
The promise of adding ultra-high performance to Hadoop is like offering to rig jet engines onto minivans. Some things were just not built for speed. While there is nothing stopping anyone from giving it a try, the extra weight for what might be a small burst of performance just does not necessitate the effort.
There have been plenty of vendor offerings in the Hadoop world that have indeed made incremental improvements, but add the only type of engine that will actually make that lumbering (but incredibly useful) bus fly is one that taps directly into motor’s guts. In this case, the network. This is the real bottleneck strangling Hadoop performance, so even with new software jets built in, without the right wiring, performance will still lag.
The differentiation between high performance for Hadoop and what can typically classify as the “expected” level of performance for MapReduce jobs does, in many ways, come down to hardware—more specifically, having the proper network infrastructure in place to grant some flexibility in how resources are managed. This is the driving force behind an ongoing research effort, which has since been put to the test at many of the national labs in the U.S. and at key research centers worldwide, to let Hadoop fully exploit HPC hardware.
The drive is led by notable high performance computing researcher, D.K. Panda from Ohio State University, who, along with his team, has created a set of software packages for Hadoop, Spark, and Memcached that allow for acceleration at the network level. The High Performance Big Data (HiBD) effort uses an HPC-specific technique, called remote direct memory access, to skip the hops and push Hadoop, Spark, and other big data applications’ performance.
Panda has spent decades of his career trying to build fast engines for lumbering frames. Much of his early work was focused on addressing the performance bottlenecks inherent to message passing interface, which is a foundational element for most large supercomputing jobs, albeit a very heavy and notoriously difficult framework to manage. The result of this work was a revised approach to network communication via remote direct memory access (RDMA), which in essence, allows nodes to tap into the memory of other nodes without making that hop through the operating system.
While this may sound simple in theory, first, that was a dramatic oversimplification of RDMA and second, it took over a decade of work from D.K. Panda and his teams, who were trying to improve latency on MPI systems. What is worth noting here is that the applicability of RDMA goes beyond MPI clusters and high performance computing, especially as the network layer is becoming one big bottleneck for Hadoop and Spark workloads, among others.
Panda and his team started working with Hadoop a few years ago, recognizing that while it might be getting enterprise play, Hadoop and its native HDFS file system were not designed for low latency and ultra-high performance. However, the in-memory companion project, Spark, did target time to result and has since been a springboard for a number of research projects that aim to lend it additional speedups.
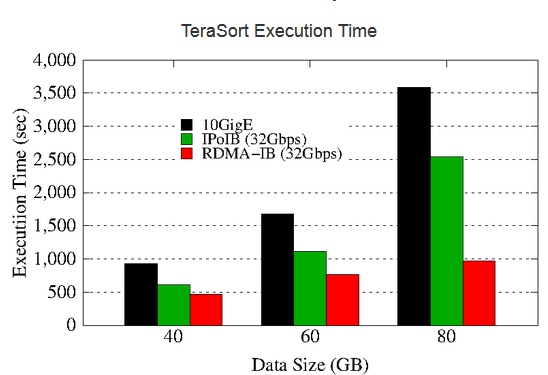
With RDMA, much of the communication is offloaded and what does remain has been pared down, which means a lighter load on the CPU, which is free to handle communication in fewer cycles. For Hadoop and Spark workloads, this can make a significant difference in terms of latency. This is the aim of Panda’s group, which has released a newly updated version of its package to bring high performance computing and big data closer together. HiBD, in its latest incarnation, includes RDMA-enabled Apache Hadoop with native RDMA support for many of the components, including the native HDFS file system, MapReduce and other elements. The newest release also includes support for Lustre, which is an important addition since most users at this stage already have HPC clusters and are exploring their use for running MapReduce workloads. The update also includes an RDMA-Memcached software package that supports RDMA as well as an updated benchmarking suite.
The figure below presents a high-level architecture of RDMA for the HiBD project’s latest Hadoop 2x release. As Panda explains, “In this package, many different modes have been included that can be enabled or disabled to obtain performance benefits for different kinds of applications in different Hadoop environments.”

There are some other notable additions to the latest release that go just beyond the mere ability to run MapReduce on existing Infiniband clusters with Lustre as the parallel file system (as a replacement for HDFS). Lustre is used to provide both input and output data directories. However, for intermediate data, either local disks or Lustre itself can be used.
 Traditionally, for users who make use of native HDFS, they only run with SSDs or disk, but Panda and team have made it possible to run in-memory directly from RAM with the option of running HDFS with a hybrid combination of in-memory, SSD, disk, or even Lustre.
Traditionally, for users who make use of native HDFS, they only run with SSDs or disk, but Panda and team have made it possible to run in-memory directly from RAM with the option of running HDFS with a hybrid combination of in-memory, SSD, disk, or even Lustre.
This is a novel way to think about what is possible given the extra hardware resources in terms of compute, storage, and memory that are part of a high performance computing cluster (versus a standard, mid-range off the shelf box).
While the work Panda and his team have done adding RDMA to Hadoop and Spark is only useful for those who already have HPC clusters that have the special adapters from Mellanox that allow for RDMA, there are potential opportunities for some of the distribution vendors to make use of this work to allow a broader class of HPC users who are dipping a toe into the MapReduce application waters eventually.

Be the first to comment