

Ultimately, every problem in the constantly evolving IT software stack becomes a database problem, which is why there are 418 different databases and datastores in the DB Engines rankings and there are really only a handful of commercially viable operating systems. But what if the operating system is the problem?
We are so used to thinking of the operating system as the foundation of the system that this kind of talk seems more weird than it does heresy, but make no mistake. When Michael Stonebraker and Matei Zaharia and a team of techies from the Massachusetts Institute of Technology and Stanford University are involved in creating a new operating system, it is definitely going to be heresy.
Stonebraker says that the spark for the idea for DBOS, which is short for database operating system, came when he was listening to a talk by Zacharia, who among other things was the creator of the Spark in-memory database while at the AMPLab at the University of California Berkeley and the co-founder and chief technology officer of Databricks, which has commercialized Spark.
“This talk was at Stanford three and a half years ago,” Stonebraker tells The Next Platform. “And Matei said that Databricks was routinely orchestrating a million Spark subtasks on sizeable clouds and that Databricks had to keep track of scheduling a million things. He said that this can’t be done with traditional operating system scheduling, and so this was done out of a Postgres database. And then he started to whine that Postgres was too slow, and I told him we can do better than that.”
Stonebraker, who is an adjunct professor at MIT and a member of the vaunted CSAIL research team that has brought so many innovations to information technology, would know.
Like all of the other database pioneers from the late 1970s and early 1980s, Stonebraker read the early relational data model papers by IBMer Edgar Codd, and in 1973 started work on the Ingres database while at Berkeley, and created the Postgres follow-on to it. Stonebraker was chief technology officer at relational database maker Informix, was one of the researchers on the C-Store shared-nothing columnar database for data warehousing (which was eventually commercialized as Vertica), and was part of the team that created H-Store, a distributed, in-memory OLTP system (which was eventually commercialized as VoltDB). More recently, Stonebraker led an effort to create an array-based database called SciDB that was explicitly tuned for the needs of technical applications, which think in terms of arrays not tables as in the relational model.
So Zaharia saying that Postgres performance was poor was like calling Stonebraker’s child a bit slow. . . .
And rather than fight about it, Stonebraker and Zaharia teamed up to create an operating system based on a database rather than a database bolt on for an operating system.
In an interview with The Next Platform back in August 2017, we talked to Stonebraker about how hardware drives the shape of databases as the storage hierarchy changes, but this might be a case where a database operating system kernel might start driving the shape of the hardware. (We will see how this DBOS idea takes off.) After that Stanford talk, Stonebraker and Zaharia played around with ideas, and built a prototype operating system on VoltDB to prove it would work; then they founded a company to commercialize the idea in April 2023 and secured $8.5 million initial seed funding to start building the real DBOS. Engine Ventures and Construct Capital led the funding, along with Sinewave and GutBrain Ventures.
What is breaking the operating system, and making companies like Databricks do weird bolt-ons of Postgres to maintain the state of Spark clusters outside of an operating system, is that the state of an operating system has gone up by five or six orders of magnitude in the more than five decades that Stonebraker has been programming. He gives a personal example. Back when Stonebraker was tooling around with Unix in 1973 on a DEC PDP-1141, it had 48K of memory and 20 MB of disk capacity. DBOS was tested early on running on the MIT Super Cloud, a cluster with 32,000 cores, a few terabytes of main memory, and many terabytes of secondary storage. There is just so much more stuff to keep track of, and so many more services running on that stuff, too.
“The state that the operating system has to keep track of – memory, files, messages, and so on – is approximately linear to the resources you have got,” says Stonebraker. “So without me saying another word, keeping track of operating system state is a database problem not addressed by current operating system schedulers. Moreover, OLTP database performance has gone up dramatically, and that is why we thought instead of running the database system in user space on top of the operating system, why don’t we invert our thinking 180 degrees and run the operating system on top of the database, with all of the operating services are coded in SQL?”
All of the investors in DBOS said that using VoltDB at the heart of this thing was not possible because it was not open source (there would seem to be an easy fix for that) and that because DBOS had to be open source, the underlying database would have to be, too.
So the decision was made to use the FoundationDB distributed key-value store as the scheduling core of the first iteration of DBOS. FoundationDB was created Nick Lavezzo, Dave Rosenthal, and Dave Scherer, which was released in 2012, acquired by Apple in 2015, and open sourced by Apple in 2018. FoundationDB is a blazingly fast NoSQL database, which means that it does support the ACID properties of a relational database but which does not offer full SQL compliance. (Stonebraker tells us that DBOS eventually will do that, which seems to imply the underlying database engine will change.) Right now, DBOS has been tested running across 1,000 cores running applications coded in TypeScript, but Stonebraker says there is no reason to believe that DBOS can’t scale across 1 million cores or more and support Java, Python, and other application languages as they are needed by customers.
The first iteration of DBOS runs on Amazon Web Services and uses the Firecracker microVM service, itself a stripped down KVM hypervisor running on a stripped down Linux microkernel, to create the user space for FoundationDB to run within. So technically, there is still Linux underneath DBOS. But nothing like the full blown Red Hat Enterprise Linux or SUSE Linux Enterprise Server that companies deploy or the homegrown, full-blown Linuxes that the hyperscalers and cloud builders have created for their own use. Stonebraker and Zaharia are working on ports to the Microsoft Azure and Google Cloud infrastructure, and it will be interesting to see how this is done. . . .
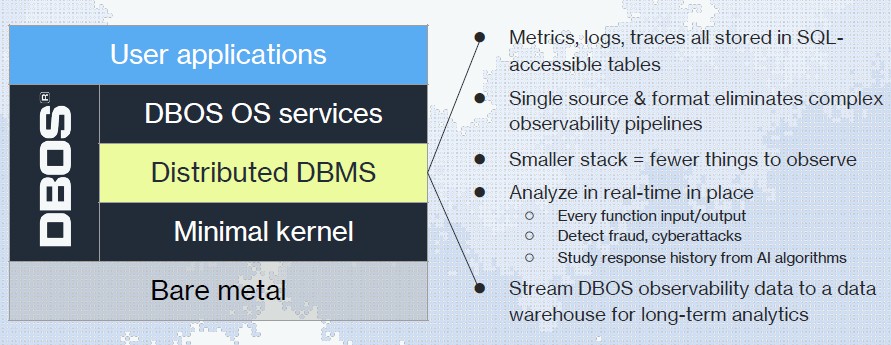
The point is, there is a minimal kernel underneath FoundationDB, which has device drivers, memory management, interrupt handlers, and some basic data movement functions, and the database services are written in TypeScript and their state tables can be queries in SQL. (Again, we would have preferred a relational database where DBOS services are written themselves in SQL, because that is a cleaner and funnier story.)
Stonebraker says that what he and Zaharia have really created is a transactional serverless platform that can run stateful applications. For now, DBOS can give the same kind of performance as that full blown Linux operating system, and thanks to the distributed database underpinnings of its kernel, it can do things that a Linux kernel just cannot do. And it can do all of these things without a full Linux OS and without Kubernetes containing things, and without having to bolt Postgres onto the side of the database middleware.
One is provide reliable execution, which means that is a program running atop DBOS is ever interrupted, it starts where it left off and does not have to redo its work from some arbitrary earlier point and does not crash and have to start from the beginning. And because every little bit of the state of the operating system – and therefore the applications that run atop it – is preserved, you can go backwards in time in the system and restart the operating system if it experiences some sort of anomaly, such as a bad piece of application software running or a hack attack. You can use this “time travel” feature, as Stonebraker calls it, to reproduce what are called heisenbugs – ones that are very hard to reproduce precisely because there is no shared state in the distributed Linux and Kubernetes environment and that are increasingly prevalent in a world of microservices.
Here is what the time travel screen looks like:
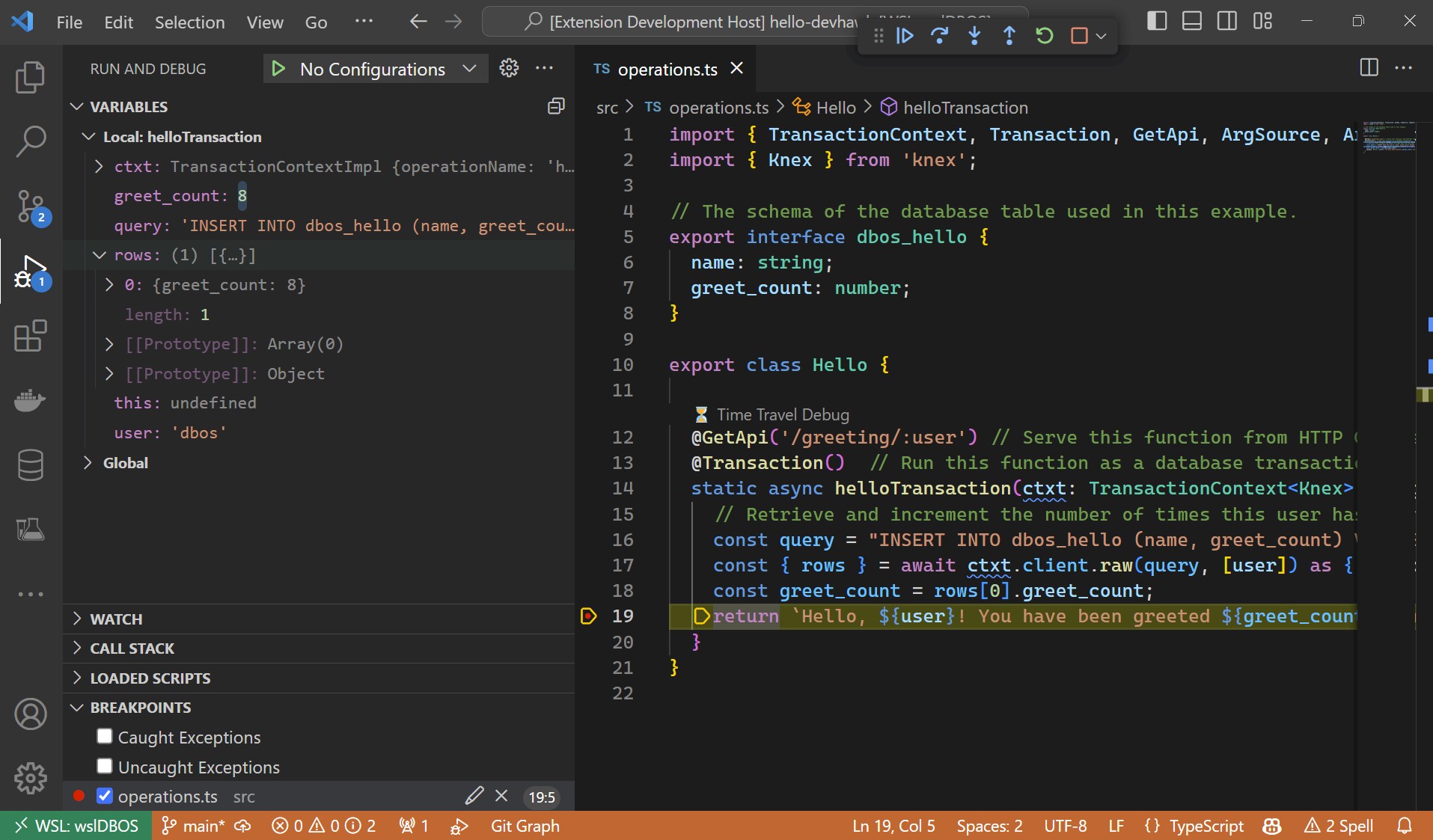
This time travel feature also lets you run new code against historical system state.
The other benefit of the DBOS is that it presents a smaller attack surface for hackers, which boosts security, and that you analyze the metrics of the operating system in place since they are already in a NoSQL database that can be queried rather than aggregating a bunch of log files from up and down the software stack to try to figure out what is going on.
By the way, if you look on GitHub to take a gander at the DBOS code, you will find code, but we do not believe it is for this particular instance of DBOS. It is for a DBOS project that was started by Peter Kraft and Qian Li, who were PhD students at Stanford and who we are guessing now work on the formal DBOS project.
DBOS Cloud, as the formal product is called, comes in two versions at the moment. There is a free version that can use the RDS Postgres service at AWS as an application datastore running on the db.ts.micro instance size only, and it is scaled to handle 1 million service calls per month. (We assume that means API service calls). This free tier holds operating system log data for three days and is allowed to have one developer on the account. Support is through Discord and the SDK only works with TypeScript and Postgres.
There is also a custom tier for DBOS, which we presume costs money, that can use other databases and datastores for user application data, stores more than three days of log data, can have multiple users per account, that adds email and Slack support with DBOS techies, and that is available on other clouds as well as AWS. Being a startup, new clouds, new languages, and human tech support will happen as enough people ask for them. No startup, not even one started by Stonebraker and Zaharia, can boil the ocean.
In a way, you really need to think of DBOS as a competitor to Linux, Windows Server, or Unix but to the AWS Lambda serverless function as a service stack. Stonebraker and Zaharia do:
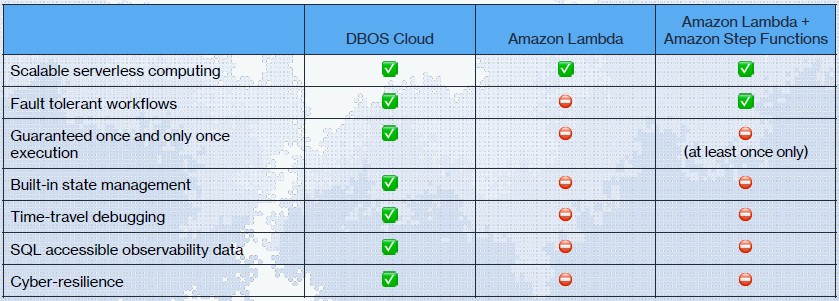
One last thing. We know of operating systems that had an intimate relationship with a database, but this twist is actually a new one in that the operating system kernel/schedular is itself largely a database and services are created in database languages.
For example. IBM’s System/38 and AS/400 minicomputers had a relational database at the heart of the operating system and in fact the database was the only file system allowed on these machines from 1978 through 1996, at which time IBM pulled the database out of the operating system and added in the OS/2 Parallel File System to give a POSIX-compliant, ASCII formatted file system for the AS/400. (Which is known today as the IBM i proprietary operating system.) The Pick operating system similarly had an integrated database, too. And of course, the “Longhorn” version of Windows Server 2008 was supposed to have the WinFS file system, which was based on a relational database, embedded in it, but that effort was spiked a decade and a half ago.
Which brings us to that one last thing: There is no reason why DBOS cannot complete the circle and not only have a database as an operating system kernel, but also have a relational database as the file system for applications.

Why Nvidia Should Acquire SUSE
Here we are, on the Friday before the flagship GPU Technology Conference hosted by Nvidia is set to kick off. And we are without a doubt excited in anticipation of what we conjecture will be a deluge of compute and networking hardware and puzzling over what this Omniverse really means …
Meta’s Velox Means Database Performance Is Not Subject To Interpretation
A decade and a half ago, when Dennard scaling ran out of gas and many of us were starting to first think about what the end of Moore’s Law might look like should that day ever come, a bunch of us were kicking around what it might mean. People brought …
Nobody Owns Linux, But You Can Pay For It – Or Not
There is nothing quite like the open source community to demonstrate the principles of freedom, democracy, and meritocracy – and the difficulties of bringing those principles to bear and keeping them pure when money is involved. Open source software is not just about having access to source code, but that …
Shades of the pick OS?
Well, yes. I said as much at the end.
And it can do all of these things without a full Linux OS and without Kubernetes containing things, and without
something missing??
I guess it all comes down to the services you want and the languages and databases you want to run atop this. I am sure the support matrix is small at the moment. But that will change. These guys are not some newbie jokers.
It sounds like DBOS is built on top of a custom microkernel. Even with a narrowly focused hardware platform, I suspect a cloud provider will have trouble achieving similar performance to Linux, especially given all the industry support for high speed interconnects, storage, NUMA and accelerators in Linux.
Rather than replacing Linux, I feel a better approach would be replace the GNU userland like Google did with Android or ChromeOS. The changes needed to the Linux kernel to build DBOS on top could then be fed upstream like cgroups were.
The comment from erik refers to the text itself – in the original text the paragraph stops after the word ‘without’. Something has been omitted from the end of that sentence.
AHHHHHHH. HA! You can tell where the phone rang.
You did not mention novell and it’s bindery or later novell and it directory. The novell Directory was a relational database that was the core of novell’s distributed operating system.
“And it can do all of these things without a full Linux OS and without Kubernetes containing things, and without having to bolt Postgres onto the side of the database middleware.”
I noted that you did, as I started my career on Pick and its various implementations, such as Prime Information, uniVerse (on Linux), and Revelation (on Windows). It still annoys me that Stonebreaker takes the credit for columnar DW when Sybase IQ was commercially successful a full decade before C-store and columnar storage papers go back to the 60s.
Yes, this is just a version of pick os.
I was going to say PickOS, and btw, i teach OS at CWRU.
Yes, I immediately thought of Pick too. I wrote apps using Advanced Revelations in the 90s and read that it was based on Pick, then read a bit about Pick’s approach. Great idea here, of nothing else but innovative thinking at play. Also once a Novell CNE and mourn the loss of the Bindery and NDS initiative.
The wheel has been reinvented.
Both pick and mumps were doing this in the 60s
Here are a couple of papers on DBOS:
Michael Cafarella, David DeWitt, Vijay Gadepally, Jeremy Kepner, Christoforos Kozyrakis, Tim Kraska, Michael Stonebraker, Matei Zaharia, (2021). A Polystore Based Database Operating System (DBOS). In: Gadepally, V., et al. Heterogeneous Data Management, Polystores, and Analytics for Healthcare. DMAH Poly 2020 2020. Lecture Notes in Computer Science(), vol 12633. Springer, Cham. https://doi.org/10.1007/978-3-030-71055-2_1
and
Athinagoras Skiadopoulos, Qian Li, Peter Kraft, Kostis Kaffes, Daniel Hong, Shana Mathew, David Bestor, Michael Cafarella, Vijay Gadepally, Goetz Graefe, Jeremy Kepner, Christos Kozyrakis, Tim Kraska, Michael Stonebraker, Lalith Suresh, and Matei Zaharia. DBOS: A DBMS-oriented Operating System. PVLDB, 15(1): 21-30, 2022. https://doi.org/10.14778/3485450.3485454
They provide further motivation and design choices that differentiate DBOS.
“And because every little bit of the state of the operating system – and therefore the applications that run atop it – is preserved, you can go backwards in time in the system and restart the operating system if it experiences some sort of anomaly, such as a bad piece of application software running or a hack attack.”
->I think that this is somehow wishful thinking (it really is and would be nice to have somehting like this), but it assumes that the bad application or hack attack did not get their hands on the OS parts itself to alter them, which I think will never be the case.
Timothy, you wrote: “IBM’s System/38 and AS/400 minicomputers had a relational database at the heart of the operating system and in fact the database was the only file system allowed on these machines from 1978 through 1996, at which time IBM pulled the database out of the operating system and added in the OS/2 Parallel File System to give a POSIX-compliant, ASCII formatted file system for the AS/400.”
Nonsense! IBM never “pulled the database out of the operating system.” What IBM did in 1996 was to give it a name, “DB2/400” to make it more visible. “Db2 for i” still has much of its functionality integrated deeply within the SLIC kernel. You have written about AS/400 -> iSeries -> IBM i and OS/400 -> i5/OS -> IBM i for many years, so I am shocked to see such misinformation from you.
You also wrote: “The Pick operating system similarly had an integrated database, too. ”
The Pick system was always a multi-user database system, with only a bare minimum of an “OS” enough to run the PICK database on a given hardware platform. Much later, it evolved to allow users to run a PICK database on various Unix and Linux systems.
Of greater interest, in my opinion, IBM’s S/38 CPF (and its successors OS/400 and IBM i) and the PICK Systems evolved starting in the 1970s, and both use a “single-level storage” view that maps all available disk space into a very large virtual address space for the users and applications running on those systems. Single-level storage may well be the most significant feature with regard to supporting an integrated multi-user database.
> The Pick system was always a multi-user database system, with only a bare minimum of an “OS” enough to run the PICK database on a given hardware platform.
Think, if I’ve got it right, of CP/M or MS-DOS. They provided a minimal set of hardware manipulation routines. That they happened to come with a bunch of useful programs is by the bye. Each program you ran had SOLE control of the machine.
The Pick database was the same. It had sole control of the machine, but because it was the only program on the machine it didn’t need an OS, and contained all the OS functionality it needed, inside itself.
Cheers,
Wol
This is the first time I see the allegation that IBM reused code from OS/2 in OS/400 to introduce the IFS. I’d love to see more proof to this claim.
To my current knowledge, the database has never been “pulled out of the OS” in OS/400 and successors. In recent decades, the SQL interface to the database within the OS (kernel, aka LIC) has been greatly enhanced and seen considerable performance improvements. I see no reason why IBM should change a well-working concept. One might see this SQL interface being “the database”, but as far as I understand, it’s a mere frontend to the underlying database foundation.
Neither is the POSIX part of the IFS inherently ASCII-only. Maybe the author assumes byte streams always being ASCII?
I don’t understand on which foundation these claims are based. Maybe this is just a side issue compared to the rest of the article, but I think, even side issues should be presented correctly.
I was there when it happened, and that is what IBM told me in 1995. The database is in there, I never said it wasn’t. but it is no longer the one and only file system of the machine. And I think they are presented correctly, as you might imagine.
DB2 was never the “one and only file system of the machine.”
At the MI layer, presented by the Licensed Internal Code (LIC) (or SLIC on RISC systems), there is the machine context, and we have “library” objects (*LIB) and the concept of a library list. There are MI instructions such as RSLVSP to resolve a pointer to a named object in one of these contexts (libraries), or by searching via the library list. This was later called “the Library file system.” The objects that reside in the library file system include user profiles, programs, data areas, and files, etc. Files come in several flavors — physical files (PF), logical files (LF), display files (DSPF) and printer files, to name a few. Of those, only PFs and LFs are “database” objects. Hence, it is incorrect to say that the database was the only file system.
With V3R1 and V3R6, IBM introduced the Integrated File System (IFS), that added quite a few new types of “file system” in addition to the original Library file system (that dates back to S/38 CPF).
So, while IBM did add quite a lot of new “file system” functionality, as part of their goal to make OS/400 POSIX-compliant, I think you have mis-stated the situation. Some people within IBM and outside of IBM sometimes also refer to the “Library” file system as “the DB2 file system” because Db2 database objects can only exist in the library file system. Perhaps that “Db2 file system” nomenclature has contributed to this misunderstanding.
Perhaps it has.
Thanks for your follow-up and comment about your OS/2 (HPFS?) filesystem claims. Are you bound by an NDA, or can you give some more details? Even anecdotical ones?
You wrote “IBM pulled the database out of the operating system and added in the OS/2 Parallel File System to give a POSIX-compliant, ASCII formatted file system for the AS/400”. To me this seems to be a gross oversimplification of the matter, probably due to the terseness of presentation.
Proof of evidence besides “I was there” would help greatly in understanding and help calm down the IBM i fan base out there. 🙂
“involved increasing a new operating system” – doesn’t make sense to me. Did you mean “in creating” ?
Yes. Thank you.
I think it would be interesting to have a lightweight kernel with all state stored in SQLite DBs. I’d choose FreeBSD for the kernel and have a FUSE SQLite file system but maybe Mach or other message-based kernel might be more appropriate.
I believe the BeOS had a database based file system.
I guess they’ve never heard of Pick….
Early MUMPS (which was the 3rd language to have an ANSI standard, after FORTRAN and COBOL) systems, such as ISM and DSM, were multiuser database based operating systems in the 70s). Later versions ran on top of other operating systems such as Vax/VMS and Unix.
This clearly doesn’t go far enough! With 8-bit DOS we had “everything is a byte”, then UNIX came along and said “NO! Everything is a file!”, only to be outdone, years later, by DBOS’ “Oh NO buddy! Everything is a database!”.
Well, take this: “Everything is a stochastic database with random autocorrelative next command recall!”. There! The resulting OS shall consist of an entangled superposition of error-corrected superconducting Cat Qubits, through an uncertainly asociated wavefunction API (or not?)! 8^p
Oh my god….
Headline: Cloud outgrows Linux, New DBOS
Story: It uses Linux kernal
Story: It uses extremely gutted Linux kernel, not Linux operating system.
Bear in mind, Linux IS JUST THE KERNEL.
So I think you mean “it does not use the GNU userland”
🙂
Cheers,
Wol (a dedicated Pr1mate)
BTW, don’t forget, when Informix tried to eat Ardent, it was Ardent emerged the victor (in practice if not in name) before IBM took over Informix in order to get their hands on the Pick assets, and then they dumped it because rumour had it it was busy eating DB/2’s lunch.
For the love of God, don’t write any part of this system in SQL. There are easier languages to do optimisation for and the code would be a maintenance nightmare. SQL is 1970’s tech and it hasn’t exactly improved over the past half century. Use ANYTHING else.
Agreed. SQL is (of necessity) a database engine in its own right! It ignores Einstein’s dictum “make things as simple as possible (but no simpler)” with a vengeance!
SQL is a query system designed to query unstructured data. It then has all the smarts to structure it as required. And on top of that, it’s a data manipulation language. OUCH, OUCH, AND TRIPLE OUCH. I’ve been well aware of points 1 & 2 for ages – the structure stuff belongs in the database schema, not the query language. I’m not so sure about the data manipulation side of things, but it complicates things something awful.
This is where the Unix dictum “Do one thing, and do it well” really *SHOULD* be applied, whereas SQL is a jack-of-all-trades, and incompetent to boot …
Cheers,
Wol
it feels like they r just movin chairs around the deck here- perhaps actually focus on something that would make a huge difference- focus on an os written in rust – then put ur db stuff on top- isnt it time for c++ to go?✌️
Absolutely fascinating discussion here! The journey from “everything is a byte” in the DOS era to “everything is a database” with DBOS, and now, the intriguing concept of “everything is a stochastic database” leveraging quantum computing principles, really showcases the incredible evolution of computing paradigms. While the humor in imagining an OS built on superconducting Cat Qubits and a wavefunction API is appreciated, it highlights an essential truth about our industry: innovation is relentless, and the boundaries are constantly being pushed.It’s interesting to see the debates on the choice of programming languages for future systems. SQL’s criticisms are well-taken, considering its age and the alternatives that have emerged. Meanwhile, the push for Rust over C++ for system development resonates with the growing demand for safety and performance in modern software engineering. Rust’s memory safety guarantees and performance could be particularly beneficial for developing more reliable and efficient systems, whether for operating systems, databases, or other critical infrastructure.Yet, this discussion also makes me wonder about the future of programming paradigms themselves. With advancements in AI and machine learning, how long before we start discussing operating systems and databases designed around AI-first principles? Perhaps the next big shift will be from “everything is a database” to “everything is an AI model,” where systems are not just containers of data or processors of commands but intelligent entities capable of learning, adapting, and optimizing themselves in real-time.The journey from MUMPS to a hypothetical AI-centric computing paradigm illustrates just how much potential there is for revolutionary change in computing. What new challenges and opportunities might such a paradigm shift present for system design, security, and user interaction? Let’s keep pushing the boundaries and imagining the future of computing, no matter how fantastical it might seem today.
Considering that Pick is still alive and in use, at least the database part, I wonder if the company that now owns it all, Rocket, is looking at this very, and legally, closely? BTW, I’ve been in the Pick world for over 25 years. I know many of the original players, and even still have original OS install disks. I’ve even tried to run an VM for it, but I have yet to make it work.
I doubt Rocket is looking at it legally. What would they sue over? A patent lasts, what, twenty years? Pick is over twice that age.
If you want to run Pick, would a clone do? ScarletDME is GPL, and written by a guy who I believe was on the team that wrote/maintained Pr1me INFORMATION. Okay, it’s linux only, but you can run it in a VM …
Cheers,
Wol
Well… the relational algebra model is a powerful way to represent (and, apparently, to conveniently also store) information. Glad it was realized. IMHO the hierarchical file system model should have never be made accessible to end users. It’s too low level, too limiting to express user intentions, doesn’t belong to the user layer (we have it because it was economic and convenient in the first personal computers also to store OS info, then we adapted to it).
The amount of wasted energy of current “unix style” system just use to parse strings again and again to locate data is absurd, even in configuration files, systems of course natively lacking a DB.
IBMi model is teaching us something.
And, I dare to say, if one wanted it, IBMi should be the easiest system to distribute horizontally and running microservices and message passing style of computing, while keeping observability and debugging.
Hey! Fun to see you over here…
I agree with the idea that I don’t ever want to think of the file system. That’s why Google created Spanner. And its developers just don’t care. They dump data into this infinite storage and it is a database or a file system or whatever they need and it just works.