

There is a kind of law of relativity that differentiates hyperscale companies from large enterprises. The very logical things that enterprises do down at their large scale – such as operating distinct storage tiers that are optimized for different applications or for separate archiving use – oddly enough does not make sense at hyperscale. At the extremes, the scale of infrastructure actually warps economics in different ways, and that is why Google does not offer tape-based nearline or archival storage for its cloud customers.
Instead, Google has come up with ways to differentiate classes of service on its storage servers and the networks that link them together into a fabric, and the upshot is that the coldest storage that Google offers is a lot warmer than many cold storage offerings out there in the cloud or deployed for internal use by Google’s hyperscale peers.
With the Nearline Storage service, Google is able to offer near online storage performance for about half the price of its Standard Storage service – something that its competitors cannot yet do. This will be a very disruptive development for cloud storage, and partnerships with key enterprise backup and recovery firms who want to peddle appliances that push data out to cloud services like Google Nearline Storage instead of on-premises tape is going to help get this nearline service stuffed with data.
The difference between Google’s Standard Storage and Nearline Storage slices on its public cloud comes down to a software layer, Tom Kershaw, director of product management for Google Cloud Platform, tells The Next Platform. We also think there might possibly be extra physical distance between the devices hosting the Nearline Storage and servers residing in the Google datacenters and network links that expose Cloud Platform services to the outside Internet. The Nearline Storage could also be running on slightly older equipment that is heavier on the disk drives but that is not beyond its technical or economic life.
“Other cloud providers have built their own standalone, storage offerings based on a combination of flash and disk, then they built a completely different archival system that was just optimized around cost only,” says Kershaw. “We didn’t go down that road because we wanted to maintain a single stack because that creates fungibility of content.” This bit is important because most data starts out hot but very rarely stays hot. It gets used less frequently, cooling down, and then it may never be accessed again and turn stone cold. “So you need to be able to very seamlessly move stuff across the storage, and if you have completely separate farms it is really hard to move stuff. As everybody knows in storage, storing is cheap and moving is expensive. So we have software on top of our fabric that does the differentiation, but the underlying disk and flash is the same. Because we have such a massive volume of capacity on all of our other storage, if we put Nearline Storage on another kind of system we would lose the economies of scale.”
Google will not talk about the architecture of its servers and storage, except very rarely and only concerning equipment designs that are several years old when it does. It is safe to assume that Google has many millions of machines in its worldwide regions and because of those same economies of scale it is deploying Cloud Platform workloads on the same iron as its own workloads. (There are layers of security to keep these two sets of workloads absolutely separate, of course.) In the market at large, companies buy more compute than storage, but given the amount of data on cloud workloads – there is so much telemetry, so much rich media – the ratio is probably closer to 50-50 for the server/storage split for services like Google Cloud Platform, Amazon Web Services, and Microsoft Azure, which all operate at hyperscale. That easily means Google has tens of millions of disk spindles of capacity – and quite possibly even more than that. This does not mean that Google does not have massive tape libraries, by the way. It does have such devices, but they are not part of the Cloud Platform offering but are rather for its own internal uses.
Cold Storage That Is Pretty Warm
With the launch of Nearline Storage, Google Cloud Platform offers three different kinds of services for piling up data, which it calls buckets like many other public cloud providers do. They differ from each other on a number of dimensions, including cost per unit of capacity and latency to, bandwidth from, and availability of the data that is stored on the services. Here is the basic description of the three services:
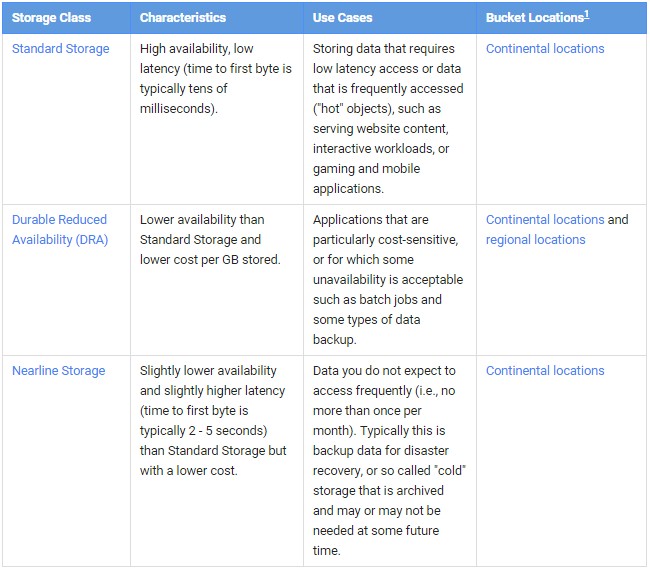 The durability of the storage service refers to how reliable the retention of that data is within the Googleplex. All of storage on Cloud Platform offers eleven 9s of durability, which means Google is 99.999999999 percent sure that it will not lose a chunk of data because it replicates it across its network of storage servers. Exactly what size of data chunk this durability refers to is not clear; It is possible that Google could offer data services that have variable durability, but it seems unlikely given how touchy everyone is about lost data.
The durability of the storage service refers to how reliable the retention of that data is within the Googleplex. All of storage on Cloud Platform offers eleven 9s of durability, which means Google is 99.999999999 percent sure that it will not lose a chunk of data because it replicates it across its network of storage servers. Exactly what size of data chunk this durability refers to is not clear; It is possible that Google could offer data services that have variable durability, but it seems unlikely given how touchy everyone is about lost data.
The Durable Reduced Availability Storage, or DRA Storage for short, has been sold by Google for some time, and its availability is knocked down a bit and its price shaved a bit compared to Standard Storage. The availability for Standard Storage is three 9s (99.9 percent) and for DRA Storage and now Nearline Storage it is two nines (99 percent). The idea for both DRA Storage Nearline Storage is that, by definition, the data is not accessed frequently, and thus if it is not immediately available on the Googleplex, then it should not be a crisis for any user or application.
Nearline Storage is cheaper than DRA Storage because it has lower bandwidth and higher latency. Nearline Storage has a bandwidth guarantee of 4 MB/sec per TB, compared to 10 MB/sec per TB for the Standard and DRA services. (The bandwidth adds up across capacity in all three services. So, for instance, Google guarantees 400 MB/sec of bandwidth on 100 TB of capacity for Nearline Storage or 1 GB/sec for 100 TB of Standard or DRA Storage.) Standard and DRA Storage services offer retrievals that take on the order of milliseconds. (This is a measure of the time to get to the first byte of data in a file, not the time to move an entire file, of course.) Nearline Storage has a time to first byte that is on the order of seconds.
“For Nearline Storage, we expect retrieval time of approximately 2 to 3 seconds, and the Standard Storage is typically 100 milliseconds,” explains Kershaw. “For serving content that is frequently accessed, 100 milliseconds is a pretty safe bar in the industry. For nearline or cold storage, you see most of the services measure themselves in hours to minutes. We consider 2 seconds to be our compromise, as low as we will go.”
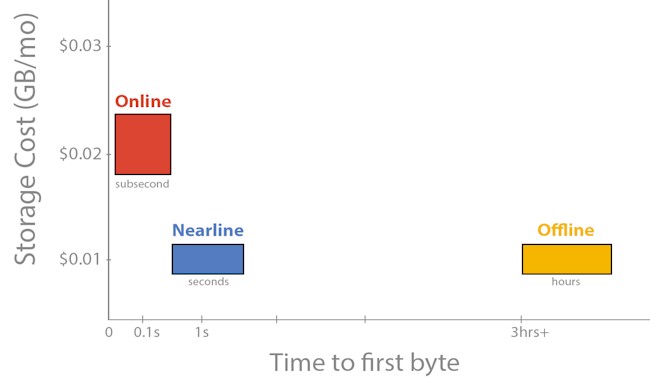
Google’s Standard Storage costs 2.6 cents per GB per month, while the DRA Storage costs 2 cents per GB per month. With Nearline Storage, the price is being slashed to 1 cent per GB per month, and between now and June 11, fees for transferring data between Google’s continents and regions are being waved. If you transfer data out of a Nearline bucket, upgrading it to Standard or DRA Storage bucket, there is a 1 cent per GB fee associated with that move. If you look at Google’s storage pricing on Cloud Platform, the data transfer fees to move between regions and continents can be quite large, but the charge to move data into the storage services is always free. The movement prices are on a sliding scale, with the price going down as you move more data, ranging from 8 cents to 12 cents per GB for moving data between regions except for China and Australia, which carry higher fees. Moving data to the China region is essentially double this rate, and moving data to Australia is almost as expensive. Moving data within a region is always free because Google can do that on the fabric in one datacenter fairly easily. Nearline Storage has a minimum of a 30 day fee, and if you delete data, Google prorates it to get its full 30 days.
Here’s the important bit: If you look into the details, it costs 1 cent per GB to read data stored in Nearline Storage. So you have to think about how frequently you are going to read a relatively cold dataset and what kind of bandwidth you might want allocated to it. The Standard and DRA Storage options do not have this read tax imposed on them. In a sense, Google is cutting the bandwidth and increasing the latency for nearline storage and assuming that most of the time you won’t be reading this data and that it will be cold. If you think you will need to access the data faster or frequently, then it probably makes sense to use DRA Storage. Just because Google is tiering its storage on the same fabric and using the same technology does not mean that you don’t have to take cost, latency, bandwidth, and frequency of access into account when you opt for one or another service on Google’s Cloud Platform. The price is directly proportional to the value offered. To Google’s credit, the prices are the same the world over for data at rest, regardless of continent or region. As Kershaw said above, storing data is cheap, moving it is expensive, so you have to do capacity planning in that regard.
The other important thing is that the same tools, processes, and APIs that are used to manipulate Standard and DRA Storage are used for Nearline Storage, so there is nothing new to learn, nothing different to do in this regard. Google also has an online cloud import tool that allows petabyte-scale data to be ingested by its storage services automatically.
Companies that are using Google Cloud Platform to build new applications will use various levels of storage services by default, but Google has set itself a much broader target. Google wants companies to use Nearline Storage much as they would tape drives and libraries, and to that end it is working with various disk array and arching companies to have Nearline Storage be a target system for arching and backup. Specifically, the soon-to-be-spun-out Veritas unit of Symantec will be supporting Nearline Storage as a target for its NetBackup 7.7, which is in beta testing now just like the Nearline Storage service is today at Google. NetApp’s SteelStore appliance, which de-dupes, compresses, and encrypts data and then pushes it out to various kinds of cloud storage, will also support Nearline Storage in the second half of this year. The Geminare disaster recovery appliance, which is used by a slew of telcos and service providers, will be able to push data to Nearline Storage, and Iron Mountain, which provides backup and vaulting, is working with Google so companies can ship disk arrays to Iron Mountain and, for a fee, have the contents of those arrays uploaded in bulk by Iron Mountain to Nearline Storage.
For nearline or cold storage, you see most of the services measure themselves in hours to minutes. We consider 2 seconds to be our compromise, as low as we will go.
The most obvious comparison that everyone makes with Google’s Nearline Storage is the Glacier storage service from Amazon Web Services. For the Glacier service, AWS stores copies of the data in multiple devices inside a single facility and across facilities to ensure high durability of the data. Data can be passed back and forth between the AWS S3 object store and Glacier, and Glacier has the same eleven 9s of durability guarantee as Google’s various storage services.
There has been much talk and speculation about the Glacier service being based on tape libraries, but some of the whispering that we have heard from people using the service is that based on its actual performance, it looks like Glacier is at least partially hosted on disk arrays. The word we hear is that Glacier uses older storage servers in the Amazon fleet, much as Google is doing with its Nearline Storage service. AWS has bulk import of data stored on corporate disk arrays shipped to its facilities and it also has Direct Connect high-speed services to link in remotely to its storage services. Importantly, the Glacier service costs 1 cent per GB per month, the same as Google’s Nearline Storage. It costs 2 cents per GB to move data from Glacier to another AWS region and anywhere from 5 cents to 9 cents per GB to move data from Glacier out to the Internet, with the price varying based on how much data you move per month. (The cost per terabyte goes down as the number of terabytes goes up.)
The Glacier service from AWS has a two-step process for accessing the data. AWS takes a request for a dataset retrieval, and within three to five hours makes that data available for download; customers have 24 hours to download it to an EC2 compute instance or an S3 bucket or it is removed from the queue. AWS offers Gateway Virtual Tape Library services for backing up on-premises data to a virtual tape library backed by S3 or a virtual tape shelf backed by Glacier. That doesn’t mean Amazon is using tape libraries behind these services, mind you.
If Amazon suddenly makes Glacier available with a 2 second to 3 second retrieval time, we will know it was not based on tape – or that Amazon has moved the Glacier service to a mix of disk and flash, just like Google did from the beginning.
Nearline Storage is going to give AWS a serious run for the archiving money, based on both its performance and its price, and Microsoft’s Azure is probably going to need a more generic cold storage service, too, if Google gets traction with Nearline Storage.

Cerebras Smashes AI Wide Open, Countering Hypocrites
We could have a long, thoughtful, and important conversation about the way AI is transforming the world. But that is not what this story is about. What it is about is how very few companies have access to the raw AI models that are transforming the world, the curated datasets …

With Cloud HPC Toolkit, Google Pursues HPC, Intel Pushes OneAPI
The people running Google Cloud can see the tides of HPC changing and know that, as we discussed only a few months ago, there is a fairly good chance that more HPC workloads will move to cloud builders over time as their sheer scale increasingly dictates future chip and system …

Datacenter Infrastructure Report Card, Q3 2023
It is hard to keep a model of datacenter infrastructure spending in your head at the same time you want to look at trends in cloud and on-premises spending as well as keep score among the key IT suppliers to figure out who is winning and who is losing. And …
Good piece. I find it interesting the degree to with AWS has managed to keep the technology used by Glacier, even at a very high level, out of the public eye. It’s admittedly not subject to the intense scrutiny that consumer products are but I’m still a bit surprised that nothing authoritative has made it into print.