

As a platform for doing analytics on large datasets that is much less costly than would be possible with parallel data warehouses, Hadoop and its myriad extensions and modified underpinnings has fulfilled its purpose. But it still has two big problems. First, customers always want queries to run a lot faster. And second, it takes far too long to set up a Hadoop cluster to even get going.
With its MapR Distribution 5.0 announced this week, MapR Technologies, one of the three big commercial distributors of Hadoop, is stepping up its game on both fronts.
The challenge with any new technology is that enterprise customers are loathe the change until they have to, and even when they do, they want the new thing to look and act like the old thing. Hyperscalers and HPC shops are used to more disruption in their lives and seem to thrive on it. Supercomputing centers are basically funded to take risks, while hyperscalers fundamentally have no choice because they are running at the limits of scale for hardware and software to handle their gargantuan workloads.
Keeping the pools of data that are used by different parts of the Hadoop stack – and we are using the term Hadoop in a very general way to include extensions like the Spark in-memory, Storm streaming, Kafka distributed messaging, and Elasticsearch search functions – is problematic. And not just within a cluster. Synchronization is even more important across clusters because large enterprises, like hyperscalers, want to replicate their data across geographically distributed datacenters not only for high availability but to bring data close to different sets of end users who hook into different clusters.
“This all falls under the category of big and fast,” Jack Norris, chief marketing officer at MapR, tells The Next Platform. “You can dump all of the data into MapR NFS and we can tailor the job directly for Spark, so you have got that synchronized. It is not like we are splitting the data and putting it into Hadoop and we do not have to try to figure out if there is downtime is there different data in Hadoop than in Spark. In other distributions, you tend to separate them out. You tend to have a Kafka cluster in front that separates the data, sending some to Spark, which is doing continuous stream processing, and some to Hadoop, which is doing additional analytics. We are seeing an architecture come out where customers have streaming, real-time database, and Hadoop all being used together.”
This stands to reason. Stream processing is doing aggregates on data as it flows in, but sometimes customers need to do a quick interactive query for specific information from relatively recent data, and other times they want to do queries against a much deeper set of data, perhaps after doing that ad-hoc query to test an idea, using either MapReduce or YARN schedulers. The Apache Drill tool, which is being commercialized in the MapR Distribution 5.0 stack and which we discussed a few weeks ago when it was unveiled, can be used as a data exploration tool as well as to do ad-hoc queries against the data stored in MapR-FS, which is a variant of the NFS Unix file system that has been at the heart of the MapR distribution.
MapR-FS has been the key differentiator for the company from the beginning, and it is significant in that it can speak the Hadoop Distributed File System (HDFS) APIs. That means it is a true file system, like the NFS that we all know and love from Unix (and then Linux) and it is not limited to the append-only approach of HDFS. Equally importantly, as you access the datasets stored in MapR Hadoop, whether you use the HDFS APIs or MapR-FS, you are accessing the same datasets and when you do a query through various tools against the data, you get the same answer.
Enterprises like big banks and credit card companies really like when you get the same answer to a question extracted out of a data lake, and regulators like it even more. As it turns out, consumers checking on the status of their accounts like to see consistency, too. (What it comes down to, really, is that everyone wants to have the Hadoop stack behave like a relational database even though it is most certainly not one.)
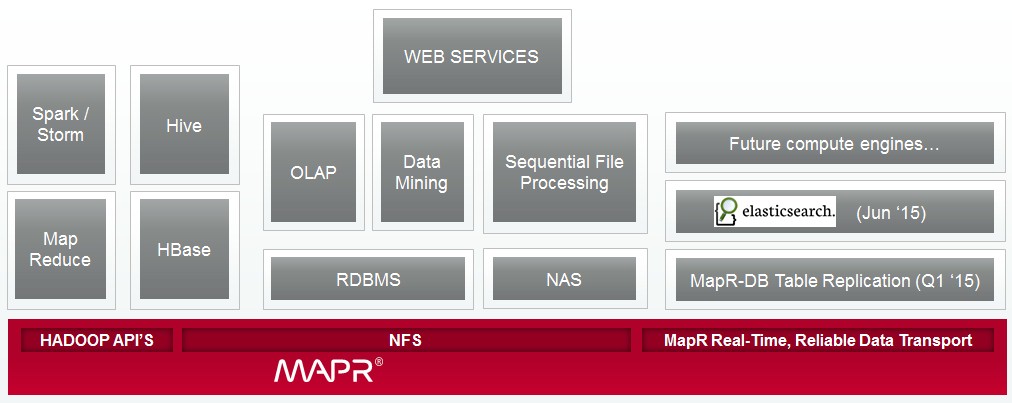
In the first quarter of this year, MapR extended this real-time synchronization that extends across the various ways of accessing its Hadoop file systems to cover its MapR-DB, a NoSQL data store that is compatible with the APIs used in the Apache HBase data warehousing extensions to HDFS. This synchronization for MapR-DB was within a cluster for database tables and across clusters that are linked through replication. And with the 5.0 release, Elasticsearch search engine indices are now replicated within a cluster and across dispersed clusters.
“You will now get a consistent version of truth across all of these elements,” says Norris. Before adding this support for Elasticsearch index synchronization, batch indexing was done through HBase, but with the synchronization now between MapR-DB and Elasticsearch, this indexing is done in real-time and without any customized coding on the part of customers as they have had to do in the past. And, again, the index maps to the current state of the data in the MapR-DB datastore.
All of this synchronization functionality is built into the MapR distribution, which costs $4,000 per node in a base setup with MapR-FS and under $10,000 per node with all the bells and whistles, including the MapR-DB NoSQL datastore.
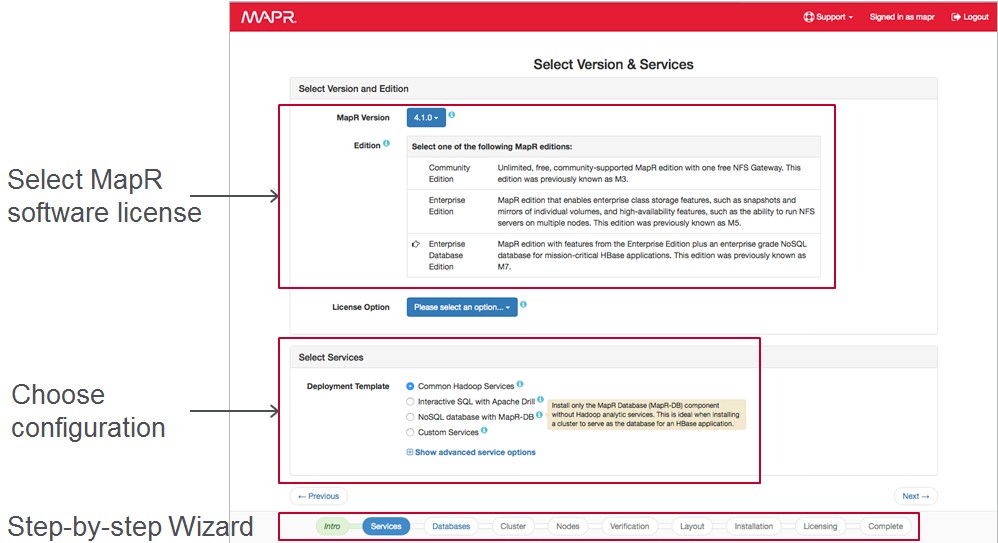
The other big change that MapR is putting into its Hadoop stack is a set of autoprovisioning templates for that make it quicker and easier to get the software up and running. There are a number of templates that are part of the 5.0 release. The first covers data lake scenarios, which deploy the most commonly used parts of the Hadoop stack, including YARN, MapReduce, Spark, and Hive. Another is aimed at data exploration, which coupled together Hadoop with the Drill SQL query tool. And the other is aimed at operational analytics, which pairs Hadoop with the MapR-DB NoSQL data store.
Norris tells The Next Platform that the templates are aimed at on-premises Hadoop installations at the moment and have been certified on hardware platforms from a mix of 50 different vendors. Given that Hadoop is also popularly deployed on public clouds, it would not be surprising to see auto-provisioning templates come out for Amazon Web Services, Microsoft Azure, and Google Compute Engine in the not-too-distant future. Amazon’s Elastic MapReduce service already offers MapR’s Hadoop distribution as an analytics engine alternative to the raw Apache Hadoop, but these templates will allow enterprises to set up what is in effect their own EMR service on top of raw compute and storage on the AWS cloud.
The neat bit about the templates is the auto-provisioning part, which takes a look at the hardware (physical or virtual) provided and maps the elements of the particular configuration to those resources to provide the best fit. It is not a rigid configuration in terms of the hardware, but rather an adaptive one. The templates are also rack-aware, so critical parts of the Hadoop stack can be spread across multiple racks to improve the availability and resilience of a Hadoop cluster. The templates also do periodic health checks on Hadoop clusters to ensure they are performing as they should and to alert administrators of potential issues.
MapR Distribution 5.0 is expected to be available in 30 days.


Getting Hadoop to Jump Through AI/ML Hoops
Just a decade ago, the enterprise IT push was to make Hadoop the platform for storage and analytics. At that time, cloud hesitancy was still looming for large on-prem organizations. Hadoop, no matter how that ecosystem played out over the years, became a major source of investment with the idea …
Beefing Up A Cloudy NoSQL Database To Ride The AI Wave
To Andrew Davidson, senior vice president of products at MongoDB, the database business operates in an entirely different type of market than traditional software, where vendors might sell their products into one organization after another, eventually reaching a saturation point. They can grow fast, but it’s tough to keep that …
Automagically Moving Legacy Hadoop To The Cloud
Always on the lookout for the kernel of a new platform, we chronicled the steady rise and sharp fall of Hadoop as the go-to open source analytics platform. In fact, we watched it morph into a relational database of sorts only to end up being cheap storage for unstructured data. …
I have also seen something for all the distros from WANdisco