

Although the Top 500 list of supercomputers has come to something of a standstill in the last few incarnations of the bi-annual benchmark, the next few years will provide plenty of the way of interesting new machines worldwide.
In China, the excitement will be around the upcoming Tianhe-2A machine, which will feature Intel host processors to kick along a homegrown DSP-based accelerator, but in the U.S., a triad of systems will seek to give China more competition. These three major systems, which are part of the CORAL procurement, are part of a joint effort from the Department of Energy to host leadership-class supercomputers at three large national labs (Oak Ridge, Lawrence Livermore, and Argonne). As part of the original RFP, the machines needed to represent architectural diversity so while Oak Ridge and Lawrence Livermore looked to the IBM, Nvidia, Mellanox matching to round out their top-tier systems, Argonne went a separate direction, choosing Intel as the prime contractor (a move that surprised many) with Cray as the integrator.
We discussed the architectural details for the upcoming Aurora supercomputer at length when we broke the story and in a more detailed piece about the configuration and what we were able glean about the forthcoming Intel “Knights Hill” architecture back in April. For review, that might be a good place to start, but what is interesting here is that Argonne is set for some big changes, especially considering it has long been the site of a great deal of development on the IBM BlueGene architecture. Its current top system, Mira, is based on BlueGene, which means that the large-scale scientific applications running on that system now will need to be moved to fit into an X86 box, an undertaking that is not insignificant.
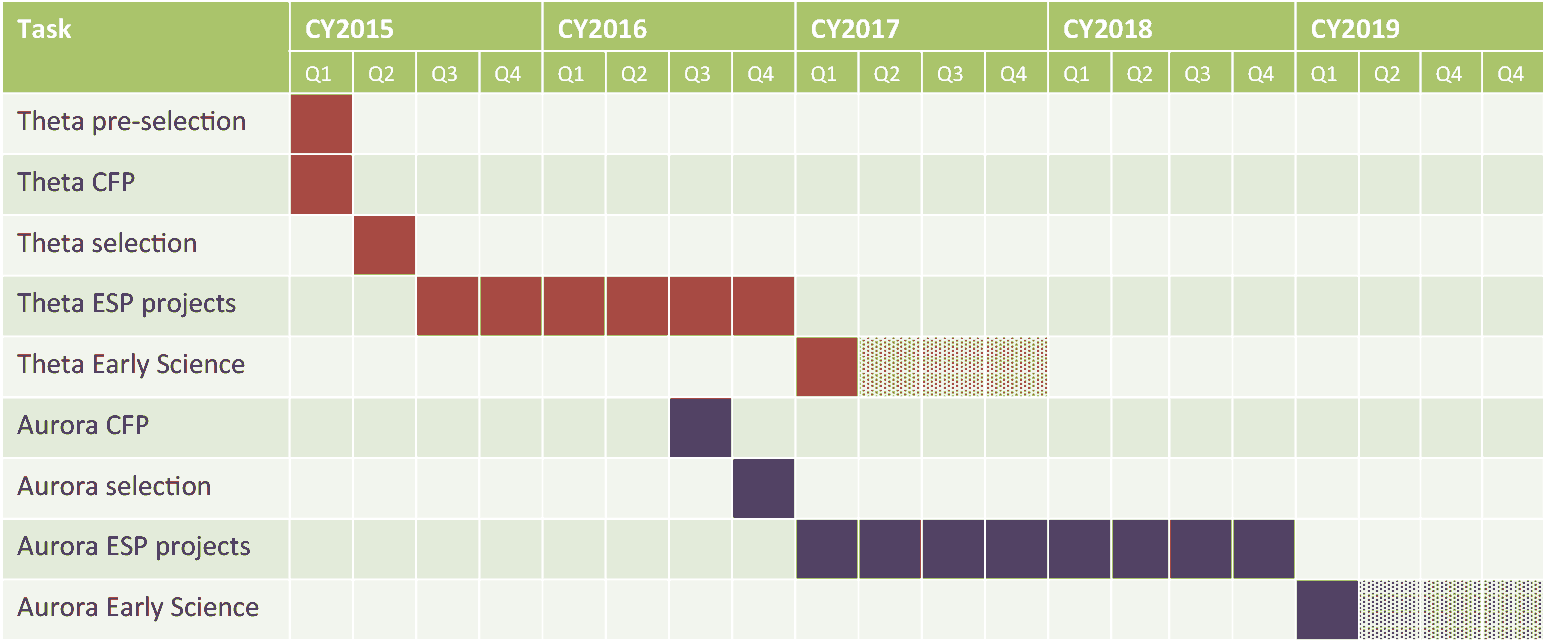
Today, during the Advanced Scientific Computing Advisory Committee in Washington, D.C., Argonne National Lab’s Susan Coghlan provided more insight about the status of the systems set to arrive at the lab. Although there was not more detail presented on the exact architecture, the comments show that the road from BlueGene to X86 presents more of a challenge than making the big core jump from one big X86 supercomputer to another far more powerful one. For instance, as Coghlan pointed out in reference to the first of the systems set to arrive before Aurora, Theta, “the jump from Mira to Theta will be more challenging than the one from Theta to Aurora.” The node count does not increase much, although the number of cores will. And, as one might expect, making the architectural leap (just as will happen on the other architectures in the 2016-2018 timeframe as part of CORAL) will be the biggest barrier.
Aside from differences in architecture, there are other advantages that are unique to Theta and eventually, its much more powerful sibling, Aurora. “Both have a deep memory I/O architecture with a small amount of very fast memory and a large amount of slower, but higher capacity memory. There will also be a burst buffer for Aurora (and there as an option if it can be funded for Theta) and other layers as part of this I/O system that will set the stage for exascale,” Coghlan noted.
As noted previously, the Theta system (arriving late next summer, after Trinity and Cori—two other stepping stone systems at the other sites) will be a stepping stone for Aurora, which will be moved over to handle data analytics once Aurora comes online in 2018. The Theta machine will feature the Knights Landing architecture and will be capable of around 8.5 petaflops with an option to expand the system if the funds are present (for context, Aurora will hit 180+ petaflops peak, with upgrade in the plan to reach a potential 450 petaflops).
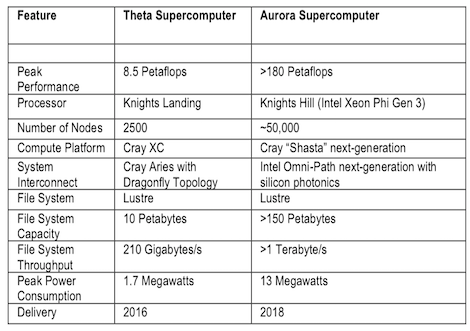
Theta will weigh in at just over 2500 nodes and has, as we have discussed, well over 60 cores per node with high bandwidth memory and SSDs on each node along with a Lustre file system—a change from GPFS. Overall, Coghlan says, “If you look at the impact from going to Mira to Theta, the programming environment will be much the same. It’s an MPI and OpenMP environment and many of our users have put the threading in to get to Mira’s benefits but they’ll need to expand that because of the increased node concurrency.”
One interesting difference the team at Argonne will need to contend with is the different interconnect architecture. (they are moving from a 5D torus to the Cray Aries Dragonfly topology, which has some advantages in terms of higher connectivity). Aurora will have the Omni-Path network but it will be the same topology essentially, so if the codes have been accommodated for the dragonfly it will be similar. Other differences include the vectorization capabilities that are cooked into the new Intel processors. Vectorization on the BlueGene was a challenge at times, Coghlan says. “The compilers seem to be better at auto-vectorization. The AVX 512 is widely used, so there’s a growth path to start on a smaller system and work your way up, which was not really an option with the BlueGene/Q.”
The memory system is also promising, Coghlan notes. The fastest memory on Theta is much faster—12x than the fastest memory on memory and the DDR4 is 2.7x faster than what is on Mira. The capacity is more per node as well and while that won’t be the case with Aurora, it does set the Theta machine apart. Overall, she says there will be better single-thread and integer performance. Further, in terms of the core and thread capability; on Mira there were 16 cores and 64 hardware threads, but on Theta users will have over 60 cores and over 240 hardware threads, so this does present some potential challenges the teams will work through. When Aurora arrives, the total memory for the system will be approximately 7 petabytes with the split high-bandwidth and DDR5 memory. Most notably, the aggregate bandwidth will be around 30 petabytes/sec with the addition of OmniPath.
Even though Coghlan was careful to point out some of the tough spots ahead, she says the Argonne team thinks “it will be relatively easy for our users to port and the work we’ve been doing in the Intel simulator for the Xeon Phi seems to bear that out so far.” The projected performance (over 12x for key applications compared to Mira) is based on Intel simulators and projection tools, but Coghlan says they are confident these are on target with what the eventual system will look like in Aurora’s case.
Argonne placed its bets on BlueGene for many years, but hopes the new X86 efforts will lead to a solid long-term partnership with both Intel and Cray. “The Knights Hill chip is not yet in silicon, so a lot is still unknown. We put targets out across a shared risk model with the vendor [Intel/Cray]. There is a go/no-go date prior to when they have to purchase all the parts and build the system. We look at those targets and hope it’s a go… but we get a lower price with a shared risk model,” Coghlan says.

Industry Behemoths Back Intel’s Universal Chiplet Interconnect
When the hyperscalers, the major datacenter compute engine suppliers, and the three remaining foundries with advanced node manufacturing capabilities launch a standard together on Day One, this is an unusual, significant, and pleasant surprise. And this is precisely what has happened with Universal Chiplet Interconnect Express. The PCI-Express interconnect standard …

Talking Servers With Inspur And Intel
Any time a server maker comes into the global market and bypasses Cisco Systems, Lenovo, and IBM to become the third largest seller of machines in the world, you should pay attention. This is precisely what Inspur Information, the server unit of Chinese IT supplier Inspur Group, has accomplished, and …

Software, Not Hardware, Will Drive Quantum and Neuromorphic Computing
In emerging computing fields like quantum computing and neuromorphic computing, hardware usually grabs the lion’s share of attention. You can see the systems and the chips that drive them, talk about qubits and computing that simulates how the human brain works, sort through the speeds and feeds, talk about interconnects …
Be the first to comment