

Amazon Web Services may not be the first of the hyperscalers and cloud builders to create its own custom compute engines, but it has been hot on the heels of Google, which started using its homegrown TPU accelerators for AI workloads in 2015.
AWS started with “Nitro” DPUs in 2017 and quickly decided it needed to innovate at the compute engine on all fronts if it was going to continue to innovate with server infrastructure into the future. And so now we have seen many generations of Nitro DPUs, four generations of Graviton Arm server CPUs, two generations of Inferentia AI inference accelerators, and now a second generation of Trainium AI training accelerators. The Trainium2 chip was revealed alongside the Graviton4 server CPU at the recent re:Invent 2023 host by AWS in Las Vegas, and we have spent a little time trying to get a handle on this new AI training engine and how it relates to the Inferentia line.
AWS has not put out a lot of details about these AI compute engines, but we managed to get some time with Gadi Hutt, senior director of business development for the Annapurna Labs division of AWS that designs its compute engines and shepherds them through the foundry and into AWS systems, to get a little more insight into the relationship between Inferentia and Trainium and what to expect with Trainium2; we also have done some digging around in technical documents for specs and tried to fill in the gaps as we always do when we find the information lacking.
To set the stage, though, let’s do one little bit of math before we get into the feeds and speeds of the AWS AI compute engines.
During the re:Invent keynote by AWS chief executive officer Adam Selipsky, Nvidia co-founder and chief executive officer was a surprise guest, and in Huang’s remarks said that during the “Ampere” A100 and “Hopper” H100 generations that AWS had bought 2 million of these devices. The word on the street is that AWS will get maybe 50,000 H100 orders fulfilled in 2023, and we will assume it had maybe 20,000 last year. At $30,000 a pop – and given the demand, Nvidia has very little incentive to discount at all and its net profit margins in recent quarters, where it is bringing well above 50 percent of its datacenter revenues to the bottom line suggest it is not – that is $2.1 billion. That leaves another $1.93 million A100s, which at around an average price of $12,500 from 2020 through today works out to $24.13 billion.
There is clearly room to bend the price/performance curve in such a huge investment stream, and with AWS creating its own Titan models for use by parent Amazon and tens of thousands of enterprise customers as well as offering other models, importantly Claude 2 from Anthropic, running atop its homegrown Inferentia and Trainium. And we think the curve will not look much different from what AWS has done with Graviton server CPUs. AWS is perfectly happy to sell CPUs from Intel and AMD, but it does so at a 30 percent to 40 percent “legacy” price/performance premium. Because it has cut out the middlemen with Graviton, it can offer Arm CPU instances at a lower price and that is attractive to more and more customers. We expect the same sort of legacy pricing gap between Nvidia and AMD GPUs and Inferentia and Trainium devices made by AWS.
With that math out of the way, let’s talk about Inferentia1 and walk through Inferentia2 and Trainium1 so we can get to the Trainium2 that is going to compete head to head for workloads that are currently running on Hopper H100 GPU accelerators. The H100s, as you well know, are almost as expensive as gold (about half as much per ounce these days for SXM5 versions) and as hard to get as rare earth minerals these days and are integral to the AI economy that is propping up the IT business and Wall Street these days.
Inferring The Trainium Architecture
All compute engines are a hierarchy of compute elements, storage elements, and networking to link them together, and the abstraction levels around those elements can change, especially when an architecture is new and workloads are changing fast.
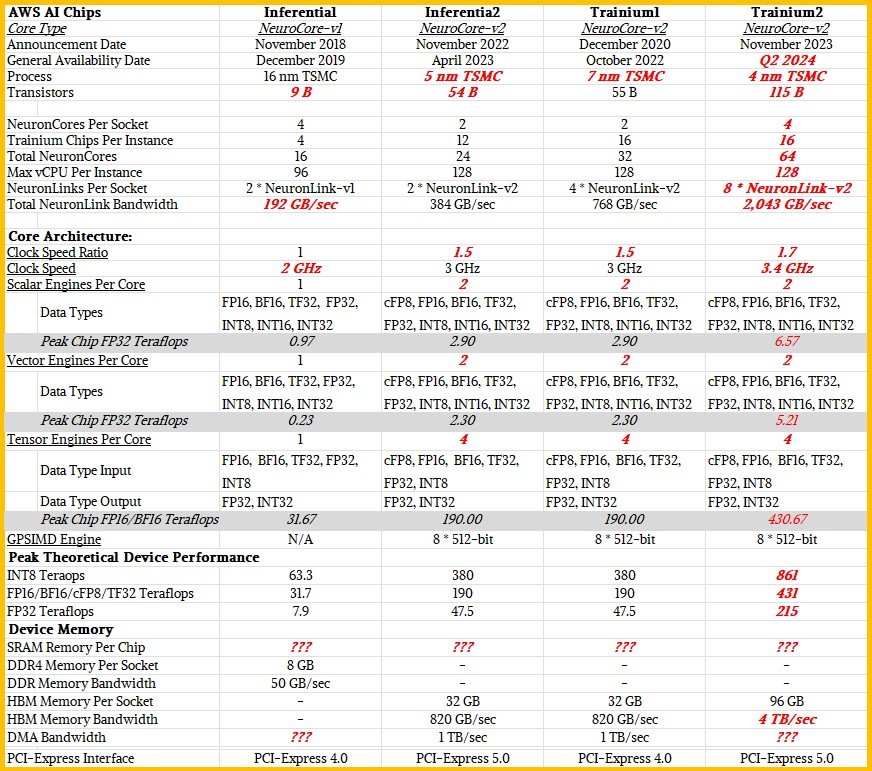
The Inferentia1 chip, created by the folks at Annapurna Labs and first revealed in November 2018 and made generally available a year later, is the foundation of the AWS AI engine effort, and here is what the architecture looks like for the device:
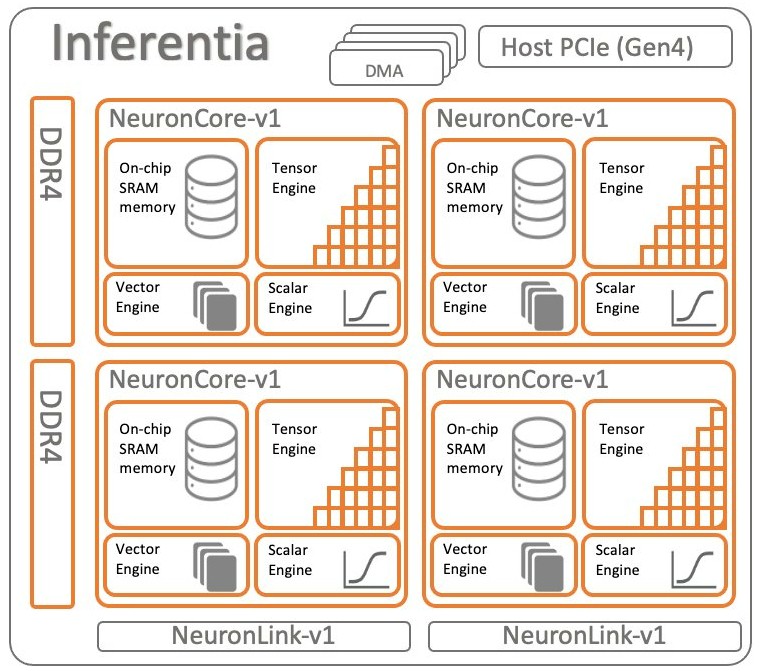
The device had four cores with four different compute elements and on-chip SRAM memory for on-chip storage and DDR4 main memory for off-chip storage. Like many AI chip makers these days, AWS did not provide the detailed specs on the Inferentia1 device in terms of SRAM memory and cache sizes or clock speeds, or even the number of elements within each of the NeuronCores employed in the device. In the Neuron SDK for the Inferentia and Trainium chips, AWS did talk a bit about the architecture of the NeuroCore-V2 core used in Inferentia2 and Trainium1 and we can use that as a basis to figure out what Inferentia1 was and extrapolate to what Trainium2 might be.
No matter the generation, the NeuronCores have a ScalarEngine that handles scalar calculations and a VectorEngine that handles vector calculations in various precisions of both integer and floating point data. These are roughly equivalent to the CUDA cores in an Nvidia GPU. According to the Neuron SDK, the NeuronCore-v1 ScalarEngine processes 512 floating point operations per cycle and the VectorEngine processes 256 floating point operations per cycle. (We think AWS meant to say there are 512 bits of processing per cycle on the ScalarEngine and 256 bits of processing per cycle on the VectorEngine and then you pump the data in the format of choice through these to do a specific kind of calculation.
The NeuronCore architecture also includes a TensorEngine for accelerating matrix math beyond what can be done pushing algebraic matrix math through the VectorEngines, and matrix math is so vital to both HPC and AI workloads that these often do a lot of the work and provide the most throughput. The TensorEngines are roughly akin to the TensorCores in the Nvidia GPU, and in the NeuronCore-v1 cores, they could deliver 16 teraflops at FP16/BF16 granularity.
The Trainium1 chip was announced in December 2020 and shipped in two different instances, the Trn1 and the Trn1n. We did as much analysis as was possible at the time on the Trainium1 and those instances back in December 2021, and frankly, there was not a lot of data from AWS about these homegrown AI compute engines. The Trainium1 used a new NeuroCore-v2 core which had the same elements but fewer cores, as you can see here:
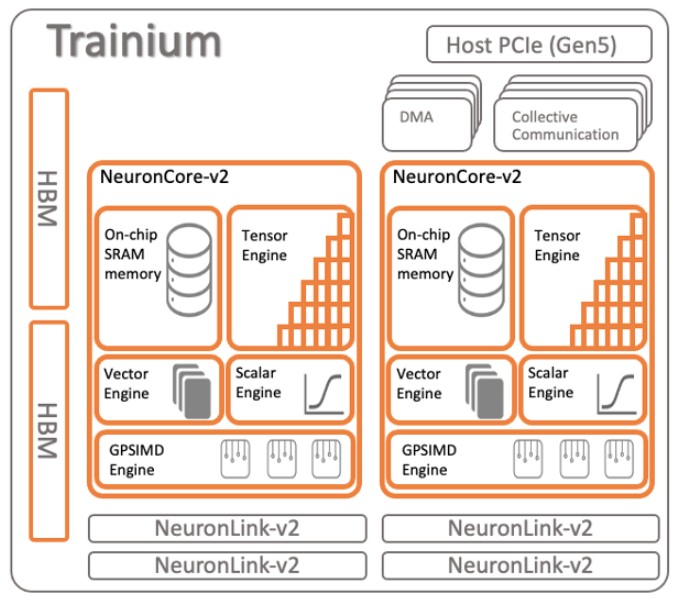
With the Trainium1 chip, AWS added 32 GB of HBM stacked DRAM memory to boost the bandwidth of the device, shifted to a PCI-Express 5.0 form factor and I/O slot, and boosted the number of NeuronLink chip-to-chip interconnect links by a factor of two to four while at the same time boosting their bandwidth by a factor of 2X.
We have no proof of this, but we think that with Trainium1, AWS moved to half the NeuronCores per chip compared to Inferentia1 – two instead of four – and then doubled up the number of scalar, vector, and tensor engines within each core. The change then was really a change in abstraction level for the cache and memory hierarchy and basically made the NeuronCore multithreaded within each computational element type.
Interestingly, The NeuronCore-v2 first used in the Trainium chip also included something called the GPSIMD-Engine, which is a set of eight 512-bit wide general purpose processors. (Very interesting indeed.) These devices can be addressed directly with C and C++ and have access to on-chip SRAM and the other three types of engines on the core and are used to implement custom operations that need to be accelerated and that are not directly supported by the data and calculating formats in those other engines. (We had to consult Flynn’s Taxonomy to try to get our mind wrapped around how this GPSIMD-Engine fits in, and it is not clear from the documentation that we have seen if this is an array processor, a pipelined processor, or an associative processor.)
The Inferentia2 chip for inference is basically a Trainium1 chip with half as many NeuronLink-v2 interconnect ports. There may be elements of the chip that are not activated as well. The clock speed and performance seems to be about the same, as is the HBM memory capacity and bandwidth.
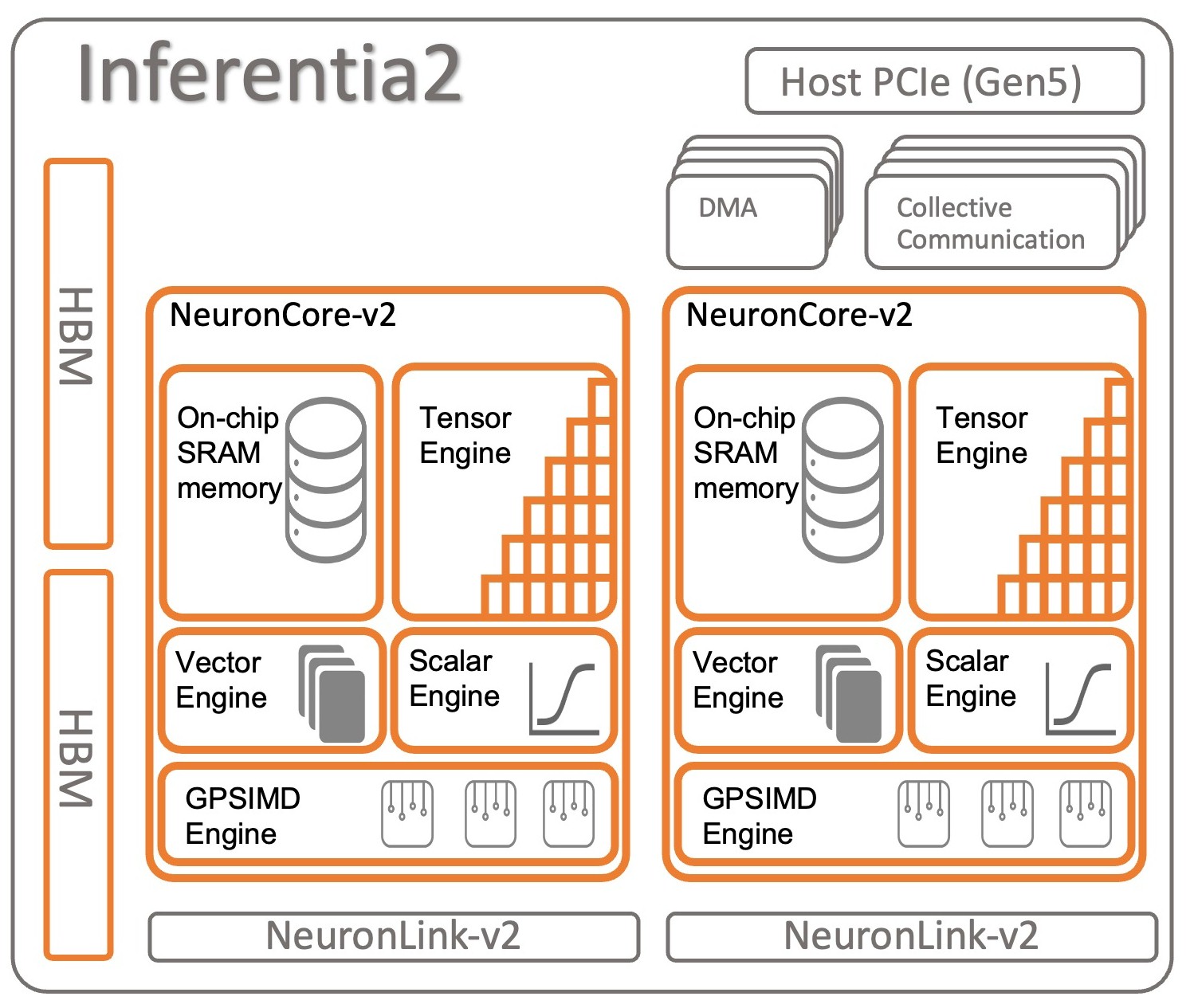
“The silicon architecture between Inferentia2 and Trainium1 is almost the same,” Hutt tells The Next Platform. “We kept the HBM bandwidth for Inferentia2 because that is super-important for inference, not just training. LLM inference is actually bounded by the memory, not by compute. So we can actually take a similar silicon architecture and reduce costs where we can – for instance, we don’t need as many NeuronLinks. With inference, we only need links in a ring fashion as we move from accelerator to accelerator to generate tokens. With training, of course, you need full mesh connectivity, minimizing the number of hops between each accelerator inside of the server. And of course, when you go to the training server, you need a lot of network bandwidth.”
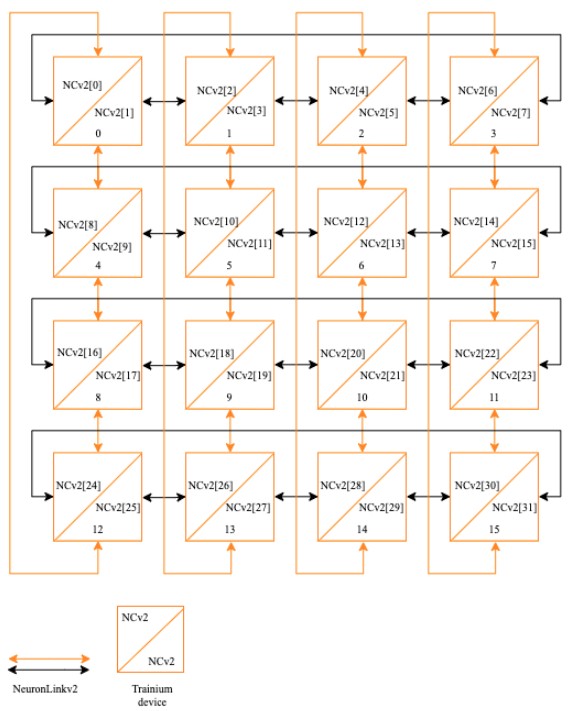
That interconnect on the servers using sixteen of the Trainium1 chips is a 2D torus or a 3D hypercube, which are the same thing depending on how you want to talk about it, according to Hutt, and it looks like this:
Below is a table that brings the feeds and speeds as we know them together for Inferentia1, Inferentia2, and Trainium1 as well as our prognostications, shown in bold red italics, for Trainium2. The Neuron SDK has not been updated with any information on Trainium2 as yet.
Based on the picture of the Trainium2 chip package, shown below, we think it is essentially two Trainium1 chips interlinked as either a monolithic chip or as a two-chiplet socket with some kind of high speed interconnect hooking them together:

Hutt did not give out any of the feeds and speeds of the Trainium chip, but he did confirm that Trainium2 has a lot more cores and a lot more memory bandwidth, and added further that the effective performance of the chips would scale to 4X – what he called a conservative number – and perhaps beyond that of the Trainium1 on real-world AI training workloads because these workloads have been bound by memory capacity and memory bandwidth more than compute.
We think the Trainium2 chip will have 32 cores and will be shrunk from the 7 nanometer processes used for Trainium 1 down to 4 nanometer processes so that the doubling of the cores can be done within the same or only slightly higher power envelope of Trainium1. We also think there will be a modest clock speed increase from the 3 GHz used in Trainium1 – a number that AWS has divulged – to 3.4 GHz with Trainium2. We also think – based on a hunch and nothing more – that the aggregate NeuronLink bandwidth on the Trainium2 will go up by 33 percent to 256 GB/sec per port, yielding 2 TB/sec coming out of the Trainium2 and still allowing for a 2D torus interconnect. It is possible that the NeuronLink port count goes up on each chip to increase the dimensionality of the torus and reducing some of the hops between devices as they share data. The 2D torus means there are a fixed two hops between any two NeuronCore chips in a cluster. It seems unlikely that networking will be increased to an all-to-all configuration, but it is possible. (SGI used to do that with its chipsets for supercomputers.)
We also think that, given that AWS wants to scale UltraClusters to 100,000 devices using Trainium2 that it will reduce the actual core count on Trainium2 to quite a bit lower than the 64 cores we show in the chart above.
It is hard to say where it will be, but assume that around 10 percent of the cores will be duds and therefore the yields on the chips will be much, much higher. You can bet that AWS will keep any Trainium2 devices that can run all cores in a separate set of machines, likely for internal use where every core counts. That would put Trainium2 at 56 cores or 58 cores, maybe as high as 56 cores – with all of the bandwidth available to them. That 96 GB that AWS has committed to might be for only three of the four memory stacks we think we see on the device, which could have 128 GB of actual HBM memory. We strongly suspect it will be HBM3 memory, but Hutt did not confirm anything.
But what he did say a number of times is that the performance was being driven by the memory and not to expect the raw, peak theoretical compute to rise faster than the memory bandwidth, which if we are right is going up by a factor of 5X between Trainium1 and Trainium2.
Here are the instances that are available using Inferentia and Trainium chips:
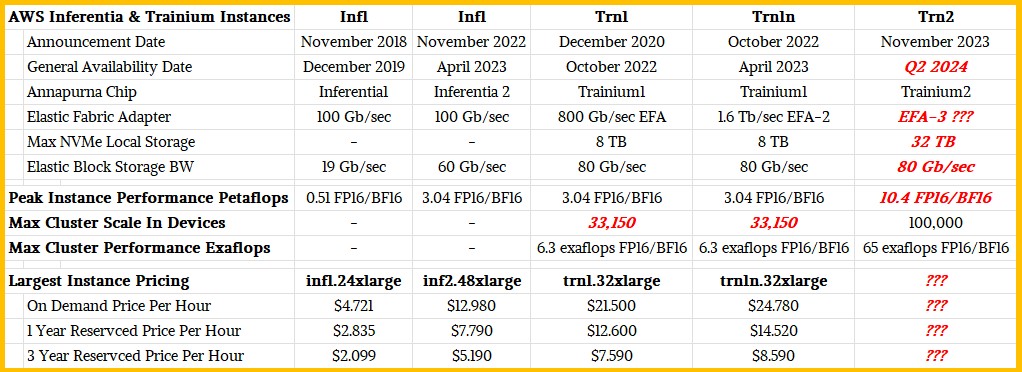
It is anybody’s guess as to how the Trn2 instances will compare in terms of price or performance, but we strongly believe based on hints and hunches that the Trainium2 will deliver around 2X the performance of the Nvidia H100, which means it will stand toe-to-toe on a lot of models with the H200 that Nvidia just announced with fatter and faster HBM3e memory. When we suggested that AWS might price the EC2 instances based on Trainium2 relative to instances using the H100 and H200 GPUs from Nvidia at the same ratio as it does between its own Graviton CPUs and AMD and Intle X86 processors – somewhere between 30 percent to 40 percent better bang for the buck – Hutt did not dissuade us from this sort of thinking. But Hutt made no promises, either, except to say the price/performance would be better for sure.
And not for nothing, but having 100,000 devices linked together with 65 exaflops at FP16 precision – and not with any sparsity tricks, but real FP16 resolution – has a chance to be the largest AI cluster in the world.

Sweetened IT Spending Forecast Is Not Precisely A GenAI Boom
Here is a paradox for you: Spending on infrastructure to support generative AI is apparently booming, as clearly evidenced by the skyrocketing revenues and profits of Nvidia. But spending on datacenter hardware is not changing all that much, and where spending is now forecast to be higher, it is in …
Pushing AI System Cooling To The Limits Without Immersion
Here is a question for you. What is harder to get right now: 1,665 of Nvidia’s “Blackwell” B200 GPU compute engines or 10 megawatts of power for a four year contract in the Northeast region of the United States? Without question, it is the latter, not the former, and both …
The Big Clouds Get First Dibs On AMD “Genoa” Chips
The expanded lineup of AMD’s 4th generation “Genoa” Epyc server chips – built atop “Zen 4” core and some with the chip maker’s L3-boosting 3D V-Cache – unveiled at a high-profile event in San Francisco this week is quickly making its way into the cloud. Microsoft and Amazon Web Services both …
Comments are closed.
It sort of makes perfect sense, I guess, that after the gigantic effort of re-geoengineering the Amazonian rainforest, to make room for the massive Himalayan peak of Annapurna, moved there from Nepal, it would become necessary to provide those involved, as well as onlookers, with an appropriate dose of re-generative nourishment. For this, nothing beats wholesome slabs of chunky-textured AI dataflow pizza, masterfully prepared with the largest of genSIMD meatballs, thick stacks of sliced HBM mushroom memory (not the hallucinogenic kind, hopefully), and a generous coating of coarse-grated vector-matrix mozarella, all tied together by a juicy sauce of tasty hypercubic networked tomatoes!
As with Google’s all-dressed stuffed-crust kitchen-sink approach to weekend AI gut-bomb gastronomy, one may expect the chunky Trainiums to be best enjoyed with some precautionary measures, a digestive software form of rolaids, gaviscon, pepto-bismol, or alka-seltzer, branded (for example) as SparseCores by the competitor. Those preparatory measures notwithstanding, a most enjoyably delicious of culinary generative AI fine dining experiences should ensue!
Still, one might wonder if some finer textured propositions might have fit the bill equally well, with less prospect for disruption in the AI dataflow regularity (better digestive efficiency). Servings of Cerebras’ high-fiber tossed salad pizza, or of PasoDoble’s reconfigurable cardiovascular fitness and balance pizza, should probably be considered as well, if only in the exploratory ways of Argonnauts’ testbeds! b^8