

While it might not be an exciting problem front and center of AI conversations, the issue of efficient hyperparameter tuning for neural network training is a tough one. There are some options that aim to automate this process but for most users, this is a cumbersome area—and one that can lead to bad performance when not done properly.
The problem with coming up with automatic tools for tuning is that many machine learning workloads are dependent on the dataset and the conditions of the problem being solved. For instance, some users might prefer less accuracy over a speedup or efficiency boost or vice versa. In short, with so many “it depends” answers to the question of how to optimize a neural network, generalizing a tuning approach can be difficult. There are some places to start generalizing, however, and researchers are carving a path along those clearer lines.
“Existing hyperparameter optimization methods are highly parallel but make no effort to balance the search across heterogeneous hardware or to prioritize searching high-impact spaces,” says a team from the University of Notre Dame that has built a scalable hardware-aware distributed hyperparameter optimization framework called SHADHO.
This toolset calculates the relative complexity of each search space and monitors performance on the learning task over all trials. They say these are then used as metrics to assign hyperparameter to distributed workers based on the hardware environment. The framework scales to 1400 heterogenous cores and achieves 1.6X speedup in time to find an optimal set of hyperparameters over a standard distributed hyperparameter optimization framework.”
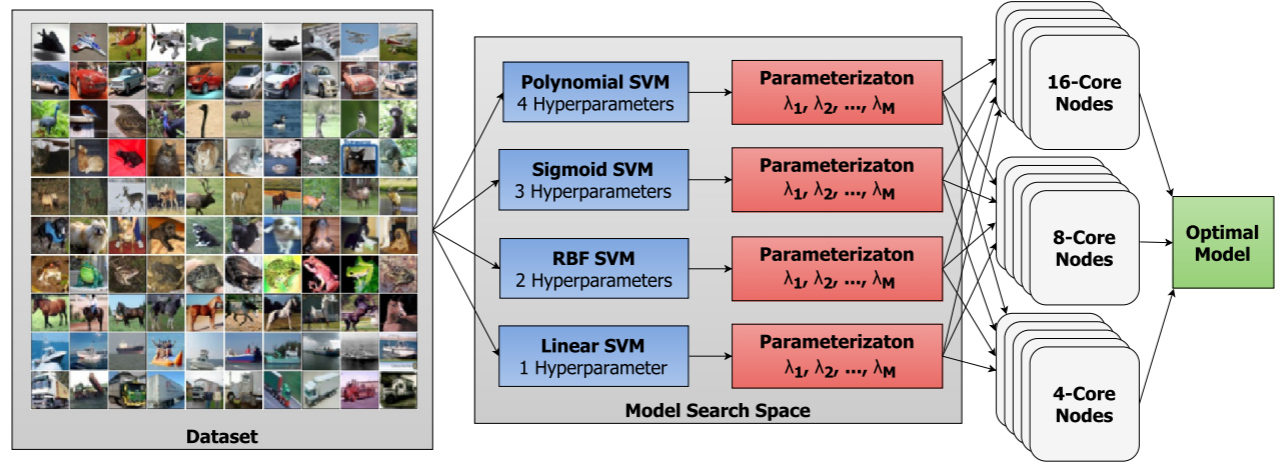
SHADHO initially directs hyperparameters to hardware by ranking structured search spaces in terms of their complexity. Then, during the search, it evaluates the performance of each space to determine impact and reassigns hardware to emphasize higher-impact spaces. SHADHO uses a search space specication language to construct search trees that incorporate domain knowledge about the models being optimized. Resources are specied using the Work Queue framework, allowing it to scale to available distributed hardware.
“While current tools for distributed hyperparameter search and optimization implement a large number of these strategies for choosing hyperparameters, little work has attempted to optimize distributed search patterns based on the structure and performance of the hyperparameters being searched. Current distributed hyperparameter search tools tend to assume that all search spaces are equally complex and equally important,” the authors note. “Moreover, they operate under the assumption that all connected hardware is appropriate for all parts of the search.”
Far more detail on the optimizations and performance results available here.


Google Teaches AI To Play The Game Of Chip Design
If it wasn’t bad enough that Moore’s Law improvements in the density and cost of transistors is slowing. At the same time, the cost of designing chips and of the factories that are used to etch them is also on the rise. Any savings on any of these fronts will …

Neuromorphic Chip Maker Takes Aim At The Edge
Neuromorphic computing has garnered a lot of attention over the past few years, largely driven by its potential to deliver low-power artificial intelligence to the masses. However, the most prominent efforts in this regard, IBM’s TrueNorth chip and Intel’s Loihi processor, are both currently lab projects undertaken by the research …
Programmable Networks Train Neural Nets Faster
When it comes to machine learning training, people tend to focus on the compute. We always want to know if the training is being done on specialized parallel X86 devices, like Intel’s Xeon Phi, or on massively parallel GPU devices, like Nvidia’s “Pascal” and “Volta” accelerators, or even on custom …
Be the first to comment