
Just like every kind of compute job cannot be handled by a single type of microprocessor, the diversity of networking tasks in the datacenters of the world require a variety of different switch and router ASICs to best manage those tasks.
As the volume leader in the switching arena, Broadcom comes under intense competitive pressure and has to keep on its toes to provide enough variety in its switch chips to keep its rivals at bay. One way that Broadcom does this is by having two distinct switch ASIC lines.
The StrataXGS line of chips have the famous and ubiquitous “Trident+” 10 Gb/sec and “Trident-II” 40 Gb/sec ASICs as well as the “Tomahawk” chips for 50 Gb/sec and 100 Gb/sec switching that made their debut in late 2014 and the “Tomahawk-II” follow-on that was just rolled out in October and that should appear in products sometime in the fall of next year. (Breathe now.) These Trident and Tomahawk chips are aimed at the cheap, fixed port, high bandwidth switches that dominate corporate and hyperscale datacenters. The Trident+ ASICs topped out at 640 Gb/sec of aggregate switching bandwidth, which the Trident-II doubled that up to 1.28 Tb/sec, the Tomahawk hit 3.2 Tb/sec and the Tomahawk-II doubled that up to 6.4 Tb/sec.
The StrataDNX line came to Broadcom through its $178 million acquisition of Dune Networks back in 2009, a company that was nine years old back then and that had developed a family of ASICs that are used to create modular switches (rather than fixed port devices) that have blades that can allow an enclosure to run multiple speeds and port counts and to make high-scale fabrics that link line cards within the chassis. These Dune devices are slower and deeper, rather than being more fast and furious. The modularity and flexibility of the Dune chips allows switch makers to create scalable devices that not only sport more ports, but that also have deeper buffers and larger tables (offloaded to DDR4 or GDDR5 memory) and have quality of service features that can allow for capacity to be allocated on a per-subscriber basis across the switching capacity encapsulated within the chassis. The deeper buffers are key for networks with heavy congestion (which happens on clouds and hyperscale workloads) and larger tables are key for networks with lots of devices hanging off them.
The “Arad” switch ASIC and “FE” fabric Ethernet chips in the Dune family debuted several years ago, and were followed on by the “Jericho” and “QumranMX” chips in March 2015. Broadcom has enhancing the Dune line with several new processors. The QumranMX chip topped out at 800 Gb/sec of aggregate bandwidth, which is no great shakes compared to the Trident-II+, Tomahawk, and Tomahawk-II ASICs, but the gigabytes of packet buffers made possible by the DDR4 and GDDR5 offload allows for the table forwarding in a switch to scale to millions of routes and MAC addresses, considerably more than the few thousands allowed in the few megabytes of packet buffer and forwarding table capacity used in the chips aimed at fixed function switches. This is why the Dune chips have been popular for spine and end-of-rack switches and core switches in the datacenter as well as in edge and core routers in carrier networks. They have also been deployed in optical transport networks linking datacenters to each other and in campus core switches. The StrataDNX chips launched nearly two years ago also aimed to expand Broadcom’s market with hyperscale-class core chassis switches as well as in compact carrier Ethernet aggregation switches, packet aggregation switches, and enterprise campus aggregation switches.
The the QumranMX chip from March 2015 has full support for Layer 2 and Layer 3 protocols as well as support or MAC network interfaces running at 1 Gb/sec, 10 Gb/sec, 40 Gb/sec, and 100 Gb/sec. It supports four or six uplinks running at 40 Gb/sec or 100 Gb/sec and up to 48 downlinks running at 10 Gb/sec across its 800 Tb/sec of aggregate full duplex switching bandwidth. Support for 25 Gb/sec and 50 Gb/sec interfaces was also allowed by aggregating the bandwidth in slightly different forms. The “Jericho” variant of this chip, which peaked at 720 Gb/sec of switching bandwidth, was aimed at modular switches and the “FE3600” fabric chip was its companion that allowed for a fabric of 144 of the Jericho chips to be lashed together with a total of 103.7 Tb/sec of bandwidth and a total of 6,000 ports running at 100 Gb/sec. We don’t know that anyone has done this, mind you, but it would be cool. With dual rail networks, you could link together 3,000 server nodes and do a lot of interesting work on a cluster, and we think it would be interesting to pitch a high bandwidth network based on Tomahawk-II against a more intelligent and lower bandwidth network based on Jericho.
In any event, on to the updated Dune chips, of which there are several and which again expand the total addressable market for Broadcom switch chips, says Nick Kucharewski, vice president of product marketing at the company. In this case, rather than scaling up the Dune chips for every-larger devices spanning bigger networks, Broadcom is scaling down the chips so they can be used at the end of the network, scaling the Dune family from core switching and routing down to the access and aggregation layers of the network at hyperscale, cloud, service provider, and enterprise networks.
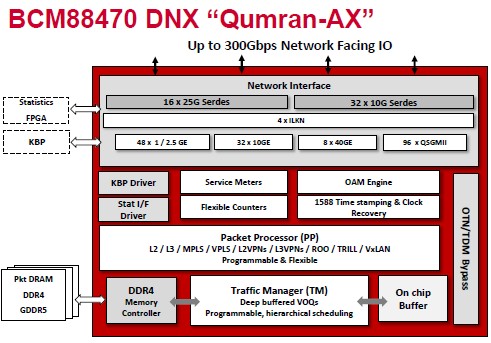
The new StrataDNX chips are really aimed at the workloads in the datacenter where having more than 10 Gb/sec is not a priority and having more scale for packet processing and larger buffers for dealing with more complex traffic is the issue. To be sure, says Kucharewski, these new chips are expected to be used on converged Ethernet and optical transport devices, in mobile backhaul gear, compact carrier Ethernet switch/routers, and even microwave access and aggregation equipment, but also in small top of rack switches that need the same deeper memory and tables that other Jericho devices have.
The first of the new Jericho-derived chips is the BCM88460, or “Qumran-AX” chip, which delivers up to 300 Gb/sec of switching bandwidth and can deliver 48 ports that support 1 Gb/sec or 2.5 Gb/sec speeds or 96 ports at a straight 1 Gb/sec. It can also support three ports running at 100 Gb/sec, eight ports running at 40 Gb/sec, and 32 ports running at 10 Gb/sec. The ASIC supports L2 and L3 protocols, of course, and VXLAN, NVGRE, and SPB tunneling to allow L2 to span L3, plus a bunch of other common protocols in the datacenter such as MPLS, VPLS, MiM, and PBB/PBT. Off-chip tables are stored in DDR4 memory in the case of the Qumran-AX. The “Kalia” BCM88476 chip is a variant of the Qumran-AX that has links to 25 Gb/sec fabric I/O so that multiple chips can be lashed together into a modular switch with line cards, much as can be done with the higher performance Jericho chips.
The BCM88270 is known as the Qumran-UX internally at Broadcom, and it can be configured to run at 32 Gb/sec, 64 Gb/sec, or 120 Gb/sec of aggregate switching bandwidth and has up to 1 GB of DDR4 memory for buffering. This chip can deliver 28 ports running at 1 Gb/sec or 2.5 Gb/sec speeds or eight ports running at 10 Gb/sec that can be configured as two ports running at 40 Gb/sec if need be.
The Qumran-AX and Kalia chips started shipping earlier this year to customers, and the Qumran-UX started shipping this month, and they provide a complete set of Dune chips with which network equipment makers can create a complete set of compatible devices. As it turns out, the same software development kit that is used for the StrataXGS chips such as Tridents and Tomahawks is also used for the Dune chips, so moving network operating systems from one to the other is doable. They don’t have exactly the same feature sets, so obviously there is some care that needs to be taken.
The question we have is will the Dune family of chips somehow usurp the Trident and Tomahawk lines in the datacenter.
“Within the carrier networks and service provider networks, we are already seeing that transition,” explains Kucharewski. “The DNX products offer hierarchical queuing and scheduling and the forwarding and tunneling support means that as a carrier you can configure your network for service isolation in every tier of the network and have a similar set of the network and have similar architectural capabilities at multiple bandwidth points. This is very attractive as opposed to having a different set of capabilities at different levels in the network.”
Some datacenter networks are architected to use integrated buffer chips on these XGS class chips, but others are architected to take advantage of deep packet buffers. In essence, you have a cached network with lower bandwidth pit against a much less cached network with higher bandwidth. What we want to know is which is the better approach for building networks. Bandwidth may not be as important for many workloads as buffering, and we would love to see these two families of chips tested against each other on a wide variety of network jobs and switches, with each given a thorough price/performance analysis. The carriers and service providers could be out at the front of the next wave of networking, ahead of even the hyperscalers and cloud builders.

Pushing PCI-Express Switches And Retimers To Boost Server Bandwidth
Things would go a whole lot better for server designs if we had a two year or better still a four year moratorium on adding faster compute engines to machines. That way, we could let memory subsystems and I/O subsystems catch up and get better utilization of those compute engines …
Broadcom Widens And Smartens Switch Chip Lineup
Cisco Systems may still be the biggest supplier of switches and routers in general, but it has long since been surpassed by Broadcom when it comes to suppling the silicon that does the switching itself and sometimes even a little bit of routing in the datacenter in particular. (Meaning not …
Broadcom Takes On InfiniBand With Jericho3-AI Switch Chips
Variety is not only the spice of life, it is also the way to drive innovation and to mitigate risk. Which is why we are seeing switch architectures evolving to drive specific kinds of AI workloads, just as we saw happen with HPC simulation and modeling workloads over the past …
Be the first to comment