

One of the ultimate legacy high performance computing applications, Lattice QCD (quantum chromodynamics) has been adapted to run efficiently on Intel Xeon Phi coprocessors. Due to its importance, the Lattice QCD simulation has been ported to run on most supercomputing architectures since the 1980s.
Dr. Tilo Wettig, a professor of Theoretical Physics at the University of Regensburg in Germany, recently explained the selection of the current generation Xeon Phi (formerly code name Knights Corner or KNC) for use in their custom designed QPACE 2 supercomputer, which is a system that was spawned via a collaboration between the University of Regensburg team and Eurotech.
In a nutshell, QCD is a theory that describes the strong forces that bind matter together. Lattice QCD is a mathematically well-defined, numerical simulation of the QCD theory that is used improve the fidelity (e.g. precision) of certain QCD values that cannot be determined analytically. These computer generated numbers are extremely important as they allow scientists to examine noisy experimental data more precisely when they attempt to establish (or refute) the viability of new theories about the fundamental building blocks of matter.
“Lattice QCD is unusual as we have very accurate performance models that reflect the runtime behavior of this simulation for various computer architectures”, said Dr. Wettig. These performance models were used during the component selection process for the QPACE 2 supercomputer, which meant the University of Regensburg team was able to compare the price/performance and performance/watt of the Xeon Phi against other architectures without having to first build the system. “In the end”, he said, “It was the programmability of the Xeon Phi that was the deciding factor”. Wettig also noted that Intel’s roadmap for the Phi (code name Knights Landing) played an important role in the decision making process as it includes processors that contain an integrated on-chip fabric interconnect. It is expected that the future QPACE 3 system will be based upon the Intel Xeon Phi Processor code name Knights Landing.
Wettig confirmed that the team chose correctly as “porting our Lattice QCD code ended up being a single person effort, which is pretty good”. The port of their Lattice QCD code was performed by Simon Heybrock at the University of Regensburg. Wettig noted that most of the intellectual effort in porting the code to Xeon Phi coprocessors involved optimizing the memory layout to make full use of the AVX-512 vector units. The most time consuming task turned out to be placement of the software prefetch instructions during the optimization effort. (The current generation processors do not support hardware prefetching, a feature that will be supported in the forthcoming Intel Xeon Phi code name Knights Landing.)
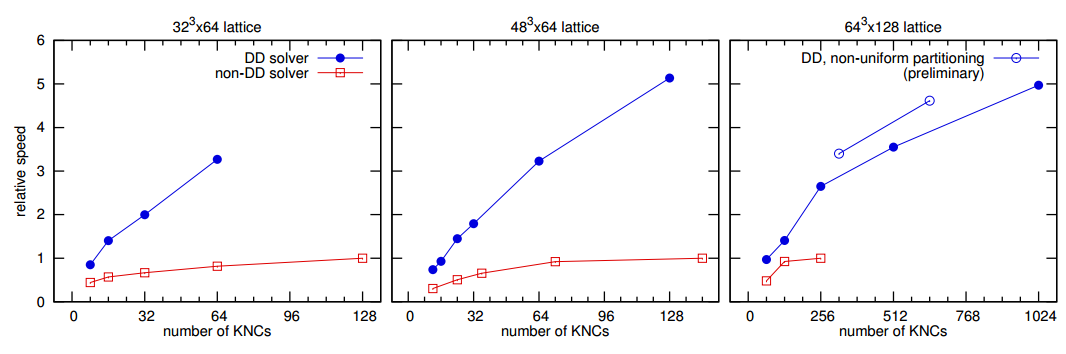
Part of the motivation for the move to Intel coprocessors is that, as Wettig observed, “Cost and performance are now favorable to the use of general-purpose hardware like Intel Xeon Phi processors”. The drawback is that general-purpose systems have significantly more communications latency compared to more specialized machines such as IBM Blue Gene based supercomputers. To overcome the latency drawback, the University of Regensburg team utilized a scalable computational method described in their paper, Lattice QCD with Domain Decomposition on Intel Xeon Phi Co-Processors that “strong-scales to more nodes and reduces the time-to-solution by a factor of 5”. The team also highlighted in a second paper, QPACE 2 and Domain Decomposition on the Intel Xeon Phi, that “In some performance-relevant parts we were successful in improving the performance by using InfiniBand directly (i.e., without MPI) via the IB verbs library”.
A number of elegant design decisions went into the creation of the custom QPACE 2 nodes to reduce manufacturing and operating yet create a supercomputer capable of running the Lattice QCD simulation at a substantial percentage of the theoretical peak performance of the Intel Xeon Phi processors 24/7 for extended periods of time. Wettig mentioned that a limit has been set in the scheduler to prevent a single job from running more than four days, but that most jobs generally finish in around ten hours. The team keeps a number of jobs queued so the system stays constantly busy.
The deceptively simple schematic of a QPACE 2 node is shown below.
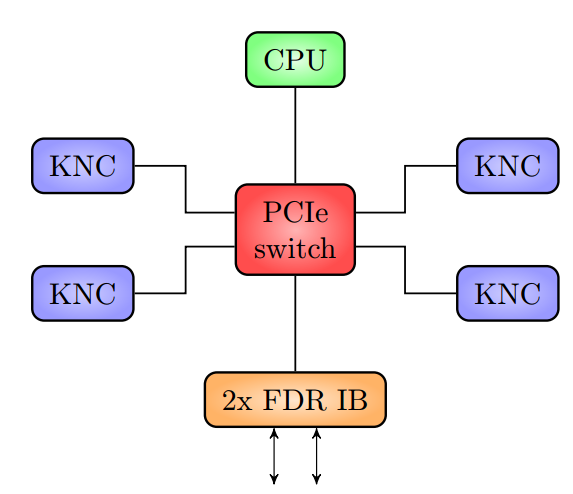
Cost savings dominates the design of the QPACE 2 hardware. Since all computations occur on the Intel Xeon Phi coprocessors, only a very inexpensive host processor is required to manage the four devices within a node. All communications between the co-processors within a node occur via the PCIe bus, which saves money as no network hardware is required. Communications between nodes occurs via the two FDR InfiniBand ports on each IB card that are connected to IB switches arranged in a two-dimensional hyper-crossbar topology. This configuration was chosen as it costs less than a fat tree while still efficiently supporting the Lattice QCD simulation.
The QPACE 2 hardware was also designed to minimize operating costs while running the highly optimized Lattice QCD simulations that makes full use of the Intel Xeon Phi coprocessor’s performance, which means that the processors will get hot. To account for this, the Intel Xeon Phi coprocessors were modified to use water cooling as shown in the pictures below. The design of the water cooling system is particularly elegant as it will keep the QPACE 2 hardware cool so long as it is supplied with water that is 50◦C or less. No chillers are required!

The water cooling system is described in detail in QPACE 2 and Domain Decomposition on the Intel Xeon Phi paper, but it is worth noting that the manufacturing costs for the water cooling system were kept to a minimum through the use of widely-available and inexpensive roll-bond technology that allows custom shaped water channels to be created. These custom channels were then designed to minimize the risk of water leakage.
The desire to run a very high percentage of the Intel Xeon Phi coprocessor’s peak performance meant that the porting effort had to be tightly focused. Wettig mentioned that the team initially attempted to optimize the code for both Intel Xeon Phi coprocessors as well as Intel Xeon CPUs. They decided to focus only on Intel Xeon Phi coprocessors, thus simplifying the code base, once team found that the Lattice QCD simulations ran very efficiently in native mode on the coprocessors.
There are two reasons why the Intel Xeon Phi coprocessor native mode worked for the team: (1) the Lattice QCD runtime is dominated by the parallel performance of a few kernels, and (2) the sequential performance of the Intel Xeon Phi coprocessors was sufficient to run the serial sections of the Lattice QCD code without adversely affecting the runtime, and the percentage of theoretical peak performance achieved by the simulation code.
In addition, the Lattice QCD simulation – courtesy of the scalable domain decomposition mentioned previously – is able to efficiently run in native mode across all the devices in the QPACE 2 supercomputer. As a result, the porting effort was able to avoid the non-trivial problem of maximizing floating-point performance while simultaneously dealing with the complexities of interleaved asynchronous offload-mode data transfers across a PCIe bus while also factoring in the impact those offload-mode transfers might have on the InfiniBand communications latency as all the IB data also traverses the PCIe bus.
The porting effort was further simplified through the use of auto-vectorization by the Intel® C++ compiler. “Initially the code was written using vector intrinsics – essentially programming the vector operations in assembly language”, Wettig said. Simon Heybrock added, “We used auto-vectorization very successfully in the simpler cases but continued using intrinsics for the parts that required many permutations, shuffles, and masking of registers”. The real work was performed up-front when designing the data structures to make full use of the wide AVX-512 vector instructions. Wettig observed that “this was complicated due to a heavy reliance on complex numbers”. “Once vectorization of the inner loop was achieved”, Simon added, “pragma vector aligned and pragma ivdep yielded the desired result”.
The VTune Amplifier profiler also proved to be useful in finding L1 cache stalls and improvements in prefetching behavior. While the group has had success running Lustre natively on Intel Xeon Phi coprocessors on other hardware configurations, they’ve not yet run it on QPACE 2 due to an InfiniBand driver issue.
Looking ahead towards QPACE 3, the University of Regensburg team expects Intel Xeon Phi Processor code name Knights Landing to deliver a 3x performance improvement plus a straightforward port of the Lattice QCD codebase. Specifically , the team wrote in Lattice QCD with Domain Decomposition on Intel Xeon Phi Co-Processors, “Porting our code from KNC to KNL will require only modest efforts since the instruction set architecture is quite similar, and hence the maintainability of the code base is ensured”. This represents the stellar ROI (Return On Investment) that a single, highly-capable programmer can deliver when developing the software for a well thought-out Intel Xeon Phi processor based project.
In closing, Wettig stressed that cost dominates component selection for custom designed supercomputers such as QPACE 2, “so much depends on product pricing and the effect it will have on the price/performance ratio relative to other solutions”.


DUG Sets Foundation For Exascale HPC Utility With Xeon Phi
While exascale systems, even at the single precision computational capability commonly used in the oil and gas industry, will cost on the order of $250 million, that cost pales in comparison to the capital outlay of drilling exploratory deep water wells, which can cost $100 million a pop. The trick …

The End Of Xeon Phi – It’s Xeon And Maybe GPUs From Here
To a certain extent, the “Knights” family of parallel processors, sold under the brand name Xeon Phi, by Intel were exactly what they were supposed to be: A non-mainstream product that tried out a different architecture than its mainstream Xeon family of server processors and that was aimed at the …

Argonne Hints at Future Architecture of Aurora Exascale System
There are two supercomputers named “Aurora” that are affiliated with Argonne National Laboratory – the one that was supposed to be built this year and the one that for a short time last year was known as “A21,” that will be built in 2021, and that will be the first …
Be the first to comment