
Since the advent of distributed computing, there has been a tension between the tight coherency of memory and its compute within a node – the base level of a unit of compute – and the looser coherency over the network across those nodes.
All things being equal, you try to make the memory hierarchy as simple and as homogenous as possible. But all things are not always equal, and this is particularly true of accelerated workloads in general and for generative AI applications in particular. With the GPU memory capacity not being big enough, Nvidia has had to create what amounts to a memory switch – the NVSwitch – to glue GPUs into what amounts to a NUMA cluster akin to what we have had at a similar scale (from 8 to 256 compute engines) for CPUs for two and a half decades.
With the first several generations of its HGX system boards, the NVSwitch comprised a single level network gluing sixteen “Volta” V100 GPUs and then eight “Ampere” A100 or “Hopper” H100 GPUs with the two more recent datacenter GPUs from Nvidia. With the DGX H100 SuperPOD machines launched in March 2022, Nvidia added another layer to the NVSwitch network, allowing it to expand to create a single memory space across 256 of its “Hopper” H100 accelerators, which was enabled in part by a two-chiplet implementation of the NVSwitch 3 socket in leaf/spine switches.
The hyperscalers and cloud builders were a bit tepid about using the NVSwitch 3 switch fabric, but those that we talked to in detail – specifically Microsoft and Meta Platforms – said that they were looking at how they might employe NVSwitch coherent fabrics to lash together GPUs more tightly than they could with InfiniBand or Ethernet networks. And interestingly, it is these same two hyperscalers who are part of the Ultra Ethernet Consortium that is trying to create an Ethernet alternative to InfiniBand to scale AI clusters further than the NVSwitch fabric can do and obviate the need of InfiniBand, which Nvidia alone controls at this point.
As it turns out, Amazon Web Services has watched the evolution of NVSwitch very carefully and in fact its engineers have been working with Nvidia for quite some time to create a hybrid supercomputing architecture that uses Nvidia’s NVSwitch to make beefy shared memory GPU nodes at a rack scale and uses the AWS Elastic Fabric Adapter 2 (EFA2) network embodied in the cloud provider’s “Nitro” DPUs and homegrown Ethernet switches to link those rack nodes into larger clusters to share work.
Note the absence of InfiniBand in that paragraph.
That doesn’t mean that other hyperscalers and cloud builders, or enterprises for that matter, will not use InfiniBand instead of their own preferred Ethernet networks. But it very clearly states that they don’t have to, and considering that Nvidia is building a supercomputer called “Ceibo” in the AWS cloud using the custom Grace-Hopper racks and AWS networking and intends to use it for various kinds of research that would normally have been done on a kicker to the “Selene” system that Nvidia runs in its own datacenter (we think a Colovore co-location facility, but the same idea and importantly not a cloud), that speaks volumes.
The way we see it, for AWS to adopt NVSwitch technology and to invest in a custom server design, not only did it require that Nvidia help but it looks like AWS also wanted to wait until the Grace-Hopper package had the memory on the Hopper GPU upgraded to 144 GB of HBM3e memory and it strongly encouraged Nvidia to park a big supercomputer in the AWS cloud in exchange for the GH200 NVL32 adoption and for a tighter integration of the AI Enterprise and DGX Cloud software stack with the AWS infrastructure cloud. Nvidia might have tried to push InfiniBand, but clearly AWS thinks its DPU and Ethernet network is the heart of its cloud and it is not going to budge there anymore. AWS, however, needs Nvidia GPUs until it has built a base of Trainium applications and customers, which will take somewhere between a few years and forever, so it cannot push Nvidia too hard.
Looks like everybody has everybody right where they want each other.

The GH200 NVL32 rack system has 32 of the upgraded GH200 superchip systems, which have been upgraded with the new Hopper G200 GPUs that Nvidia previewed at the SC23 supercomputing conference and that ship next year. With 141 GB of HBM3e memory and 482 TB/sec of memory bandwidth, that G200 is showing anywhere from 1.6X to 1.9X better performance than a Hopper chip configured with 80 GB of HBM3 memory with 3.35 TB/sec of bandwidth, which was the original configuration launched in March 2022 and which started shipping late last year in volume. That extra performance through faster and fatter memory was worth waiting for, clearly, and AWS clearly did just that for its first supercomputer co-designed with Nvidia. The NVSwitch fabric has been around for a year and a half, and could have been built as far back as 2020. It took the exploding parameters and token counts of generative AI models to make it necessary.
Here is the schematic front and back of the GH200 NVL32 rack system:
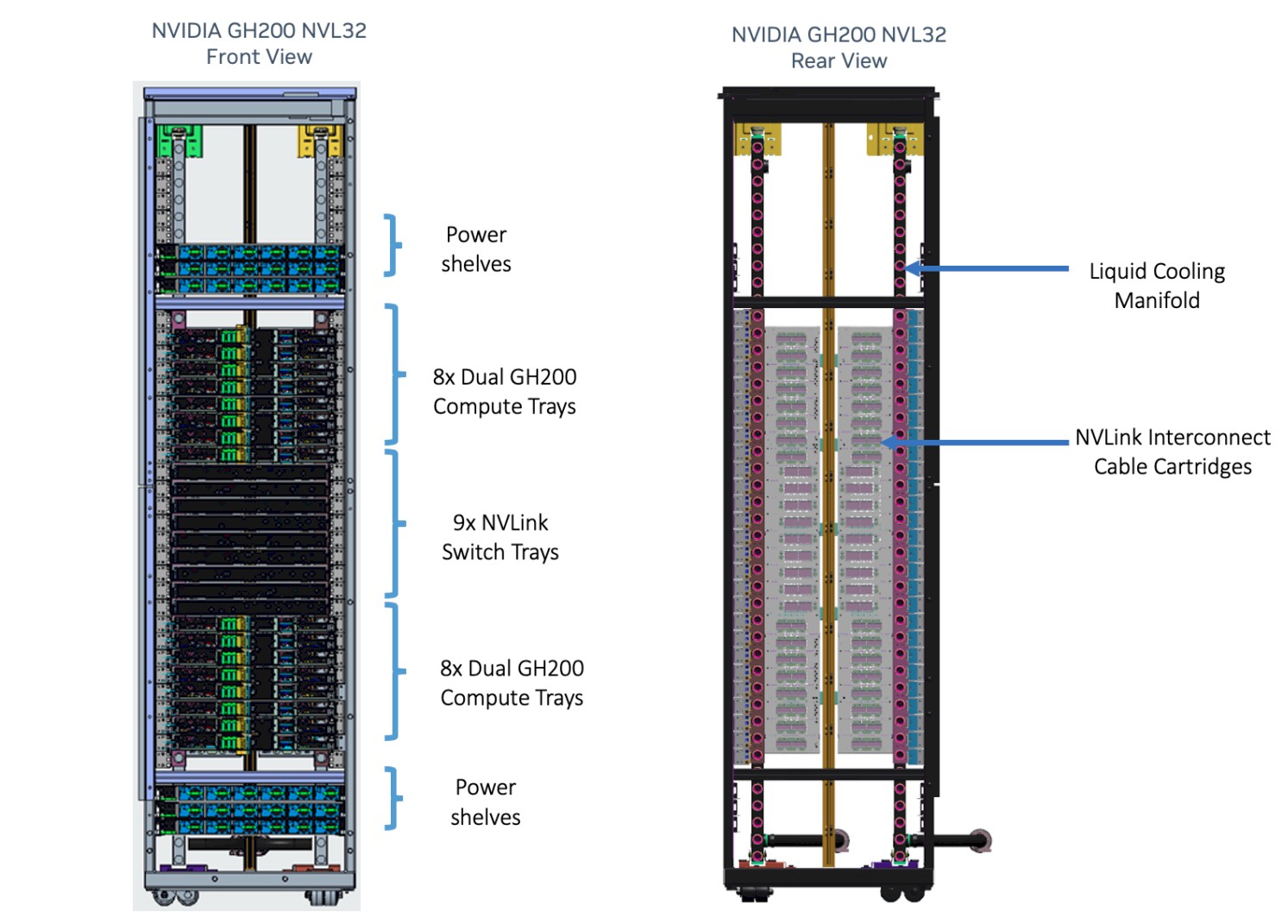
There are nine NVSwitch 3 switches in the center of the rack, and eight MGX systems with two Grace-Hopper superchip systems each (for a total of sixteen CPU-GPU nodes) on top of the switches and another sixteen CPU-GPU nodes below the NVSwitch 3 switches. So the rack-level system has 32 H100 GPUs all interlinked by NVSwitch 3 in a non-blocking, all-to-all, coherent memory fashion, and then there is a Grace CPU (really an extended memory processor and a host processor for the GPUs most of the time) attached to each GPU. There is 4.5 TB of shared HBM3e memory across this compute complex, with a total of 157 TB/sec of aggregate HBM3e memory bandwidth, and 57.6 TB/sec of NVLink aggregate bandwidth across the CPUs and the GPUs. There is 15 TB of memory attached to the Grace CPUs as well, which are a kind of L4 cache for the Hopper GPUs, for a total of 19.5 TB of memory in the rack. (The chart says 20 TB, but someone rounded up from 624 GB of combined DDR5 and HBM3 memory per node times 32, which is 19,968 GB, but you have to divide by 1,024 not 1,000 because there are 1,024 GB in a TB.)
The Ceiba rack has 1.07 petaflops of FP64 compute on its vector cores and twice that, or 2.14 petaflops, of FP64 compute on its tensor cores. At FP8 precision, the tensor cores have 63.3 petaflops on dense matrices and twice that, or 126.6 petaflops, on sparse matrices where some neat math tricks can eliminate the zeros and double pump the tensor cores even further for AI workloads which can still converge to the right answer despite statistical fuzziness, unlike HPC simulations, which would be happy with 1,024-bit precision if it could be had. Or more.
Maybe the only way to accurately simulate a universe is to create one and see what happens. . . .
Anyway, the technical blog on the GH200 NVL32 rack-level system is here if you want to poke around in it, and it says that the machine is ideal for LLM training and inference, recommender systems, graph neural networks (GNNs), vector databases, and retrieval augmented generation (RAG) models.
By the way: Nvidia has finally succumbed to the idea that these dense compute engines require liquid cooling if you actually want to fill a rack with them. So the GH200 NVL32 system is liquid cooled.
Nvidia showed off some performance metrics for the new GH200 NVL32 machine for various of these workloads. The first one is for GPT-3 training running on 16,000 GPUs, one using normal HGX boards – what Nvidia is now calling H100 NVL8 systems – linked by Ethernet switches and another using the 4X fatter GH200 NVL32 nodes that have Grace DDR5 memory extenders and host compute:
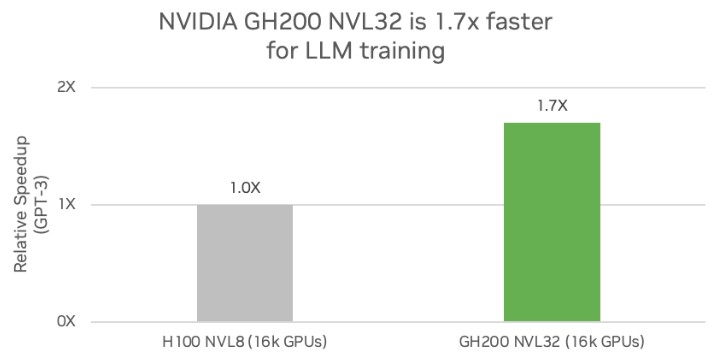
Frankly, assuming that the H100s on the left were using 80 GB of HBM3 memory delivering 3.35 TB/sec of bandwidth per GPU and the H200 GPUs used on the left had 141 GB of HBM3 memory delivering 4.8 TB/sec of bandwidth per GPU, the size of the GPU memory network would seem not to be all that important. This is the expected performance, more or less, just from having GPUs with fatter and faster HBM memory.
Now, here is one for GPT-3 inference, comparing setups with 32 GPUs to run the inference:
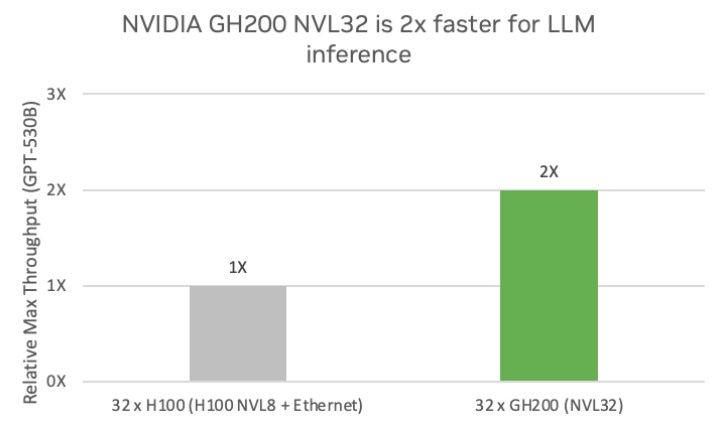
I guess we know that AWS and Nvidia want to run 32 GPU NUMA shared memories for inference. We had heard that eight-way GPU nodes were commonly used, but apparently the response time gets too slow as the models – parameter counts and token counts – keep getting larger.
In any event, the extra GPU memory and perhaps the NVSwitch fabric allows the new GH200 NVL32 system with the same number of Hopper GPU chips (but with 141 GB or memory instead of 80 GB) but all of them on an NVSwitch fabric has twice the throughput on inference for GPT-3 with 530 billion parameters. At 530 billion parameters, just holding the parameters in memory would require 2.07 TB of GPU memory capacity. Luckily, the GPUs in the GH200 NVL32 have 4.4 TB in total, compared to 2.5 TB in the 32 of the regular H100 GPUs with only 80 GB a pop.
Now, for deep learning recommendation engines, the performance jump is larger, but again we think that has more to do with the memory capacity and bandwidth than it does with NVSwitch fabric, which just makes the programming easier. (Just like NUMA is easier than MPI on CPU clusters.) DLRMs need to have embedding tables – all kinds of data about each user – stored in memory for correlations and hence the need for the Grace L4 cache accelerator and memory expander for the Hopper GPUs. Each Grace CPU has 512 GB of physical LPDRR5 memory but only 480 GB of that is available for some reason; the NVLink ports between each CPU and GPU in the Grace-Hopper superchip run at 600 GB/sec, compared to the 900 GB/sec ports that link the GPUs to the NVSwitch 3 ports in the NVLink memory fabric.
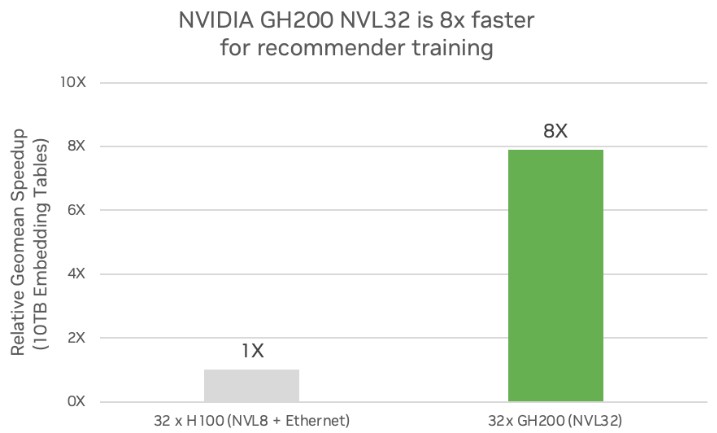
With 10 TB of embeddings – the combined Grace-Hopper memory is 19.4 TB in the GH200 NVL32 rack system – the training of the DLRM is 8X faster than on four eight-way HGX nodes based on the 80 GB Hopper GPUs, which obviously run out of memory and have to go to their X86 hosts for their embedding tables over the PCI-Express 5.0 bus. So, yeah, NVSwitch has lower latency and crazy higher bandwidth than accessing the X86 host memory for embedding tables. And so the training runs a lot faster – 7.9X faster according to Nvidia’s tests.
On graph neural network training, the story is much the same:
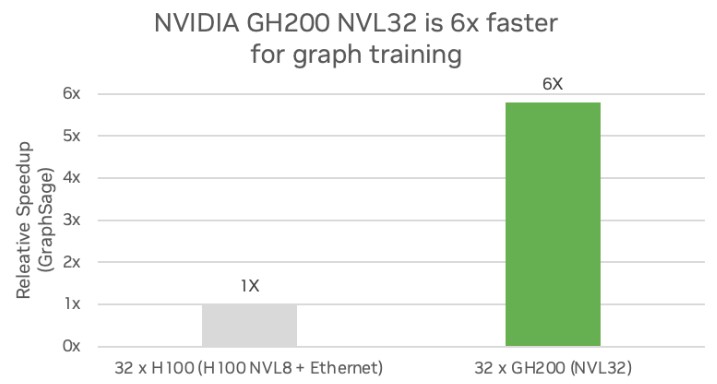
In this case, the memory and NVSwitch fabric – and we think mostly the memory – allows for the graph neural network to be trained 5.8X faster on the big iron.
Which brings us back to what we were saying earlier this month: We need more memory on GPUs, not more GPUs for the memory. This is the same problem Intel tried to solve for decades by making customers buy two server CPU sockets to get the right balance of memory capacity and memory bandwidth for CPU workloads. Nvidia is doing today what Intel was doing back the early 2000s, which was creating ever more ornate and extended NUMA domains for main memory to expand instead of figuring out how to get the compute and memory in balance. Make a smaller GPU with more memory or a bigger GPU with absurdly large memory.
There are obviously some big economic and technical issues preventing this obvious approach. And that is why Nvidia and AWS are going whole hog with the NVSwitch rack-scale approach by building a supercomputer at an unknown AWS location called “Ceiba” that will lash together 512 racks of GH200 NVL32 machines into one giant supercomputer with 16,384 Hopper GH200 GPUs and an equal number of Grace CG100 CPUs.

The Ceiba tree, shown in the feature image above, is a massive world tree, like the Norse Yggdrasil, but this one is part of Mayan mythology and is common along the Amazon river in South America. The ceiba is also known as the kapok tree because its seed pods are wrapped in a puffy fiber called kapok that helps the seeds proliferate on the wind. (Like milkweed.)
The Ceiba cluster may be located in an AWS region, and at 512 racks will take up quite a bit of space to deliver a massive 548.9 petaflops of FP64 on its vector cores and 1.09 exaflops of FP64 on its tensor cores. At FP8 resolution with sparsity on, the Ceiba machine is rated at 64.8 exaflops.
What neither Adam Selipsky, chief executive officer of AWS, nor Jensen Huang, co-founder and chief executive officer at Nvidia, said during Huang’s “surprise” visit to Selipsky’s keynote today is who is paying for the Ceiba machine and how AWS might deploy the new GH200 NVL32 rack-scale systems in its datacenters going forward. We do know that Ceiba will be central to Nvidia’s DGX Cloud efforts going forward and will be used by Nvidia researchers much as the prior Saturn-V and Selene systems built by Nvidia itself were. If we had to guess, we would say that Nvidia is providing the GH200 and NVSwitch iron to AWS, which is supplying the Nitro cards for the MGX rack servers and the EFA2 Ethernet networking to link the 512 racks together. Nvidia is not going to pay list price for the use of AWS instances on this Ceiba machine, clearly, and it remains to be seen how widely the GH200 NVL32 machines will be deployed in the AWS datacenter network.
What we can tell you is that Huang said at the keynote that AWS has bought 2 million A100 and H100 GPUs to date, comprising 3 zettaflops of low precision AI style computing. Huang said that AWS is adding 1 zettaflops of capacity each quarter. We would love to see the math behind these numbers because it sounds like a lot more GPUs than Nvidia can make right now in a quarter.

Hope Springs Eternal For Arm Servers
IT organizations are funny creatures, indeed. On the one paw, they are eternally optimistic about the prospects for new technologies, and on the other paw, they are extremely resistant to change because of the economic and technical risks that change requires. For more than a decade now, the people who …
Nvidia Draws GPU System Roadmap Out To 2028
High tech companies always have roadmaps. Whether or not they show them to the public, they are always showing them to key investors if they are in their early stages, getting ready to sell some shares on Wall Street to make money – literally, going public – or talking to …

HPC Pioneers Pave The Way For A Flood Of Arm Supercomputers
Over the past few years, the Arm architecture has made steady gains, particularly among the hyperscalers and cloud builders. But in the HPC community, Arm remains under-represented. But perhaps not for long. The “Fugaku” system at RIKEN Lab in Japan is without a doubt the largest and best known Arm …
Great to see that, like Spilotes pullatus (Amazonian Chicken snake), AWS puts its valuable DC eggs in several differently-architected baskets of computational racks (Ceiba racks, Graviton4+Trainium2, …)! This should prove more robust than pungi-playing to charmingly hypnotize nearby false water cobras (Hydrodynastes gigas) in case Ceiba’s kapok (or another arch) goes kerplunk (however unlikely)!
I won’t mention here the EU’s Pirate Party (Yarr! https://www.theregister.com/2015/01/20/europes_last_pirate_gets_busy/ ) but local pastafarians could surely pre-heed the prospective rise of a tasty ZettaCthulhu Spaghetti monster of European proportions, with just two 1 PF/s CeibaRacks per 1000 residents, possibly complemented with a side dish-plate of fresh Cerebras tossed salad, or a rack of crunchy Groq appetizers — both best enjoyed with a glass of fine departed Mayan spirits of the Ceiba tree variety (I think)!
Within this perspective, it is eminently clear that locating AWS’ 512-rack Ceiba machine (550+ PF/s) in the Asheville-Lenoir (NC) corridor (pop. 112,000+) will bring the same enjoyment of a ZettaScalar computational experience, of the finest culinary quality, to these most centrally-located of eastern-seaboard tastebuds (Prime location!)!
As HPE’s senior VP Jeremy Cox recently almost noted ( https://www.theregister.com/2023/11/29/hpe_fiscal_2023/ ; see also today’s related TNP article), “customer digestion” by 30-foot long 550-lb Amazonian green anacondas (Eunectes murinus), of enormous girth, can take some time, and “de-elongation” or shrinkage might then ensue, providing much needed relief (if I understood well … ?). Accordingly, promoting a cloudy diversity in Amazonian rainforest DC gastronomy should prove most valuable to all folks who have not yet been devoured by local fauna (or not?)!
As Hubert once said then: “Bon HPC appétit!”! (and, good job on the mixing-up of those cloudy archs!) 8^b
Ceiba’s 549 Petas sounds like a most worthy opponent for MS’ Eagle Cloud Azure (561 Petas)! Let the Rhumba begin! (eh-eh-eh!)