

As we described in some detail in a previous piece that outlined the impetus for China to step up development of its own supercomputer chips following the trade restrictions for Intel chips in large Chinese systems, China will continue to stick to the accelerated machine approach for the upgrade of its top-ranked Tianhe-2 system.
When Tianhe-2A supercomputer emerges (behind schedule since the team at the National University of Defense Technology had planned on outfitting it with Knights Landing cards to bring it another 45 petaflops) it will now feature a homegrown architecture as the acceleration unit. Interestingly, as a slide we captured during the briefing at the International Supercomputing Conference noted, the host processor appears to be a Xeon E5 2692, a carryover from the existing Ivy Bridge architecture that is part of the existing system.
The new accelerator for the upcoming Tianhe-2A supercomputer, which is slated to arrive sometime next year, was referred to as both the “China Accelerator” and the Matrix2000 GPDSP.
Unlike other DSP efforts that were aimed at snapping into supercomputing systems, this one is not a 32-bit part, but is capable of supporting 64-bit and further, it can also support both single (as others do) and double-precision. As seen below, the performance for both single and double precision is worth remarking upon (around 4.8 single, 2.4 double teraflops for one card) in a rather tiny power envelope. IT will support high bandwidth memory as well as PCIe 3.0. In other words, it gives GPUs and Xeon Phi a run for the money—but the big question has far less to do with hardware capability and more to do with how the team at NUDT will be able to build out the required software stack to support applications that can gobble millions of cores on what is already by far the most core-dense machine on the planet.

Each of the optimized GPDSP cores (with both scalar and vector units, dedicated vector memory, and VLIW capabilities) are integrated into one “supernode” as system designer for the Tianhe machines at NUDT, Dr. Yutong Lu calls it, via a high speed, non-blocking network on chip to connect these supernodes at 4 terabytes per second. There is a global shared cache and the ability to configure cache policies and to handle cache validation on address scopes. Lu also briefly touched on the DMA engine that backs this but there are not many details at this point beyond the fact that it will provide both broadcast support and extend the capabilities of global cache and the individual memories.
To be fair, the interesting part here isn’t just the accelerator itself. It’s not even about the processors either. From a systems level, China is working hard to develop its own custom blend of homegrown technologies that could, at any moment, carve U.S. tech vendors out of the picture entirely. The best example on the Tianhe machine is the one that was grossly overlooked when the system was announced. The custom TH2 interconnect is the key to the system’s performance—and this is entirely unique to this machine. While there are still not adequate details about the performance of applications or benchmark results that some do not take big issue with (more on that tomorrow).
Lu introduced some new information about the TH-Express 2+ interconnect in the slide below. Aside from the slide details there was no additional detail given, so instead of rehashing the full slide is below:

Beyond the basic specs, the clever part about this interconnect (and what gives it its “adaptive” nickname) is that there is configurable routing that can dial the congestion in the interconnect and also allows for on-the-fly routing around node and network-level faults. There is also an offload mechanism Dr. Lu highlighted briefly that allows for the overlapping of communication and computation, thereby extending the role of the interconnect. We are still trying to get more information on how this works and is different from the original TH-2 interconnect when it emerged, so stay tuned on that.
At the storage level, the Tianhe-2A system will be a beast as well, sporting a hybrid pairing of 6400 node-local disk drives, 512 ION-local SSDs, and 128 storage servers to boot, all fed by the (also homegrown) H2FS file system. The machine will have 1 terabyte of burst, 100 GB of sustained performance, and will be capable of one million IOPS (which sounds low given the specs stated).
The software stack is another interesting element, especially since it will require a new platform that will, according to Lu, be based on Open 4.0. The operating system, math libraries and compilers will rest on the DSP unit and a GPDSP driver will manage the communication library. This will involve a layering of that communication library, which will sit under the Open MP4.0 compiler system—at least from what we can see now.
Even though the system-level discussion is fascinating here, the DSP angle will be interesting to see play out In real applications. The efforts here, which include ambitions to pour out into more data-intensive application areas leveraging Hadoop, Spark, and other “big data” ecosystem elements, are collected into the Starlight application framework as depicted below.
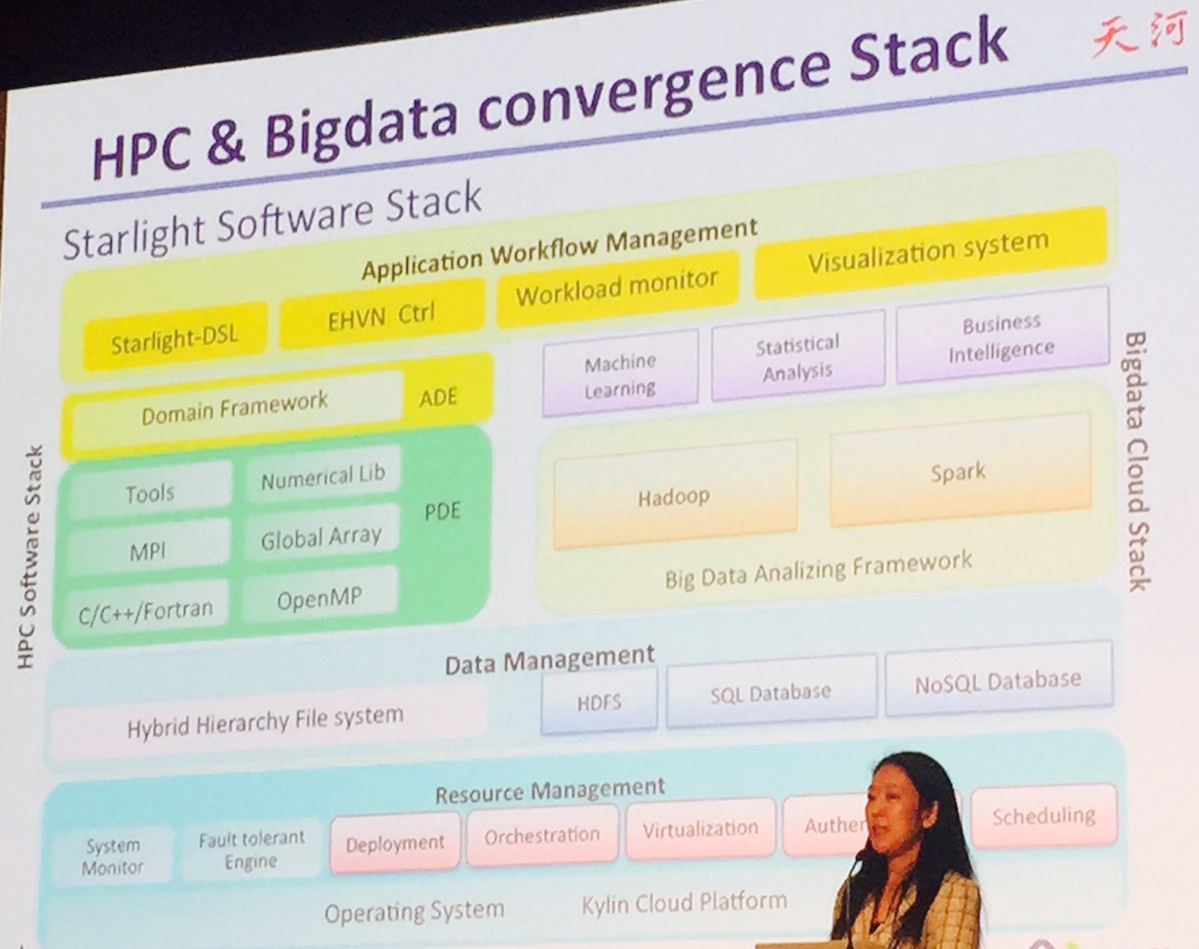
The Starlight framework will support some other initiatives that were discussed in the previous article about the system, including large social and cloud projects within China.
But going back to the Matrix2000 GPDSP (which presumably stands for general purpose at the prefix), Dr. Lu noted that NUDT has been working with DSPs for a number of years already and clearly, if they’re ready to rock and roll with these new chips installed and ready to run the LINPACK benchmark sometime next year (the assumption had been that they would have sparkly new Knights Landing cards to boost past the 100 petaflop peak for the November Top 500 list before the U.S. government stepped on that idea) these chips have already been developed, tested, and probably manufactured to some degree for testbed systems at the very least. And quite possibly running in production on other systems inside NUDT or elsewhere in China where they don’t have the supercomputer police looking over their shoulders, as is known to happen with machines purchased from U.S. companies.
As a quick side note, while FPGAs might be finding a new sweet spot in high performance computing (and certainly in hyperscale and cloud datacenters) the mighty digital signal processor (DSP) has been relegated to smaller devices and specific applications in defense, radar, and certain video areas. This is in part due to the software stack and ecosystem shortage but the real limitation has been the 32-bit cutoff and lack of double precision capability. The one company that was serious (for a time) about getting DSPs into HPC systems, Texas Instruments, has some specs published here that are, at least from Dr. Lu’s presentation, not even in the same ballpark performance-wise. But without more information, trying to make a comparison on conjecture is just going to mean a long, unpleasant phone call on a different time zone with TI. So we will wait for more info and stack them up side by side when we have it.
And as another side note, it is possible that TI only saw a market for DSPs inside supercomputers that could only ever grow so much. The impetus was not there, in other words. But slap down a blockade, upset the LINPACK apple cart for the next big system, and China has all the motivation they need to work hard to develop further the 64-bit capabilities, the software and programming environment, and the possibly profoundly painful application porting process.
The only question we can ask from this point is why not a homegrown GPU? And further, while they are at it, why not also swap out the Xeons for ShenWei processors?
Oh, sorry, too soon?


What’s Inside China’s New Homegrown “Tianhe Xingyi” Supercomputer?
China is using a domestic processor as the backbone for double the performance of the Tianhe-2 system, which topped the Top 500 starting in 2013 and running through late 2015 before being overshadowed by the Sunway system in recent years. We have no official public details about Tianhe-3, although the …

Where China’s Long Road To Datacenter Compute Independence Leads
While we are big fans of laissez faire capitalism like that of the United States and sometimes Europe — right up to the point where monopolies naturally form and therefore competition essentially stops, and thus monopolists need to be regulated in some fashion to promote the common good as well …

The Mystery Of Tianhe-3, The World’s Fastest Supercomputer, Solved?
We don’t like a mystery and we particularly don’t like it when what is very likely the most powerful supercomputer in the world – at this time anyway – is veiled in secrecy. But that is what the Tianhe-3 supercomputer built for the National Supercomputer Center in Guangzhou, China has …
Be the first to comment