
Natural language processing has been an easy fit for these relatively early days of artificial intelligence. Teaching computers how humans speak and write has broad applications, from customer service chatbots and voice-controlled assistants (think Amazon’s Alexa or Apple’s Siri) to the – at times frustrating – autocorrect capability on smartphones and other devices. The wide array of uses cases is fueling a global NLP market that Fortune Business Insights is forecasting will jump from $20.98 billion last year to $127.26 billion in 2028.
More recently, the drive within the industry has been to build large language models (LLM), massive NLP systems with parameters that reach into the hundreds of billions to trillions of parameters. In introducing their Open Pretrained Transformer (OPT-175B) – a language model with 175 billion parameters – scientists from Meta wrote that LLMs “have transformed NLP and AI research over the last few years. Trained on a massive and varied volume of text, they show surprising new capabilities to generate creative text, solve basic math problems, answer reading comprehension questions, and more.”
A broad range of industry giants, including Meta Platforms, are driving hard to the hoop in LLM. Google has GLaM, with 1.2 trillion parameters and LaMDA (137 billion) and in April introduced a new LLM called PaLM (Pathways Language Model), part of the company’s larger Pathways AI architecture. DeepMind has Gopher (280 billion) and Chincilla (70 billion) and OpenAI two years ago unveiled GPT-3, a LLM with 175 billion parameters. Nvidia and Microsoft last year announced Megatron-Turing Natural Language Generation model (MT-NLG), with 530 billion parameters.
Nvidia several years ago tagged AI, machine learning and deep learning as key growth drivers and its GPU-based platforms have been used to train LLMs beyond MT-NLG, including BLOOM, an open-source LLM launched this month by the BigScience AI research initiative and which can generate text in 46 natural languages and 13 programming languages.
The drive to push the size of language training models really took off with the introduction of BERT (Bidirectional Encoder Representations from Transformers), an NLP model developed by Google, according to Ujval Kapasi, vice president of deep learning software at Nvidia.
“Large language models are a type of neural network that has really captured the research world recently,” Kapasi tells The Next Platform. “As far as natural language processing goes, the opportunity there is that when these models get large enough – by large, I mean hundreds of billions to a trillion parameters – they take on really powerful capabilities. In particular, for instance, you can pre-train one of these large models and use the same model for many different applications without having to retrain it specifically or fine tuning specifically for each application, like you would have to do with many other types of neural networks.”
Essentially the same LLM that is used for a chat bot can also be leveraged in a question-and-answer service or as a summarization tool for an article. Such large models “take on complicated behaviors,” Kapasi says. “Some examples that researchers have posted are these models can explain to you why a joke is funny, for instance. Beyond what you may have seen with other previous, smaller models for natural language processing, which were one-trick ponies. That’s the opportunity.”
That said, the challenge is that the models are so large and trained with so much data that they don’t fit on a single GPU, he says. With parameters spread across so any GPUs or nodes, the trick is to find ways to efficiently scale the number of GPUs so that the training can be done in a reasonable amount of time.
Nvidia last year introduced NeMo Megatron, a LLM framework that leverages the Triton Inference Server. This week the company is updating the framework with two new techniques and a hyperparameter tool to optimize and scale training of LLMs on any number of GPUs that it says will help accelerate training by as much as 30 percent. The new techniques are sequence parallelism (SP) and selective activation recomputation (SAR).
The building block for neural networks is the transformer. Putting a lot of them in a sequence creates LLMs, Kapasi says. Within the transformer blocks – which are repeated – are neural network layers.
“For the big ones that do large matrix multiplies, previously we’ve used tensor parallelism to distribute that compute,” he says. “But now there are some other layers that are left over. Previously what people were doing were just replicating the computation of those layers on every GPU because it was a smaller amount of compute relative to the larger matrix multiplies. But once you scale to a large enough size, the amount of compute taken up by those leftover layers starts to become a bigger percentage.”
With SP, Nvidia engineers, using math and data mapping between GPUs, developed a way to parallelize that work. Now scientists training LLMS “can split that between GPUs,” Kapasi says. “That means you don’t have to redundantly compute those entire layers on every GPU and you don’t have redundantly store all the intermediate memory for those layers on every GPU. It’s a win-win.”
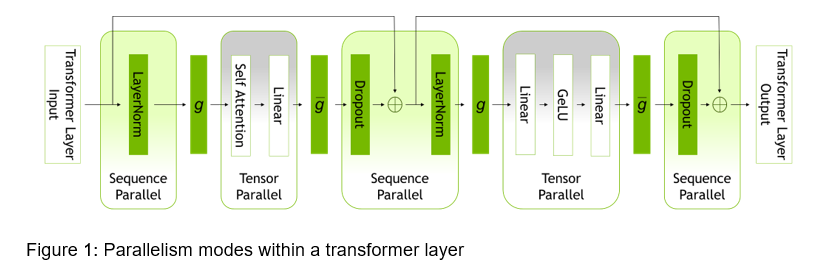
SAR addresses a slightly different situation. Researchers have found that if the model is so large that it can fit into the training system, they could store a lot of intermediate state for each of the layers inside the transformer blocks. They decide to instead just re-compute the full transformation layers when it was needed, essentially saving memory at the expense of a lot of re-computation. If there was no other way to fit the model, such a move made sense, he says. But it was a blunt tool. People were either recomputing everything or nothing.
Nvidia engineers noticed that different activations require different numbers of operations to recompute; they disproportionately use more storage but only a small percentage of the compute.
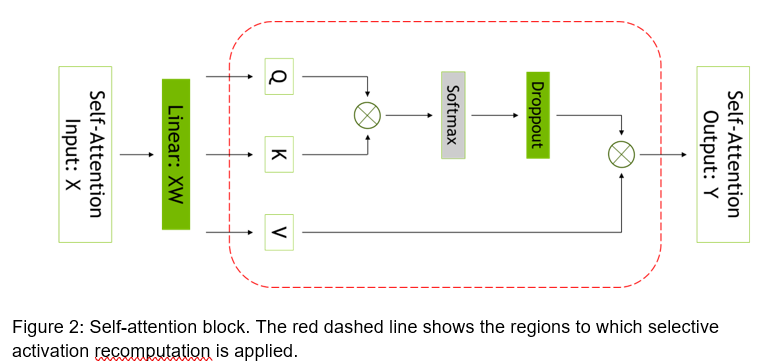
“If you’re smart about it and if you only recompute the state that falls into that category, you can actually get most of the memory savings for just a very little bit of extra compute,” Kapasi says. “Now it’s a more of a surgical kind of tool instead of this blunt tool. It’s a nice tradeoff because you save a lot of compute in order to get those memory savings. You don’t have to pay that price.”
The combination of SP and SAR can reduce the amount of memory needed by as much as five times.
The new hyperparameter tool is designed to automatically find the right training and inference configurations without code changes. The tool uses heuristics and an empirical grid search to find configurations that offer the best data, tensor, sequence and pipeline parallelism as well as the optimal micro batch size and number of activation checkpointing layers.
“One of the things that that tool does is decide [that] you don’t have to save the state of every transformer block,” he says. “You can decide if there are 12 transformer blocks in your model, based on the size of your model and the amount of GPU compute you have, maybe it makes sense to save the state for seven of them instead of all of them. This tool just helps you dial in the right amount of memory savings you need with the most minimal amount of compute you have to additionally do.”
According to Nvidia, the NeMo Megatron updates not only deliver 30 percent speedups for training GPT-3 models in size from 22 billion to 1 trillion parameters, but training can be done on 175 billion-parameter models using 1,024 Nvidia A100 GPUs in 24 days, a reduction of 10 days or about 250,000 hours of GPU computing.
For researchers training LLMs, this will affect what they can train and how long that training will take. Researchers can apply for early access to NeMo Megatron, while enterprises also can try it on Nvidia’s LaunchPad, a free program that gives users short-term access to hardware and software stacks in such areas as AI, data science and simulations.


Nvidia Declares That It Is A Full-Stack Platform
In a decade and a half, Nvidia has come a long way from its early days as a provider of graphics chips for personal computers and other consumer devices. Jensen Huang, Nvidia co-founder and chief executive officer, put his sights on the datacenter, pushing GPUs as a way of accelerating …
Opening Up The Future “Venado” Grace-Hopper Supercomputer At Los Alamos
There are many interpretations of the word venado, which means deer or stag in Spanish, and this week it gets another one: A supercomputer based on future Nvidia CPU and GPU compute engines, and quite possibly if Los Alamos National Laboratory can convince Hewlett Packard Enterprise to support InfiniBand interconnects …

Nvidia Adds Cluster Management To Its Enterprise Stack
Chip maker Nvidia might be best known for its graphics and datacenter compute engines, but the company has made no secret of its aspirations to be a bigger player across the datacenter. And not just in hardware, but in software, too. To that end, Nvidia has acquired Bright Computing, for …
Be the first to comment