
Effects are multiplicative, not additive, when it comes to increasing compute engine performance. And if there is one person who is not worried about how we are going to increase the oomph of those engines by two orders of magnitude in the next six years, it is Andy Bechtolsheim.
Well, Bechtolsheim doesn’t seem to be terribly worried at least. That was the impression we got from his keynote address at the Hot Interconnects 2024 conference in Silicon Valley recently, where one of the luminaries of the systems and networking businesses wondered out loud if I/O could keep up with compute for XPU designs for AI acceleration through the end of the decade. And then Bechtolsheim grabbed us all by the ears and literally ran through 38 slides in 21 minutes, making the case that we, the semiconductor industry, got this.
Given his long history of observation and innovation in the tech industry, when Bechtolsheim talks, people listen. Bechtolsheim was famously one of the founders of Sun Microsystems, and in 1995 founded Gigabit Ethernet switch maker Granite Systems with David Cheriton, which Cisco Systems bought a year later to get a better footing as it expanded from routing into switching just as the Dot Com Boom started. (Bechtolsheim and Cheriton were the first two investors in Google after getting rich on the Granite Systems sale.) In 2001, after the boom went bust, Bechtolsheim founded InfiniBand-laden system maker Kealia, which was commercialized as the Constellation system by Sun Microsystems after Sun acquired Kealia in 2004. A year later, Bechtolsheim, Cheriton, and Ken Duda co-founded Arista Networks, where they have all been since that time.
We will give you Bechtolsheim’s main points on how we can increase XPU performance by at least 50X between now and 2028 and possibly by 100X with advancements in liquid cooling.

By shrinking from 5 nanometer processes at Taiwan Semiconductor Manufacturing Co to 2 nanometers, you get a 50 percent increase in transistor density and a 33 percent increase in performance at the same power. If you multiply those out you get a factor of 2X performance increase in the same thermal envelope.
If you go one step further than Bechtolsheim did and look at Intel 14A and TSMC A14 processes expected in the 2026 timeframes, with tweaks the following year and these will be the mature processes in 2028. That will boost the chip performance to somewhere around 2.5X compared to the 5 nanometer processes at TSMC today. Given that modest performance increase, you can see why Bechtolsheim didn’t bother. 2X matters. Another 0.5X, not so much.
But, we will take it when it comes.
Whether it is 2X or 2.5X, the point is, it ain’t much for six years of time, and it is less than half of the normal rate of Moore’s Law improvements in density and performance that we saw in the 1990s and 2000s, and it will be at what we presume is much higher thermals when we get there. And so, to boost performance per XPU, the XPU has to get a lot bigger. Which is one of the reasons why the XPU system board is going to collapse down to an XPU socket.
This is how TSMC sees the situation with its System on Wafer, which Bechtolsheim cited:
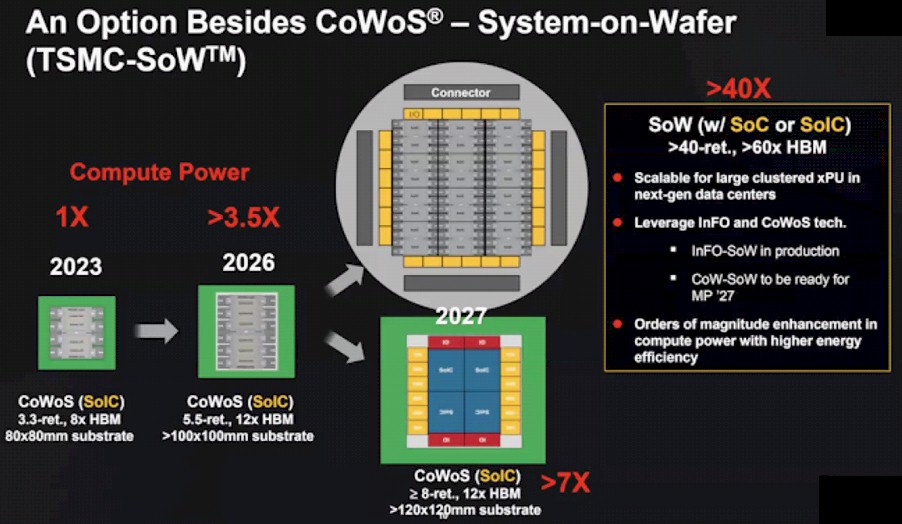
These packages are getting bigger, and their individual components are also getting hotter, so the thermal density of these XPUs is basically going to double every two years. Bechtolsheim uses a baseline of an average of 600 watts for XPUs in 2022 and 1,000 watts per XPU this year, with a jump to 2,000 watts in 2026 and an eye-watering 4,000 watts in 2028.
Anyway, add it all up and you get an XPU performance increase of 55.4X between 2022 and 2028 with a factor of 6.7X increase in heat. This does not assume any 3D stacking of computational chips as far as we know, but if there is a 3D element added to this, the density could go up by a factor relating to the number of compute stacks there are. Importantly, with clever cooling – which Bechtolsheim did not specify because it is not the purpose of his talk – you could double that again to more than 100X the compute performance compared to XPUs in 2022.

Assuming that the balance of performance types – vector and tensor – and numerical precision – from FP64 down to FP8 – stays more or less the same as the current “Hopper” H100 GPU, then by out math a projected future Nvidia GPU implemented in Intel 14A-E or TSMC A14 could be 65.4X more powerful than the H100. That lowers the gap to 100X with that liquid cooling boost Bechtolsheim refers to, which we presume means overclocking the heck out of everything and cooling every element in the system with liquid. Such an Z100 GPU – yes, we made that up – would have 345 teraflops of FP64 vector performance and 670 teraflops of FP64 tensor performance, and 9.8 petaflops of FP16 tensor performance for AI work and low precision HPC work.
Heaven only knows what such a device would cost. . . . That is also not Bechtolsheim’s department.
You might be thinking that the I/O power coming into and out of that XPU complex, with greater than 40 reticles of chip size and more than 60 banks – 60 banks! – of HBM, would be absolutely ginormous. But, as it turns out, it looks like the I/O power (basically Ethernet NICs attached to each XPU) will remain somewhere around 2.5 percent of the power consumed by the XPU itself. Here is how Bechtolsheim does the math:

It is interesting that what Bechtolsheim sees is that 800 Gb/sec Ethernet ports will just be added to the XPUs and that the power will be constant at 4 picojoules per bit as we go forward on the XPU roadmaps and the power consumed will also stay relatively constant at 2.5 percent of the total power. It is also interesting to us that it looks like I/O bandwidth per XPU will go up by a factor of 8X even as performance might go up by 55.4X for XPUs implemented in 2 nanometer processes or 65.4X if you assume a 1.4 nanometer process and a very rosy 100X if you assume more advanced cooling, but I/O bandwidth will only scale by 8X.
We strongly suspect that these XPUs will have more Ethernet ports then shown above, and perhaps ports running at 1.6 Tb/sec or even 3.2 Tb/sec if possible. But as you might imagine, it is hard to argue with Bechtolsheim about that. We did not have the opportunity we would ask for an explanation of this XPU performance to I/O gap, but we find this disparity interesting.
Here is how Bechtolsheim sees the die-to-die interfaces and high speed SerDes for getting data off the XPU chips looks:

“On the scaling the IO bandwidth for social substrate, as the substrate goes up, we get much more beachfront to provide much more IO than ever,” Bechtolsheim explained. “So assuming a terabit per millimeter beachfront for high speed SerDes today, on a single chip with 25 by 25 millimeter, that’s 100 terabits. With larger substrate chip that’s 50 millimeter by 50 millimeter, that’s 200 terabits. And for an even bigger one, a 100 millimeter by 100 millimeter multichip substrate, there would be 400 terabits – that’s with 200 Gb/sec SerDes technology. And potentially would double to 800 terabits with 400 Gb/sec SerDes, so none of these are limitations.”
“What it all comes down to is much lower power to go die, to die on the substrate, depending on how close these things are together. It could be 0.2, 0.3, or 0.4 picojoules per bit. And because you can stack the rows, you can get 5 terabits to 10 terabits per millimeter off chip. It is harder because you’re driving more distance, and you need more power and more drivers to do that. But it still seems feasible to get beyond 1 terabit per bit to perhaps even 2 terabits per bit.
None of this is actually a limitation now, and I want to highlight here the role of the high SerDes as the common interface. I call this the universal electrical interface to support any mixture of either copper cables, AOC cables, or any type of optics modules. And there’s a clear roadmap here, from the 112G shipping today, to the 224G that’s around the corner, and the 448G in the future. And there’s a matching optics module, a roadmap going from 800G gig modules today to 1,600G and 3,200G for an eight lane optics.”
As many have said and done, and as Nvidia has done most recently with the 120 kilowatt GB200 NVL72 rackscale system, you stick with copper cabling between XPUs and you drive that copper directly off the switch ASICs where possible to reduce cost. Optics are very, very expensive, and also more prone to failure. And you crank up the compute density of the racks – and therefore the thermal density of the racks – to reduce the distances between the XPUs because their AI workloads (and tag-along HPC workloads) are very latency sensitive. People are working on designing racks that can host 400 kilowatts or even 500 kilowatts for this purpose right now, according to Bechtolsheim.
The challenge is when you have to go beyond the rack and lash together a row of racks, or a whole datacenter of rows.
The good news is that an Ethernet optical transceiver running at 1.6 Tb/sec has the same number of drivers, lasers, detectors, fibers, and connectors as one delivering 800 Gb/sec. The lanes just move at 200 Gb/sec (after overhead) instead of 100 Gb/sec. The big problem is power. A transceiver using DSPs runs at 30 watts, one using the linear receive optics (LRO) approach is 20 watts, but linear drive pluggable optics (shortened to LPO for some reason) is only 10 watts. For a 102.4 Tb/sec switch, that works out to 800 watts using LPO, 1,600 watts using LRO, and 2,400 watts using DSPs.
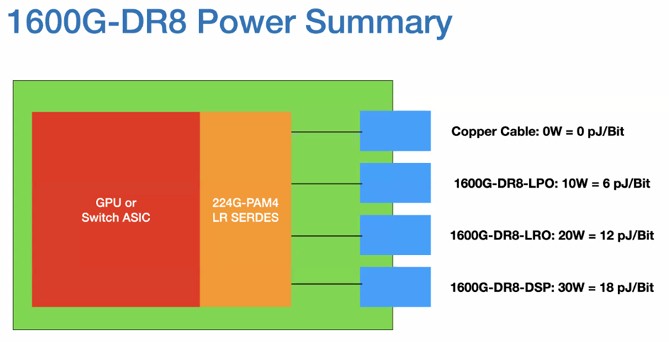
You can see why Bechtolsheim has been a champion of the LPO approach, which uses the same approach as near package optics or co-packaged optics, but keeps all of the circuitry in a pluggable module instead of trying to cram in into the switch box.
Here are the feeds and speeds of micro LED optics according to Bechtolsheim:
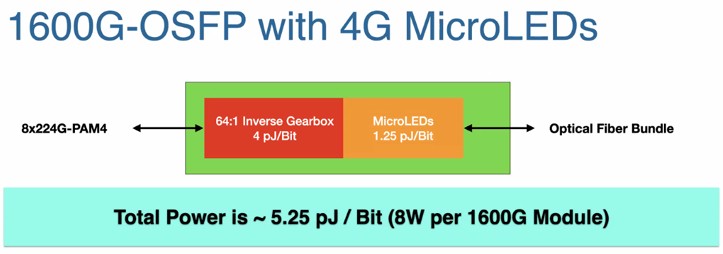
And here is how a 1.6 Tb/sec OSFP module based on 32 Gb/sec NRZ microrings stacks up:

The latter is a little bit more power than the micro LED approach and about the same power as the LPO pluggable modules.
These latter two are very exciting technology approaches (which we will be drilling down into separately), but Bechtolsheim is worried about high volume manufacturing, which drives down cost. And you need a design win from a hyperscaler or a cloud builder to get started these days, and those are hard to come by.
Bechtolsheim did a little bit of history, reminding everyone that IBM did co-packaged optics for the Power 775 supercomputer server node that was supposed to be at the heart of the original “Blue Waters” supercomputer that was designed for the National Center for Supercomputing Applications at the University of Illinois and whose development was funded by the US Defense Advanced Research Projects Agency more than a decade and a half ago.

IBM launched the Power 775 server and its optical interconnect back in 2010, and pulled the plug on its implementation of the Blue Waters machine in August 2011. Back them, our guess is that IBM would have to supply a machine with 2 petaflops to support the 1 petaflops of performance on the High Performance LINPACK test that NCSA required as part of the contract for Blue Waters. Our guess is that this machine would have cost maybe $300 million to build, and it would not necessarily have been profitable for Big Blue. (Everything on this machine was liquid cooled, by the way, and the node is truly an engineering feat.) When IBM pulled the plug, Cray bagged a $188 million deal with NCSA to build a hybrid CPU-GPU system that took the Blue Waters name. And from that point forward, NCSA stopped running HPL on its machines and stopped participating in the Top500 supercomputer rankings.
The point about Blue Waters is that manufacturability matters. CPO has been around a long time, and it is difficult to manufacture and difficult to get around failures in the lasers used to drive signals when they are embedded in devices that use them.
Bechtolsheim drove the other important point – about thermals for the network – home by cooking up some power comparisons between DSP optics and LPO optics for a cluster with 100,000 XPUs. Take a look:

The XPU in Bechtolsheim’s thought experiment has an aggregate network I/O bandwidth of 25.6 Tb/sec, which is equivalent to a common, midrange Ethernet switch ASIC these days, by the way. This is broken down into 16 ports running at 1.6 Tb/sec to calculate the number of optical transceivers. To interconnect 100,000 XPUs would require a mind-numbing 6.4 million optics.
If you do the math, LPO optics will burn 64 megawatts – a little less than three times what the entire “Frontier” supercomputer at Oak Ridge National Laboratory burns, with its 22.7 megawatts. With DSP optics, the power consumed is 192 megawatts, or three times as much as with LPO optics. And that is nearly half of the 400 megawatts that those 100,000 XPUs are expected to burn.
“Needless to say, nobody would deploy DSP-based optics for this application because you can’t afford it,” says Bechtolsheim. “So we need linear optics.”
It is hard to argue that point, even if we are excited by the possibilities of micro LED approaches. And we will let those working on it make those arguments soon here at The Next Platform.


Intel Hopes To Accelerate Datacenter And Edge With A Slew Of Chips
It is hard to say how many Xeon and Xeon SP CPU sales have been obliterated by Nvidia GPUs, but the number is a big one. And that is why Intel finally came around to the idea that GPU compute was not just going to be a niche thing, but …
Compute Is Easy, Memory Is Harder And Harder
What good is a floating point operation embodied in a vector or matrix unit if you can’t get data into fast enough to actually use the compute engine to process it in some fashion in a clock cycle? The answer is obvious to all of us: Not much. People have …
AI Is A Modest – But Important – Slice Of TSMC’s Business
Given the exorbitant demand for compute and networking for running Ai workloads and the dominance of Taiwan Semiconductor Manufacturing Co in making the compute engine chips and providing the complex packaging for them, you would think that the world’s largest foundry would be making money hands over fist in the …
HotGauge: Methodology for Characterizing Advanced Hotspots in Modern and Next Generation Processors
https://youtu.be/61VJ7KJAgnM?si=Xn9JYS_OcBZf6MmQ
Thinking Oscillator for adiabatic computational circuitry (US11671054)
Granted Patent | Granted on: 2023-06-06
Not shrinking get us ‘999-Exa’ tm Earth ICT, SPC
SWOT it get a license. https://labpartnering.org/patents/US11671054
An interesting Hot Interconnects keynote by Andy Bechtolsheim, with insightful, provocative, and optimistic bits. A more ocnservative analysis might estimate that performance increases by 2x in 2 years (4x in 4 years), and power consumption goes up by 2x in 4 years, so that power efficiency goes up by 2x in 4 years as well (based on 3.3x perf in 3 years from A100 to H100, with 1.75x TDP (3x in 6y), and 2x perf in 2 years from MI250x to MI300x, with 1.5x TDP (2x in 4y)).
So, possibly 12 years (2036, conservative) to the 64x perf Z100, at around 5 kW, and 100x perf with liquid cooling … which is still WoW! That’ll be 200 ExaFlops of FP64 HPC, or 2 ZettaFlops in MxP, all at approx 200 MW (save some major improvement in efficiency) … with all calculation errors mine, of course.
The cost and power advantages of LPO should clearly remain.
Oh well, I’m with you I think, seeing how it took 11 years to go from TF to PF (97-08), and 14 years from PF to EF (08-22), one can imagine 17+ years to ZF (2039+), with 200 EF in-between somewhere, maybe 2036. You deserve that $16-$20 billion net worth IMHO … eh-eh-eh!
I’m bookmarking this page now; will check back in 2028, 2036, and 2039 (for sure!)! 8^b
Me, too!
In 2023, the claim was that LPO could cut power by 50% by eliminating the DSP. Now it’s 67%? There’s not a lot of field data obviously. Was there any explanation? Great extrapolation on the explosion of beachfront real estate.