retention of data and as cheap capacity. As this story goes, the burst buffer and the object store can take the helm as the HPC storage center, moving those tiers back down to a manageable number once again—two.
The file system as a single monolithic resource that can’t be used at the same time creates problems that aren’t new, particularly in terms of interference, security, and so forth, but to further add urgency, Bent says, that now, with the storage hardware stack moving closer to the processors, it also doesn’t make sense to go to some centralized metadata server being concurrently used when there’s all of this low latency storage that’s nearby.
The goal Is to make storage a service—to make it software that you bring with you. The application will link to a file system running just in user space that will take some portion of a file system’s namespace, check it out, and bring it along to its allocation and run its own user level service while bypassing the kernel as much as possible. In other words, the job simply will run on the subset of the namespace and when that’s done, there will be mechanisms to merge those back again.”
As one might imagine, when Bent, Grider, and others talked about this a few years ago, they were dismissed because for many users, the future has to be rooted in POSIX. There are far too many legacy applications in scientific computing and industries with long histories and even longer lengths of code. Further, they were dismissed because the idea of going directly to tape seemed absurd. But although tape is good for well-behaved streaming I/O there are also times that users want to interact with their data after its been de-staged from the burst buffer, so the parallel file system access remains important, at least if the idea is that we are moving away from monolithic file systems in the next year or two.
We will answer the question about what a POSIX-compliant present means for a zero parallel file system future more on Thursday when we describe MarFS, Grider’s effort to preserve some of the familiar trappings of POSIX interfaces with what’s coming in the later timeframes, but for now, it’s fair to state that the work being done to date is sticking with several supercomputing sites with some commercial end users taking notice as well, especially of MarFS, which will hold off the dreaded application and administration changes a little longer without being left behind on the some of the new efficiencies of the modern two-tier storage stack.
In his EMC work out of LANL, Bent is focused on what is, quite logically, called 2-Tiers, which will be software defined storage that can take a lot of cold capacity in one tier and wed it to fast performance in another. This is EMC’s approach to moving toward just such a strategy as set forth above.
Interestingly, EMC has some unique pieces to work with, including the DSSD hardware, which serves as the fast flash storage but which features a direct key value interface and built-in OS bypass to handle not just storage, but perhaps more importantly, the handling of metadata since those tiny volumes are nicely suited to a key value indexing. For large supercomputing sites that might consider this, DSSD also has a built-in PCI switch for 48 nodes to be connected with low latency on the same hardware—finally fully productizing something that has been interesting about DSSD since it was first acquired (while still in stealth) and have since only re-emerged in bits and pieces. Precisely what Dell will do with DSSD, XtremIO, ScaleIO, and other storage assets once it acquires EMC remains to be seen.
In the HPC world and in the hyperscale and enterprise arenas as well, file systems could end up being a very specific and exotic technology that is used sparingly because of their limitations and necessarily because of their ability to be updated, unlike other kinds of storage like object storage. That seems to be what a lot of the chatter is about, anyway.


The Continuum From Edges To Datacenters
Enterprise IT continues to cast its attentions – and sometimes its aspersions – out to the edge, that place outside of traditional datacenters and beyond that cloud where data is increasingly being generated and processed. At The Next Platform, we have written about the systems and platforms that hardware and …
Los Alamos Taps Seagate To Put Compute On Spinning Rust
High performance computing workloads simulating all manner of things can produce a veritable mountain of data that has to be sifted through. In fact, that is what makes HPC the opposite of AI: You take a small amount of data and explode it into a massive simulation. AI takes a …

Mythbusting Containers, The Los Alamos Way
As is the case with any new technology, there is a lot of hype and misunderstanding that comes along with something that actually improves some aspect of the system. Containers are no exception, and one has to separate the reality from the exaggeration and confusion to figure out how to …
Nice in-depth article, Nicole. We are seeing the same thing, both as a partner of LANL’s and more broadly: convergence to a two-tier model with very low latency storage in one tier and capacity-driven storage in the other. And it’s not only HPC. As more and more applications become eventually consistent and stateless, POSIX is less and less relevant.