

There has been a lot more churn on the November Top500 supercomputer rankings that is the talk of the SC24 conference in Atlanta this week than there was in the list that came out in June at the ISC24 conference in Hamburg, Germany back in May, and there are some interesting developments in the new machinery that is being installed.
The big news, of course, is that the long-awaited “El Capitan” system being built by Hewlett Packard Enterprise with hybrid CPU-GPU compute engines from AMD is up and running and is, as expected, the new top flopper on the rankings. And by a wide margin over its competition in the United States and the rumored specifications of exascale-class machines in China.
A substantial portion of El Capitan – we don’t yet know how big of a portion yet as we write this – with 43,808 of AMD’s “Antares-A” Instinct MI300A devices (by our math) has been tested by Lawrence Livermore National Laboratory on a variety of benchmarks, including the High Performance Linpack test that has been used to rank supercomputers since 1993. The part of El Capitan that was tested using HPL has a peak theoretical performance of 2,746.4 petaflops, which is significantly higher than the 2.3 exaflops to 2.5 exaflops that we were expecting. (This is, of course, for floating point math at 64-bit precision.) The peak sustained performance on the HPL test is 1,742 petaflops, which yields a computational efficiency of 63.4 percent. This is about the level of efficiency that we expect when a new accelerated system comes to market (our touchstone is 65 percent), and we expect in subsequent rankings in 2025 that El Capitan will bring more of its theoretical capacity to bear on benchmarks as the system works its way towards acceptance by Lawrence Livermore.
As a reminder, the MI300A was revealed alongside its MI300X sibling (which has eight GPU chiplets and no CPU cores) back in December 2023. The MI300A has three chiplets with two dozen “Genoa” Epyc cores in total and six chiplets of Antares GPU streaming multiprocessors running at 1.8 GHz. In the Cray EX systems, all of the MI300A compute engines are linked to each other with HPE’s “Rosetta” Slingshot 11 Ethernet interconnect. All told, there are 1.05 million Genoa cores and just a hair under 10 million streaming multiprocessors on the GPU chiplets in the section of El Capitan tested. This is obviously an enormous amount of concurrency to manage. But it is not crazy. The Sunway “TaihuLight” supercomputer at the National Supercomputing Center in Wuxi, China, which has been on the Top500 rankings since 2016 and is still the fifteenth most powerful machine in the world (of those tested using HPL at least) had a total of 10.65 million cores.
We will be drilling down into the architecture of the El Capitan machine separately after a briefing at SC24 by Lawrence Livermore, and we will crosslink to that story here.
Each Top500 list is a mix of old and new machinery, and as new machines are tested using HPL and their owners submit results, the less powerful machines that were on the prior list fall off and are no longer part of the Top500 universe – even if they are still being used. Moreover, many machines in the United States, Europe, and China that do not do HPC simulation and modeling as their day jobs are included in the list because companies and their OEM partners want to rig the list. Having HPL information on generic clusters is interesting, but it distorts the rankings of supposed supercomputers. To be honest, we have only really looked at the Top50 machines as true supercomputers for a long time and have sought to come up with some way to make this ranking more useful.
Back in June, we decided to only look at the new entrants on the list to try to use this as a gauge of what was happening in HPC. And we are once again going to dice and slice the November 2024 rankings and see what people have recently bought and tested. There are some interesting trends, and we intend to keep an eye on these changes in this manner from this point forward.
With the June 2024 rankings, there were 49 new machines on the Top500 list, and of the 1,226.7 petaflops of aggregate peak performance at 64-bit floating point precision across these new machines, seven new supercomputers – and they really were supercomputers doing HPC work – based on Nvidia’s “Grace” Arm server CPUs and “Hopper” H100 GPU accelerators accounted for a combined 663.7 petaflops of peak, or 54.1 percent of the additional capacity that came onto the June 2024 list. Systems using AMD Epyc processors combined with Nvidia GPUs accounted for another 8.1 percent of new compute capacity, and systems using Intel Xeon processors combined with Nvidia GPUs made up another 17.5 percent of the capacity installed between late November 2023 and early June 2024 and tested using HPL. There were another 23 all-CPU machines, which are still necessary in a lot of HPC environments for software compatibility, but the aggregate compute in these machines still only comprised 12.1 percent of all new 64-bit flops.
This time around, on the November 2024 Top500 rankings, AMD is the big winner in terms of adding capacity to the HPC base. There are 61 new machines on the list, and here they are sorted by compute engine architecture:

This time around, there are only four new Grace-Hopper systems, and they are fairly modest in size and only represent 3.8 percent of the 5,211.6 petaflops of aggregate peak performance for the new machines on the list.
There are, however, 25 new machines that have Intel Xeon CPUs on the host and Nvidia GPUs as offload engines, and these combine to have 969.6 aggregate petaflops of compute or 18.6 percent of the total new compute on the list. Interestingly, Dell built a 5.3 petaflops machine, nicknamed “IronMan,” for its own use that pairs AMD Instinct MI300A accelerators with Intel Xeon CPUs. (Why?) And there are eleven machines that have AMD Epyc CPU hosts supporting Nvidia GPU accelerators, with a total of 247.7 petaflops of peak oomph. The combined Nvidia GPU machines made up 39 percent of the total compute added for the November 2024 Top500 list.
El Capitan and three of its smaller siblings based on the MI300A hybrid compute engines just blew Nvidia away this time around, with 3,134.6 petaflops of FP64 oomph and representing 60.1 percent of the total compute coming all shiny and new to the current Top500 list. Thanks largely to the HPC6 machine being installed at Eni SpA in Italy, which we wrote about back in January and which is basically a smaller clone of the “Frontier” supercomputer installed at Oak Ridge National Laboratory in the United States, there is another 619.3 petaflops of oomph that was added in the November list from two machines based on AMD CPUs paired with AMD MI250X GPUs.
Add it all up and AMD GPUs drove 72.1 percent of the new performance added for the November 2024 rankings.
Now, let’s widen the lens out to the complete Top500 list for November and look at all 209 of the accelerated systems in the list. Take a look at how this breaks down in this pretty treemap:
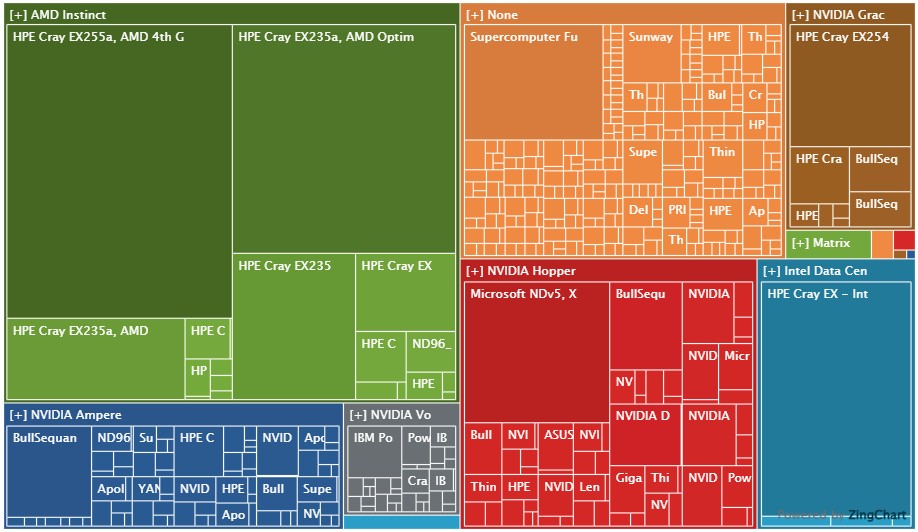
The box sizes in the chart above represent aggregate sustained performance on HPL.
That green neighborhood in the upper left is anchored by El Capitan and Frontier and includes all machines that use a combination of AMD CPUs and GPUs. Nvidia Grace-Hopper machines are in the upper right, and machines using various Nvidia GPUs are in the blue, gray, and red boxes; Intel GPU machines (the few that there are) are in the teal at the bottom right, and the burnt orange machines are CPU-only systems.
Just for fun, we sorted the 209 accelerated machines on the list by accelerator type and aggregated system counts, peak teraflops, and total cores by architecture. Have a gander at this:
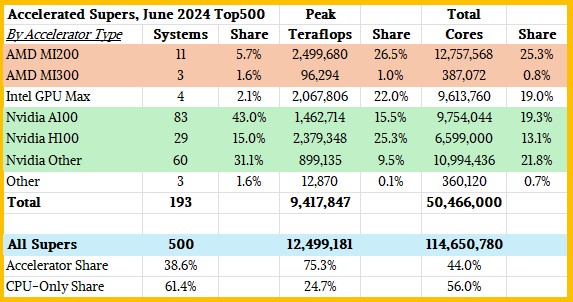
At this point, the machines using the Intel “Ponte Vecchio” Max GPU accelerators represent only four systems (1.9 percent of the 500), but 14 percent of the peak performance, and the overwhelming majority of that comes from the “Aurora” system installed at Argonne National Laboratory.
There are 183 machines that use Nvidia GPUs with any manner of hosts, and they comprise 87.6 percent of installed accelerated machines on the November 2024 list but only 40.3 percent of aggregate peak capacity at FP64 precision. There are 19 machines using AMD GPUs for the bulk of their compute, and that is only 9.1 percent of the accelerated machines. But that is 44.9 percent of aggregate peak FP64 capacity. Thanks to El Capitan, Frontier, HPC6, and sixteen other machines, AMD now has beaten Nvidia on this front on the Top500 list.
If you look across all 500 machines on the list, accelerated systems represent 41.8 percent of machines, 83.4 percent of the aggregate 17,705 petaflops, and 55.4 percent of the 128.6 million total cores plus streaming multiprocessors on the November 2024 list.
Looking At Broader Trends
It has been harder to break through the exascale barrier than many had thought, and this is due mostly to constraints on budgets and power consumption, not to any underlying technical issue. The exascale machines in China – “Tianhe-3” and “OceanLight” – have not submitted formal HPL performance results to the Top500 organizers and therefore are not ranked, but they show that if you don’t care about how much power you use or the cost of the machines, then getting exascale machines in the field a few years ago was not only possible, but done. (Our best guess from a year ago was that Tianhe-3 had a peak FP64 performance of 2.05 exaflops and OceanLight was at 1.5 exaflops.)

The bottom of the Top500 list is really having trouble keeping pace with the log plot that we expect for HPC systems historically, and we have no reason to believe that future 10 exaflops and larger machines, should they materialize, will pull up the class average. If we want to get back on the log curve, machines have to get less expensive, and they are getting more expensive even as the cost per unit of performance keeps going down.
This time around, to get onto the Top500 required a machine that had at least 2.31 petaflops on the HPL benchmark. The entry into the Top100 was 12.8 petaflops. Interestingly, the aggregate HPL performance on the list is 11.72 exaflops, up from 8.21 exaflops in June 2024, 7.01 exaflops in November 2023, and 5.24 exaflops in June 2023. Those big machines are pulling up the aggregate performance, but smaller HPC centers are not adding capacity fast enough to double it every two years across the five hundred machines on the list. This may coincide with the rise of HPC on the cloud, or not. It is hard to say without some data from the cloud builders.

The Team That Will Implement Intel’s New Vision
Intel is hosting its Vision 2025 annual event in Las Vegas this week, what we old hands used to call Intel Developer Forum back in the days when the chip maker was taking over more and more of the datacenter and had give the world a relatively inexpensive and uniform …
Nvidia Picks Up The Pace For Datacenter Roadmaps
Heaven forbid that we take a few days of downtime. When we were not looking – and forcing ourselves to not look at any IT news because we have other things going on – that is the moment when Nvidia decides to put out a financial presentation that embeds a …
Intel Adjusts, However Slowly, To New Realities In The Datacenter
While chip designer and maker Intel has a new strategy and a new executive team to implement it, it is going to take a long time for changes made last year and this year to be felt and for product and process roadmap changes to put the company into a …
I am inconsolable for the Mi300A single socket workstation that Lisa Su will not bring to market. Every morning the dawn comes with the grey disappointment that this machine is still not on the market. Why do you scorn us small ISVs so, Lisa, why? I bought AMD stock, all my machines are AMD, even my workstation GPU is a Radeon Pro VII. It is never enough, still you scorn my love.
I have asked for one for my laptop. Should I ask for two?
Three 😀
Get one for me, please. My VII is so lonely.
Please ask for three.
OK. I will ask for a baker’s dozen.
If you look at the big inflection points in the list:
mid-90s the unix workstation market brought commodity(ish) 64-bit processors at much lower cost than vector mainframes. The early 00s brought the same, but they were even cheaper desktop-derived chips. The late 00s brought multi-core processors, which again provided more push for the same price. Then the mid 10s GPUs provided more ALUs per dollar if you can port back to vectors. At the moment, no inflection in site.
—
HPC isn’t a big enough market to drive massive innovation alone. It rides the coat tails of the broader IT market. At the moment all the IT investment is into low-precision matrix math engines. One wonders when Nvidia will put out a GPU that stops supporting 64bit math?
The FP64 rate on things like A40, L40, L40s, RTX gaming cards – is abysmal already. Off the top of my head nV only does full rate FP64 on A30, A100, H?00. Not sure if there is an L30.
Great analysis! It’s good to see AMD’s EPYC quiet Zen Instinct meditating to the top of the rankings (and share) with the boisterous vigor and swashbuckling stronger swagger of the buccaneering El Capitan, no longer tip-toeing through the dancehall, but rambunctiously tap dancing over all manners of HPL, like a youthful corsair of HPC, at a blistering 1.7 EF/s!
Interesting also to observe the choreographic preparation of its likely next adversary, Jupiter, with a jazz ballet target of better than 1 EF/s, at 18 MW of effort (or 56 GF/W) … already met by the new champ. But the JETI, and the JEDI, suggest an even better telekinetic ability to effortlessly perform computational dance moves, as if floating through thin HPC air, with 68 to 73 of these GF/W! The future will be fascinating if such levitation can meet the challenges of scale, in a fullsize exaflopping ballroom blitz! Already, little ROMEO, and little Adastra 2, seem anxious to step into the dance shoes of their bigger chanllengers in this contest …
And its great seeing the Alps growing to nearly twice its former size, reaching new peaks of gut-warming performance in the Top500 waltz fondue! Nowhere else in the world could such hearty melding of HPC choreography and gastronomy be achieved, while surrounded by glaciers! 8^b
Speaking of growth, let’s not forget the conjoined MI300A triplets that sure saw some improvements since this past June. “Grizzly Adams” saw a 24% HPL improvement without (it seems) additional hardware, jumping from 19.6 to 24.4 PF/s (from 61% to 76% of peak perf, now #49). The “American Cro-Magnon of Tuolumne” grew even more to 9x of its original core structure and 10x its previous performance, now at 208 PF/s and #10. And of course, the formerly #46 “early deliveroo” has blossomed into the swashbucklingly charming #1 we all know and love!
They grow up so fast don’t they (and each with their own eventual personnality)! (eh-eh-eh)
At the end of the RFP process, there was a price below which nVidia was unwilling to go. Its the Keystone Problem, i.e. Quad-Keystone pricing is mandatory – cost is not the basis for the price.
I reckon this here Top500 is interesting, and I especially like the #20 El Dorado (for its inspiring name; better than IronMan …) but, hold your horses a bit, what about that most arduous of red-headed stepchild competitions, the lower bookend of the librarian County Fair, the red-hot picante sauce of the exhibition, the HPCG, that one doesn’t seem to have received that much love this time around, as all the MI300s just skipped it outright.
Two retirees (Summit and Trinity) made room for 3 new entries in the top 25 (CEA-HE, Gefion, Miyabi-G) but not much else seems to have moved at first sight. It’s still Fugaku, Frontier, Aurora, LUMI, Alps, Leonardo … as it was in June (no El Cap, no Eagle, no HPC6, no Tuolumne, …). Here’s to hoping that Mr.DIMM shows up soon enough to shake things up some in this here rodeo show, especially for CPU only bullriders of the Crossroads, Shaheen III, and MareNostrum 5 GPP variety, where it should shine most brightly, and even for accelerated systems if it helps them at all. Imagine if Fugaku had met Mr.DIMM, it could have 32 PF/s its way through the HPCG barrell race and be virtually untouchable (I think)!