

Training ‘complex multi-layer’ neural networks is referred to as deep-learning as these multi-layer neural architectures interpose many neural processing layers between the input data and the predicted output results – hence the use of the word deep in the deep-learning catchphrase.
While the training procedure is computationally expensive, evaluating the resulting trained neural network is not, which explains why trained networks can be extremely valuable as they have the ability to very quickly perform complex, real-world pattern recognition tasks on a variety of low-power devices including security cameras, mobile phones, wearable technology. These architectures can also be implemented on FPGAs to process information quickly and economically in the data center on low-power devices, or as an alternative architecture on high-power FPGA devices.
The Intel Xeon Phi processor product family is but one part of Intel SSF that will bring machine-learning and HPC computing into the exascale era. Intel’s vision is to help create systems that converge HPC, Big Data, machine learning, and visualization workloads within a common framework that can run in the data center – from smaller workgroup clusters to the world’s largest supercomputers – or in the cloud. Intel SSF incorporates a host of innovative new technologies including Intel Omni-Path Architecture (Intel OPA), Intel Optane SSDs built on 3D XPoint technology, and new Intel Silicon Photonics – plus it incorporates Intel’s existing and upcoming compute and storage products, including Intel Xeon processors, Intel Xeon Phi processors, and Intel Enterprise Edition for Lustre* software.
Computation
Fueled by modern parallel computing technology, it is now possible to train very complex multi-layer neural network architectures on large data sets to an acceptable level of accuracy. These trained networks can perform complex pattern recognition tasks for real-world applications ranging from Internet image search to real-time runtimes in self-driving cars. The high-value, high accuracy recognition (sometimes better than human) trained models have the ability to be deployed nearly everywhere, which explains the recent resurgence in machine-learning, in particular in deep-learning neural networks.
Intel Xeon Phi
The new Intel processors, in particular the upcoming Intel Xeon Phi processor family (code name Knights Landing), promises to set new levels of training performance with multiple per core vector processing units, Intel AVX-512 long vector instructions, high-bandwidth MCDRAM to reduce memory bottlenecks, and Intel Omni-Path Architecture to even more tightly couple large numbers of distributed computational nodes.
Computational nodes based on the upcoming Intel Xeon Phi devices promise to accelerate both memory bandwidth and computationally limited machine learning algorithms, because these processors greatly increase floating-point performance while the on-package MCDRAM greatly increases memory bandwidth. In particular, the upcoming Intel Xeon Phi processor contains up to seventy two (72) processing cores where each core contains two AVX-512 vector processing units. The increased floating-point capability will benefit computationally intensive deep-learning neural network workloads.
With Knights Landing, the Intel Xeon Phi product family will feature both a bootable host processor and PCIe add-in card versions. While both products are binary-compatible with Intel Xeon processors, the bootable host processor will also function like Intel Xeon processors, running off-the shelf operating system, supporting platform memory (up to 384GB of DDR4), featuring integrated fabric support, using the same IT/management tools, and more.
Intel Xeon Processors
The recently announced Intel Xeon processors E5 v4 product family, based upon the “Broadwell” microarchitecture, is another component in the Intel SSF that can help meet the computational requirements of organizations utilizing deep learning. This processor family can deliver up to 47%1 more performance across a wide range of HPC codes. In particular, improvements to the microarchitecture improve the per-core floating-point performance – particularly for the floating-point multiply and FMA (Fused Multiply-Add) that dominate machine learning runtimes – as well as improve parallel, multi-core efficiency. For deployments, a 47% performance increase means far fewer machines or cloud instances need to be used to handle a large predictive workload such as classifying images or converting speech to text – which ultimately saves both time and money.
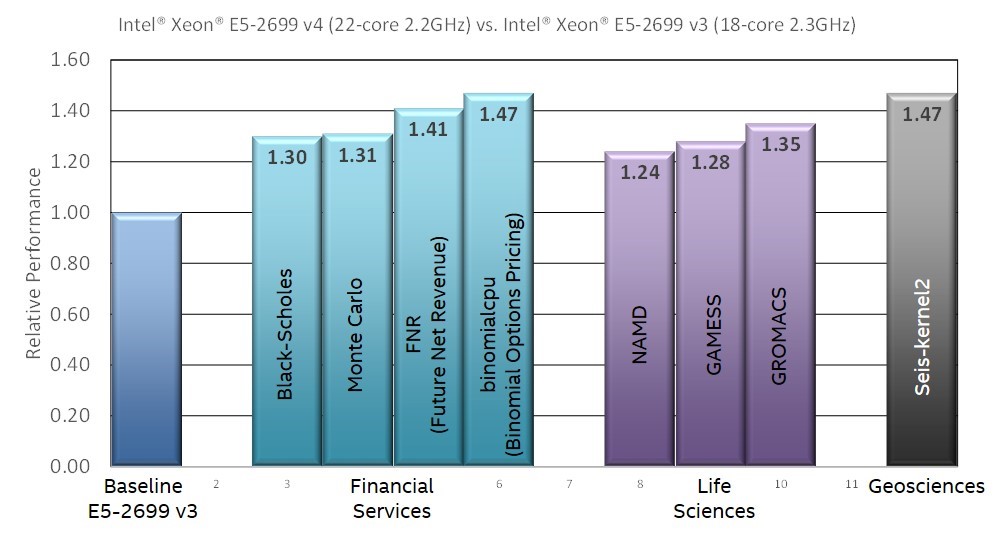
Figure 2: Performance on a variety of HPC applications* (Image courtesy Intel)
See the March 31, 2016 article, “How the New Intel Xeon Processors Benefit HPC Applications”, for more information about the floating-point and other thermal, memory interface and virtual memory improvements in these new Intel Xeon processors.
An exascale capable parallel mapping for machine learning
The following figure schematically shows an exascale capable massively parallel mapping for training neural networks. This mapping was initially devised by Farber in the 1980s for the SIMD-based (Single Instruction Multiple Data) CM-1 connection machine. Since then, that same mapping has ran on most supercomputer architectures and recently been used to achieve petaflop per second average sustained performance2 on both Intel Xeon Phi processor and GPU based leadership class supercomputers. It has been used to run at scale on supercomputers containing tens to hundreds of thousands of computational devices and has been shown to deliver TF/s (teraflop per second) performance per current generation Intel Xeon Phi coprocessors and other devices.
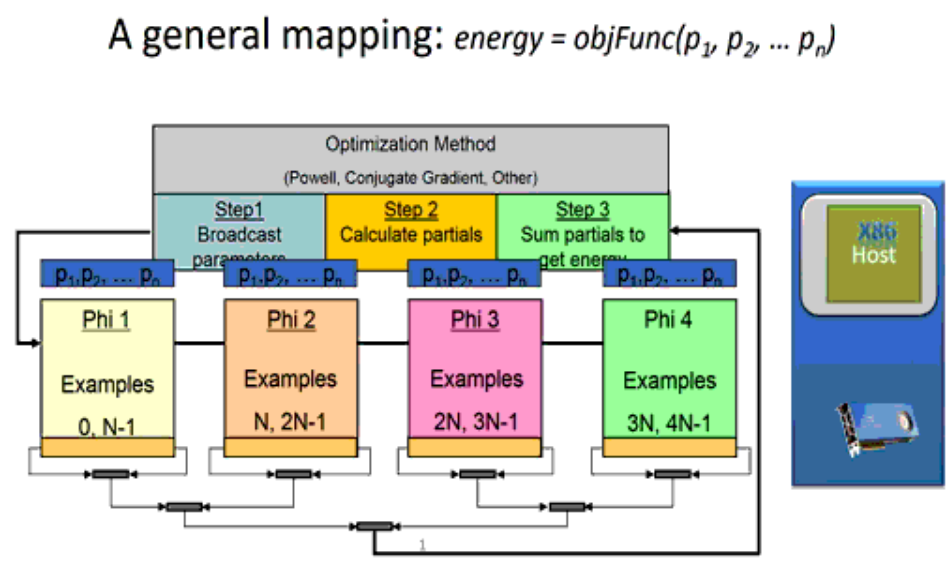
Figure 2: Massively Parallel Mapping – Click to see animation (Courtesy TechEnablement)
With this mapping, any numerical nonlinear optimization method that evaluates an objective function that returns an error value (as opposed to an error vector) can be used to adjust the weights of the neural network during the training process. The objective function can be parallelized across all the examples in the training set, which means it maps very efficiently to both vector and SIMD architectures. It also means that the runtime is dominated by the objective function as training to solve complex tasks requires large amounts of data. Each calculation of the partial errors runs independently, which means that this mapping scales extremely well across arbitrarily large numbers of computational devices (e.g. tens to hundreds of thousands of devices). The reduction operation used to calculate the overall error makes this a tightly coupled computation, which means that performance will be limited to that of the slowest computational node (shown in step 2) or by the communications network for the reduction (shown in step 3). It also means that the overall scaling is exascale capable due to the O(log(NumberOfNodes)) behavior of the reduction operation.
For more information see:
- Chapter 7, “Deep Learning and Numerical Optimization” in High Performance Parallelism Pearls.
- Dobbs, “Exceeding Supercomputer Performance with Intel Phi”.
Computational vs. memory bandwidth bottlenecks
The hardware characteristics of a computational node define which bottleneck will limit performance – specifically if the node will be computationally or memory bandwidth limited. A balanced hardware architecture like that of the Intel Xeon Phi processors will support many machine-learning algorithms and configurations.
The runtime behavior of the objective function (shown in step 2) dictates if training performance within a node will be floating-point arithmetic or memory bandwidth limited. Well implemented machine-learning packages structure the training data in memory so it can be read sequentially via streaming read operations. Current processors are so fast that they can process simple objective functions faster than the memory system can stream data. As a result, the processor stalls while waiting for data. Complex objective functions, especially those used for deep-learning, have a high computational latency (meaning they require more floating-point operations), which relieves much of the pressure on the memory subsystem. In addition, asynchronous prefetch operations can be used to hide the cost of accessing memory, so complex deep-learning objective functions tend to be limited by the floating-point capabilities of the hardware.
Computational nodes based on the new Intel Xeon Phi processors promise to accelerate both memory bandwidth and computationally limited machine learning objective functions, because computational nodes based on these processors greatly increase floating-point performance while on package MCDRAM greatly increases memory bandwidth3.
In particular, each upcoming Intel Xeon Phi processor contains up to seventy two (72) processing cores where each core contains two Intel AVX-512 vector processing units. The increased floating-point capability will benefit computationally intensive deep-learning neural network architectures. The large machine-learning data sets required for training on complex tasks will ensure that the longer Intel AVX-512 vector instructions will be of benefit.
The new Intel Xeon Phi processor product family will contain up to 16GB (gigabytes) of fast MCDRAM, a stacked memory which, along with hardware prefetch and out-of-order execution capabilities, will speed memory bandwidth limited machine learning and ensure that the vector units remain fully utilized. Further, this on-package memory can by backed by up to six channels of DDR4 memory, with a maximum capacity of 384GB. Providing a platform with the capacity of DDR memory and the speed of on package memory.
Convergence and numerical noise
The training of machine-learning algorithms is something of an art – especially when training the most commercially useful nonlinear machine-learning objective functions. Effectively, the processor has to iteratively work towards the solution to a non-linear optimization problem. Floating-point arithmetic is only an approximation, which means that each floating-point arithmetic operation introduces some inaccuracies in the calculation, which is also referred to as numerical noise. This numerical noise, in combination with limited floating-point precision can falsely indicate to the numerical optimization method that there is no path forward to a better, more accurate solution. In other words, the training process can get ‘trapped’ in a local minima and the resulting trained machine-learning algorithm may perform its task poorly and provide badly classified Internet search results or dangerous behavior in a self-driving car.
For complex deep-learning tasks, the training process is so computationally intensive that many projects never stop the training process, but rather use snapshots of the trained model parameters while the training proceeds 24/7 non-stop. Validation efforts are used to check to see if the latest snapshot of the trained network performs better on the desired task. If need be, the training process can then be restarted with additional data to help correct for errors. Google uses this process when training the deep-learning neural networks used in their self-driving cars 4.
Load balancing across distributed clusters
Large computational clusters can be used to speed training and dramatically increase the usable training set size. Both the ORNL Titan and TACC Stampede leadership class supercomputers are able to sustain petaflop per second performance on machine-learning algorithms6. When running in a distributed environment, it is possible to load-balance the data across the computational nodes to achieve the greatest number of training iterations per unit time. The basic idea is to choose a minimum size of the per-node data set (shown in step 2) to minimize the per node runtime while fully utilizing the parallel capabilities of the node so no computational resources are wasted. In this way, the training process can be tuned to a computational cluster to deliver the greatest number of training iterations per unit time without a loss of precision or wasting any computational resources.
A challenge with utilizing multiple TF/s computational nodes like the Intel Xeon Phi processor family is that the training process can become bottlenecked by the reduction operation because the nodes are so fast. The reduction operation is not particularly data intensive, with each result being a single floating-point number. This means that network latency, rather than network bandwidth, limit the performance of the reduction operation when the node processing time is less than the small message network latency. Intel OPA specifications are exciting for machine-learning applications as they promise to speed distributed reductions through: (a) a 4.6x improvement in small message throughput over the previous generation fabric technology7, (b) a 65ns decrease in switch latency (think how all those latencies add up across all the switches in a big network), and (c) some of the new Intel Xeon Phi family of processors will incorporate an on-chip Intel OPA interface which may help to reduce latency even further.
From a bandwidth perspective, Intel OPA also promises a 100 Gb/s bandwidth, which will greatly help speed the broadcast of millions of deep-learning network parameters to all the nodes in the computational cluster plus minimize startup time when loading large training data sets. In particular, we look forward to seeing the performance of Lustre over Intel OPA for large computational clusters, which means very large training runs can be started/restarted with little overhead.
Peak performance and power consumption
Machine-learning algorithms are heavily dependent on the fused multiply-add (FMA) performance to perform dot products. In fact, linear neural networks such as those that perform a PCA (Principle Components Analysis) are almost exclusively composed of FMA operations. One example can be found in the PCA teaching code in the farbopt github repository. Thus any optimizations that can increase the performance of the FMA instruction will benefit machine-learning algorithms be they on a CPU, GPU, or coprocessor.
These FMA dominated linear networks are of particular interest as they can show how close actual code can come to achieving peak theoretical performance on a device, as the FMA instruction is counted as two floating-point operations per instruction. These FMA dominated codes can also highlight bottlenecks within the processor. For example, GPU performance tends to fall off rapidly once the internal register file is exhausted, because register memory is the only memory fast enough to support peak performance. As a result, register file limitations can be a performance issue when training large, complex deep-learning neural networks. It will be interesting to see how performance is affected on Intel Xeon Phi processors as the cores transition from running mainly out of the L1 to a combination of the L1 and L2 caches to finally having to utilize MCDRAM memory as the deep-learning neural network architecture size increases.
Of course heat generation and power consumption are also critical metrics to consider – especially when evaluating a hardware platform that will be training machine-learning algorithms in a 24/7 environment. At the moment, both the current generation Intel Xeon Phi coprocessors and GPUs deliver multi-teraflop per second performance in a PCIe bus form factor. It will be interesting to measure the flop per watt ratio of the new Intel Xeon Phi processors as they run near peak performance when training both linear and nonlinear neural networks.
In the next couple of months, TechEnablement will do a deep dive on each of the Intel SSF components to explore their application to machine learning and to help the HPC community identify the right combinations of technology for their HPC applications.
1 Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit http://www.intel.com/performance. Results based on Intel internal measurements as of February 29, 2016.
5 http://www.cs.berkeley.edu/~wkahan/Math128/Projects/LamMath221.pdf
6 http://insidehpc.com/2013/06/tutorial-on-scaling-to-petaflops-with-intel-xeon-phi/
Rob Farber is a global technology consultant and author with an extensive background in HPC and a long history of working with national labs and corporations engaged in both HPC and enterprise computing. He can be reached at info@techenablement.com.


HPC In 2020: AI Is No Longer An Experiment
If we could sum up the near-term future of high performance computing in a single phrase, it would be more of the same and then some. Although no “revolution” is in the horizon, the four major trends of the past decade – the expansion of artificial intelligence technology, processor diversification, …

Programming The Network With Intel NEX Chief Nick McKeown
It would be very difficult indeed to find a better general manager for Intel’s newly constituted Network and Edge Group networking business than Nick McKeown, and Pat Gelsinger, the chief executive officer charged with turning around Intel’s foundries and its chip design business, is lucky that Intel was on an …

Argonne Aurora A21: All’s Well That Ends Better
When it comes to a lot of high performance computing systems we have seen over the decades, we are fond of saying that the hardware is the easy part. This is not universally true, and it certainly has not been true for the “Aurora” supercomputer at Argonne National Laboratory, the …
Rob, the bulk of iterations in converging a DNN only require 16 bit floating point. Did Intel add a 16 bit multiply or MulAdd? They will need it to compete with nVidia’s Pascal, I suspect.
That is an over generalization. So far that holds only true for CNN that work on highly quantized data. (sound, image) And for those there are actually newer solutions out there that would only require 1-Bit if you want to go to the extreme where nVidia Pascal would completely fail to perform at all. While even Intel XeonPhi would still have decent integer performance x 72
Oh for those who do not know Intel open sourced its DAAL library a couple of weeks ago. And the latest version includes NN framework.
https://01.org/daal/