
A decade and a half ago, when Dennard scaling ran out of gas and many of us were starting to first think about what the end of Moore’s Law might look like should that day ever come, a bunch of us were kicking around what it might mean. People brought up 3D stacking, optical computing and interconnects, and all sort of neat ideas. And we quipped this:
“It looks like we will all have to go back to coding in assembler,” and everyone had a good laugh. And then we added: “Well, at the very least, it looks like we all might have to take all of this open source stuff written in interpreted languages like Java and PHP and rewrite it all in C++ and compile it down very close to the hardware.”
Nobody laughed quite so hard at that one. And the reason is two-fold. First, that would be very hard to do and it would mean giving up some programmability and portability. And second, it is a trick that works precisely once, like increasing server utilization by adding a server virtualization hypervisor to a machine. There is no iterative improving.
That day, at least according to Meta Platforms and its Facebook division, has come for database and datastore execution engines and thus we see the launch of the Velox open source project, with Intel, Ahana, and ByteDance all enthusiastically joining the project.
Velox has been in development at Facebook for several years and was quietly open sourced last year, when Ahana, ByteDance, and Intel signed up to contribute to the cause. ByteDance is famously the owner of TikTok, which at the very least is a hell of a lot more amusing than Twitter or Facebook and has infrastructure needs that rival those two social media platforms. Ahana was launched two years ago to commercialize Facebook’s Presto database federation overlay and if there is a new execution engine coming to Presto, it has to be involved. And not surprisingly, in the past year Ahana has been one of the major contributors to the Velox project. Intel has to be in the middle of everything, which is why it is there.
At the Very Large Data Bases 2022 conference next week, Meta Platforms will formally present what Velox is to the world and open up the project for contribution from the outside and generally make a lot of noise about what it is doing. The company is putting the Velox paper out today and doing that formal launch today, ahead of the Labor Day holiday in the United States and bank holidays in various European countries to give us all something to think about as we eat and drink and be merry.
Velox is first an execution engine with velocity, and that has meant rewriting an execution engine in C++ instead of Java and some other interpreted, high level programming language such as Java, which has been used for many of the open source data analytics stacks created by hyperscalers and cloud builders. Google’s MapReduce clone, Hadoop, for instance, was largely written in Java, with bits of C++ here and there to speed things up. A number of data analytics startups took ideas implemented in Java and recompiled them in C++, so this idea of getting very close to the iron is not new. But what is new is that Meta Platforms wants to create a unified execution engine that underpins the Presto federated database, Spark in-memory database, and even PyTorch machine learning platform that does a lot of the heavy analytics lifting for Facebook, Instagram, and its other properties on the Internet.
So in a sense, with Velox, the write once, run anywhere promise of Java is being preserved, but in a slightly different and more computationally efficient manner. An execution engine that runs across distributed worker nodes in any and all analytics platforms – and that is indeed the goal here, which is admirable – gives the portability, and do does coding it in C++ to a certain extent.
Moving from Java to C++ means that the database and datastores using Velox are going to do their work faster – somewhere between 2X to 10X faster. And if that is the case, then hyperscalers and cloud builders can get the same analytics work done 2X to 10X faster or with 2X to 10X fewer servers, or somewhere using a mix between speed and fewer servers. (More on that in a moment.)
As far as Meta Platforms can tell, there is a lot of reinventing of the wheel going on out there in execution engines that sit between database engines and runtimes and their distributed SQL query plans and optimizers running on their worker nodes.
“This evolution has created a siloed data ecosystem composed of dozens of specialized engines that are built using different frameworks and libraries and share little to nothing with each other, are written in different languages, and are maintained by different engineering teams. Moreover, evolving and optimizing these engines as hardware and use cases evolve, is cost prohibitive if done on a per-engine basis. For example, extending every engine to better leverage novel hardware advancements, like cache-coherent accelerators and NVRAM, supporting features like Tensor data types for ML workloads, and leveraging future innovations made by the research community are impractical and invariably lead to engines with disparate sets of optimizations and features. More importantly, this fragmentation ultimately impacts the productivity of data users, who are commonly required to interact with several different engines to finish a particular task. The available data types, functions, and aggregates vary across these systems, and the behavior of those functions, null handling, and casting can be vastly inconsistent across engines.”
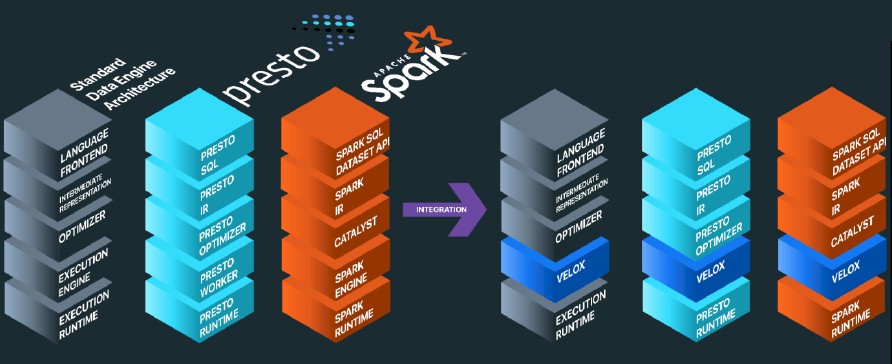
So Meta Platforms has had enough, and just like RocksDB became a unifying database engine for various databases, and like Presto became a unifying SQL query layer to run across disparate and incompatible datastores and databases (and allowed querying data in place across those datastores and databases), Velox is going to be a unifying worker execution layer across its databases and datastores. In fact, Meta Platforms is not just using the Velox engine in Presto, Spark, and PyTorch, but also deployed it in its XStream stream processing, F3 feature engineering control, FBETL data ingestion, XSQL distributed transaction processing, Scribe message bus infrastructure, Saber high query per second external serving, and several other data systems. What Meta Platforms wants now is help tuning Velox so it is ready for the next hardware platform when it comes along, and database and datastore vendors that commercialize software stacks open sourced by Facebook or others or that have proprietary systems all want the same thing and will be willing to help.
In other words, if this Velox works out right, the execution engine in data analytics platforms will no longer be a differentiating feature for anyone, but a common feature for everyone. Much as InnoDB and RocksDB database engines and PostgreSQL front ends have become standard across many relational databases.
The execution engine created for Presto is called Prestissimo and the execution engine for Spark is called Spruce. By adding Velox to the XStream streaming service, now the PrestoSQL function package used with Presto can be exposed to the XStream users and they do not have to learn a new domain-specific query language to run a query against the streaming data.
In many cases, particularly with in-memory or streaming data, the Velox execution engine brings another key benefit, called vectorization, which Steven Mih, co-founder and chief executive officer at Ahana, explains to The Next Platform.
“Velox is designed to have state of the art vectorization, and that is a big deal,” says Mih, reminding us that Databricks had a native C++ vectorized execution engine for Spark called Photon, which it talked about earlier this year. “Vectors allow developers to represent data in columnar format in main memory, and then you can use them for input and output and also for computation. Apache Arrow does some of that, but it is more for the transfer of the data. This is for the execution engine itself. If you want to do a hash or a compare, for instance, these vectors are really good at that, and as compute engines become more and more parallel, they can take advantage of that hardware, too, boosting speed even more.”
On that note, we asked Pedro Pedreira at Meta Platforms, one of the authors of the paper and a software engineer at the social network who is one of the creators of Velox, if this execution engine could offload work to GPUs yet. “Not today, but this is something in our plans for the future – offload execution to GPUs and potentially other hardware accelerators,” Pedreira replied by email. With so many beefy vector engines being added to server CPUs these days, it may not matter at the moment if there is GPU offload.
What matters is that Velox doesn’t reinvent the wheel, and because it is written in C++ and runs a hell of a lot faster than a Java-based execution engine it is therefore economically feasible to justify ripping apart a data analytics stack to get Velox inside of it.
To prove the point, Meta Platforms ran the TPC-H data warehousing benchmark atop its Presto databases, one using the Presto Java engine and the other using the Prestissimo Velox C++ engine. Take a look:
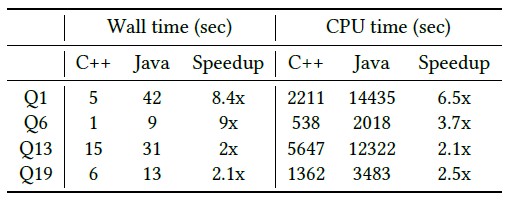
The TPC-H benchmark was run on a pair of 80-node clusters with the same CPUs (which ones were not revealed), 64 GB of main memory, and two 2 TB flash drives. This was for a 3 TB TPC-H dataset, which is not particularly large but representative of a lot of datasets in the enterprise. Meta Platforms selected two CPU-bound queries (Q1 and Q6) and two shuffle queries with heavy I/O requirements (Q13 and Q19) to test the systems. The speedup is greatest on CPU-bound queries, and the coordinator of work on the execution engine is the new bottleneck that pops up limiting the work. For the shuffle queries, there are metadata, timing, and message size issues that need to be optimized further to boost performance.
In addition to doing the TPC-H work, Meta Platforms took a real set of analytical queries running at the company and replayed them through two distinct clusters, one using the Presto Java execution engine and the other using the Prestissimo Velox C++ execution engine. The chart below is a histogram showing the number of queries that are sped up along the Y axis and the factor of that speedup along the X axis:
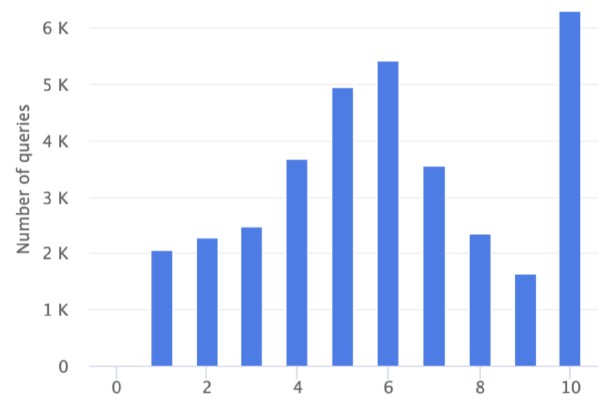
The average speedup is somewhere between 6X and 7X. There were no queries where Presto Java was faster (which is the 0 column), and there were only a few where the performance was the same (the 1 column) between Presto Java and Prestissimo Velox. About a fifth of the queries had an order of magnitude more performance using the Velox execution engine.


The Cloud Outgrows Linux, And Sparks A New Operating System
Ultimately, every problem in the constantly evolving IT software stack becomes a database problem, which is why there are 418 different databases and datastores in the DB Engines rankings and there are really only a handful of commercially viable operating systems. But what if the operating system is the problem? …

The Iron That Will Drive AI At Meta Platforms
If there is one thing that is consistently true about HPC clusters for the past thirty years and for AI training systems for the past decade, it is as workloads grow, the network becomes increasingly important – and perhaps as important as packing as much flops in a node as …
Meta Platforms Spent Over $1 Billion On Arista Networking In 2022
The hyperscalers and cloud builders are the toughest customers in the IT sector, demanding the highest performance at the lowest price and an ever-improving ratio between the two. They can be as tough as they want, of course, but unless they want to design their own ASICs and compute, storage, …
Small but important correction – the Google stack (GFS, MapReduce, Bigtable, Tenzing, Dremel, Flume, ..) has always been in C++. It’s the open source copy (Hadoop, HDFS, Hive, HBase, Presto, Spark, ..) that was implemented in Java.