

Training AI models is expensive, and the world can tolerate that to a certain extent so long as the cost inference for these increasingly complex transformer models can be driven down. Training is research, development, and overhead, but inference is about making money – either literally by finding new revenue or by eliminating costly people from the workflows that comprise an enterprise or other kind of institution.
Given this, there has been more focus on inference hardware and its costs in recent years, particularly since transformer models require very heavy nodes to provide low response time – something on the order of 200 milliseconds, which is the attention span of the average human as well as that of a gnat.
Artificial Analysis, which has put together a fascinating independent analysis of AI model performance and pricing, published an interesting post on Xitter that had as a thesis that AMD’s “Antares” Instinct MI300X GPU accelerators, announced last December and now shipping, were going to be sitting pretty compared to Nvidia iron when it comes to running inference for the recently announced Llama 3.1 405B model from Meta Platforms.
As you well know, we think that given the open source nature of the PyTorch framework and the Llama models, both of which came out of Meta Platforms, and their competitiveness with the open AI frameworks and closed source AI models created and used by other hyperscalers and cloud builders, we think that the PyTorch/Llama combination is going to be very popular. And it is no accident that AMD’s techies have made sure that the Antares GPUs have been optimized first for this stack.
Here was the simple premise: How many GPUs does it take to house the Llama 3.1 weights for the 405 billion parameter variant, including those weights and memory overhead? Take a look:

This comparison just looks at the AMD MI300X versus the original Nvidia “Hopper” H100, and refers to the Hopper H200 GPU announced in November 2023 as a future product, and therefore it is not included in the chart just like the “Blackwell” GPU that Nvidia announced in March of this year and which is not yet shipping in volume on its B100 and B200 form factors.
Because those numbers are hard to read, it takes 810 GB, according to Artificial Analysis, to load the Llama 3.1 405B model weights and another 243 GB to leave 30 percent overhead room at the FP16 processing that is native to the Llama 3.1 model. That is 1,053 GB of total capacity.
If you drop down to FP8 precision on the math (by metaphorically squinting your eyes to fuzz up the data), the data all shrinks by half, and it only takes 405 GB for the weights and 121.5 GB for the overhead. Which means you can fit it into half as many compute engines. And if you drop it to FP4 precision, squinting your eyes even further, you cut the amount of HBM memory in half and also the number of GPUs in half that you need because the data is half again smaller. Again, you sacrifice some accuracy in responses from the LLM for this reduction in data precision.
Using the commonly available Hopper H100 GPUs and the mere 80 GB of HBM memory available on them, you need two eight-way HGX cards to fit the Llama 3.1 405B weights and overhead. (Actually, you would need 13.2 GPUs, but practically speaking, you have to buy them in blocks of eight.) If you drop to FP8 precision, you can fit it all on one server system with a single HGX board with eight Hopper GPUs.
A system using a single AMD MI300X eight-way GPU board can easily fit the model weights for the Llama 3.1 405B model. In fact, it would only take 5.5 GPUs to do it if you could buy them that way. The other way to look at it is that with right MI300X GPUs it would be possible to run inference with a future Llama model with around 590 billion parameters (assuming the weights and overhead scale linearly), all within the confines of the eight-way system board’s shared memory.
We didn’t like that the H200, B100, and B200 GPUs were not in the comparisons, and we also always believe that money is a factor that has to be considered along with performance and memory capacity. So we took the idea from Artificial Analysis and ran with it in this table:
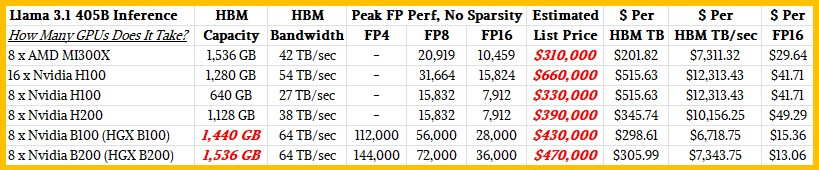
Before getting into that table, there is something odd in the Nvidia specs for the B100 and the B200 we need to point out. The Nvidia Architecture Technical Brief shows the HGX B100 and HGX B200 system boards will have up to 1,536 GB of memory, which is 192 GB per B100 GPU. But the DGX B200 spec sheet says it will only have 1,440 GB of HBM memory, which is 180 GB per B100 GPU. (We could not find a spec sheet for the DGX B100 server.) We think that the B100 and B200 will have different memory capacities, just like the H100 and H200 from the Hopper generation did, and we do not believe the B200 will have lower memory capacity than the B100. So, for the moment, we are predicting that the B100 will have 180 GB each in the HGX B100 system board and the B200 will have 192 GB each in the HGX B200 system board, and have configured our hypothetical GPU systems with this in mind.
Speaking of which. At the prices of GPUs these days, we think that machines loaded up with GPUs will be used for both LLM inference and LLM training. And so the base configurations of the servers we would build with any of these eight-way GPU motherboards are pretty hefty, with dual X86 CPUs with lots of cores and lots of main memory (2 TB), lots of networking bandwidth for east-west traffic (eight 200 Gb/sec cards), and lots of local flash storage (6.9 TB). We think a base machine configured thus minus the GPUs costs around $150,000.
For GPU pricing, we used the following:
- AMD MI300X 192 GB: $20,000
- Nvidia H100 80 GB: $22,500
- Nvidia H200 141 GB: $30,000
- Nvidia H100 180 GB: $35,000
- Nvidia H200 192 GB: $40,000
The resulting system prices, adding the GPU boards to the base X86 iron, are meant to be illustrative, not a shopping guide. Real prices are subject to demand pressures and time issues, and people often pay a lot more for their GPUs. And for inference, you might be able to get by with a lot less networking and lighter memory and flash on the host server. But, in a pinch, when you tried to do training on it, you would be hampered by the light configuration.
And so, here is what we think. Yes, HBM memory capacity will drive the configuration of the inference server, and you want to buy as few GPUs as possible at these prices while leaving yourself a little headroom for model growth.
As such, you want to look at the cost per unit of HBM memory, and as you can see, at the system level, if our base pricing for AMD and Nvidia GPUs is roughly correct, then AMD will have a significant advantage with the MI300X.
Some AI workloads are going to be more sensitive to the memory bandwidth than they are to the memory capacity or the calculating capacity at any given precision. And on that front, we expect that systems based on the MI300X will be on par, in terms of cost per unit of memory bandwidth, with those using the Nvidia B200 GPU accelerators. A system based on Nvidia HGX B200 boards will deliver 51 percent more bandwidth at the same 1.5 TB of memory for 51 percent more money. (We arrived at those two numbers independently. We did not guess at the price hike would match the memory bandwidth hike. We shall see what Nvidia and the market actually does.)
Interestingly, systems using the B100, if the pricing works out as we expect, will offer better value for dollar for memory capacity and memory bandwidth, but the B100 is not expected to offer a commensurate level of computational performance. The FP4 numbers for the B100 and B200 are real, and the B200 is expected to have 28.6 percent higher performance for reasons Nvidia has not explained. The 6.7 percent higher memory capacity the B200 might have compared to the B100 will help, but it looks like the B100 will have fewer streaming multiprocessors activated than the B200 when it starts shipping later this year.
The interesting thing is that in terms of raw peak floating point specs, the Nvidia B100 will smoke the MI300X, and the B200 will do even better, as you can see. It is roughly twice better bang for the buck to the advantage of Nvidia, comparing the B100/B200 to the MI300X at peak FP16 performance levels.
The AMD MI300X, however, which is shipping now like the Nvidia H100 and H200, offers anywhere from 41 percent to 66 percent better performance per dollar than the H200. But note well: On real Llama 2 70B inference tests, the H200 did 1.9X better than the H100, according to benchmarks Nvidia put out during the H200 launch. So be careful of the ratios of flops to memory capacity and flops to memory bandwidth, depending on what you are buying your GPUs for. The AMD MI300X and the Nvidia H100 and H200 are in roughly the same ballpark on these two ratios, but the Nvidia B100 and B200 have a lot more flops per memory capacity and a lot more flops per memory bandwidth, and there is a chance that because of memory constraints, on real workloads, that performance may not be realized.
So test, test, test before you buy, buy, buy. And that goes for the AMD MI325X coming later this year with 288 GB and 6 TB/sec, the MI350 coming next year with 288 GB and unknown memory bandwidth, and the MI400X coming in 2026, too.


Future Proofing Inference Servers With PCI-Express Switches
At this point in the history of datacenter systems, there can be no higher praise than to be chosen by Nvidia as a component supplier for its AI systems. Which is why upstart interconnect chip maker Astera Labs, which is taking on the likes of Broadcom and Marvell for PCI-Express …

Who Will Build Europe’s First Exascale Supercomputer – And With What, And Why?
Exascale supercomputing is just as important to Europe as it is to the United States and China, but each of these geopolitical regions on Earth has its own way of developing architectures, funding their development and production, and figuring out where the best HPC centers are to host such machines …

AMD Datacenter Sales Break Through $1 Billion In Q3
Here is a moment that Lisa Su, the chief executive officer who has lead the team that brought AMD back into the datacenter with the vigor the market needs, has been waiting six years for. In the third quarter ended in September, AMD’s datacenter CPU and GPU business broke through …
The Llamas are going to carry AMD to the top of the mountain. I bet all this PyTorching is making Nvidia feeling uncomfortable.
The honeymoon of locking the market with CUDA will soon be over.
“Using the commonly available Hopper H100 GPUs…”
As well, haven’t you heard? The more you spend the more you save!
The more you spend, the more you get, but for sure, the more you spend.
So, AMD is better on this as well and cheaper, so why is there so much talk of everyone buying Nvidia instead of AMD??
It’s all about supply.
No, it’s not because of 2 things:
1. You and everyone else only check on inferencing and ignore that maybe customers want to do training as well. Public AI models are nice but using company specific data for training is an untapped market which will benefit primarily Nvidia.
2. Every benchmark so far is on 8x to 16x GPU systems and therefore a bit strange. How does benchmarking look like at scale? How does AMD vs. Nvidia perform if you combine a cluster with 100s or 1000s of GPUs? Everyone talks about their 1000s cluster GPUs and we benchmark only 8x GPUs in inferencing. It’s time for AMD to present itself at MLPerf. Until then it’s all cherry picked.
The reason this is the case is because the weights for a large model, depending on the size, fit in 8, 16, or sometimes 32 GPUs when it comes to inferencing. Hence, that is the comparison. Training is tens of thousands of GPUs trying to do one thing at once. Inference is like really freaking huge Web serving, conceptually. You get a big enough server to run the Web server and Java or whatever, and you round robin across as many as possible to serve the number of streams you have. So, I don’t agree.
They don’t spend CapEx on one thing as you seem to repeat an AMD talking point. The folks who cut big checks for clusters want to make sure the stuff they are buying is not a one trick pony. That is the selling point for Nvidia despite all the claims by AMD. BTW, why don’t you ask them to submit these claims to MLPerf?
Tim, as much as I do not want to shoot the messenger you are much more than a messenger (hopefully).
Cool analysis! If I read well, today, MI300X, trundles, tramples, and trounces H100/200, but tomorrow, B100/200 will assert commensurate competitive riposte … to be followed by substantial throws, pins, chokes, jointlocks and ippons by MI325X/350/400X. This is competition at its best (eh-eh-eh)!
I’m sorry, but this article is just elucidation of an AMD talking point: We have more memory per GPU. Great! We all get it, it’s been a non-stop message since MI300 launch hundreds of articles ago. It’s a single metric, and the message could have been published with just an a single image of the top chart.
Where are the performance numbers, across a variety of applications and hardware configurations, just like every other piece of high tech hardware that makes a claim?
AMD’s lack of laying the cards on the table (with MLPerf for example) is a cynical attempt to stake a high ground narrative while no one (press) holds them to account.
Based on link backs to this article it’s working.
I think that’s a little unfair. I added pricing to it to show the relative cost, and if and when I have performance data for Llama 3.1, I will add that. It was food for thought, not a meal.
I don’t believe AMD supports FP8 though?
Is the **No** Sparsity FP peak correct for nVidia ?
https://resources.nvidia.com/en-us-blackwell-architecture/blackwell-architecture-technical-brief?ncid=no-ncid
Table 3, All petaFLOPS and petaOPS are **with Sparsity** except FP64 which is dense.
FP8 is officially supported in ROCm 6.2.