
If you are a Global 20,000 company and you want to build a large language model that is specifically tuned to your business, the first thing you need is a corpus of your own textual data on which to train that LLM. And the second thing you need to do is probably read a new paper by the techies at Bloomberg, the financial services and media conglomerate co-founded by Michael Bloomberg, who was also famously mayor of New York City for three terms.
Bloomberg, the man, was a general partner at Salomon Brothers in the 1970s, heading up equity trading and eventually moved over to systems development, and so when it comes to technology, Bloomberg is no slouch. Bloomberg used his $10 million buyout from the Salomon acquisition to start a company that supplied market data to Wall Street traders, which is the venerable Bloomberg Terminal that costs $25,000 a year to have streaming all kinds of financial data and news. The company has grown to include radio and television broadcasting as well as print media, after having bought BusinessWeek magazine from McGraw-Hill as the Great Recession was roaring and magazine publishing, well, not so much.
Bloomberg LP has over 20,000 employees who are largely generating content or transformations and analysis of market data; it is a privately held company and is believed to have in excess of $10 billion in revenues. Which means that of all of the financial institutions we can think of, Bloomberg is in a position to create an LLM with a fintech bent. It has the data, it has the money, and it has the use case.
And as you can see in this paper, Bloomberg LP and researchers at Bloomberg’s alma mater, Johns Hopkins University, have worked together to create BloombergGPT using SageMaker on the Amazon Web Services cloud using Nvidia “Ampere” A100 GPUs as the main compute engines for the training.
While there are a number of general LLMs that have been tuned and pruned to work on financial-related data and perform tasks such as question/answer prompting, sentiment analysis, and named entity recognition, as far as Bloomberg, the company, knows. And the question Bloomberg and Johns Hopkins researchers wanted to answer is this: Will a model trained on financial data do better than a general model?
There are several issues here. First, to get the kinds of emergent behavior that is interesting with GPT and other models – where models can perform tasks that are unexpected reasonably well – takes quite a bit of data and therefore quite a bit of compute horsepower. This is where that Bloomberg Terminal, which has been streaming data to traders in all of the stock markets of the world for four decades, comes into play. This is the basis of a dataset called FinPile, which includes Bloomberg News stories as well as financial reports from public companies and other financial data, which is stripped of formatting and de-duplicated. The FinPile stack only includes data from early March 2007 through the end of July 2022. Our guess is that Bloomberg was not generating a lot of content (by comparison) before then, which is why this data was not included. All of this data is time stamped, but the variant of GPT-3 does not use this timestamp but will as it is eventually going to be trained to think independently about different time periods. The FinPile weighs in at 1.76 million documents, and 363.5 billion tokens (snippets of words used as the raw material for the LLM to chew on.)
This is not enough data to train a model, even though it is arguably the largest set of financial training data anyone has created. And so Bloomberg and Johns Hopkins tossed in 507,400 more documents, accounting for more than 345.4 billion additional tokens, to boost the training set size large enough to make GPT-3 behave better. The resulting training set is 2.26 million documents and 708.9 billion tokens. This is heavily based on The Pile, a curated dataset used to train the GPT-Neo and GPT-NeoX LLMs. Bloomberg de-duped this and other data, including Wikipedia and a whole bunch of other stuff. The GPT-Neo and GPT-NeoX researchers did not de-dupe, wanting to have repetition be a kind of reinforcement or PageRank.
What this means is that if I take every word I ever wrote in 35 years of doing this thing, probably somewhere on the order of 25 million words across maybe 20,000 documents, representing maybe 10 billion tokens (my stuff tends to be wordy), it would not amount to enough to have a model behave like a virtual TPM. Which is probably a blessing, because the real one is crazy enough. Although we could, in theory, tune an open source GPT-3 model to mimic my writing. (Heaven help us all. . . .)
The DeepMind people at Google have their own variant of GPT-3, called Chinchilla, and with this model they have shown that there is an ideal scaling that balances model size, compute budget, and model accuracy to help to deterministically calculate the size of the machine, in floating point operations per second, and the number of parameters needed to reach a certain accuracy. Here is how BloombergGPT fits into the Chinchilla scaling laws:
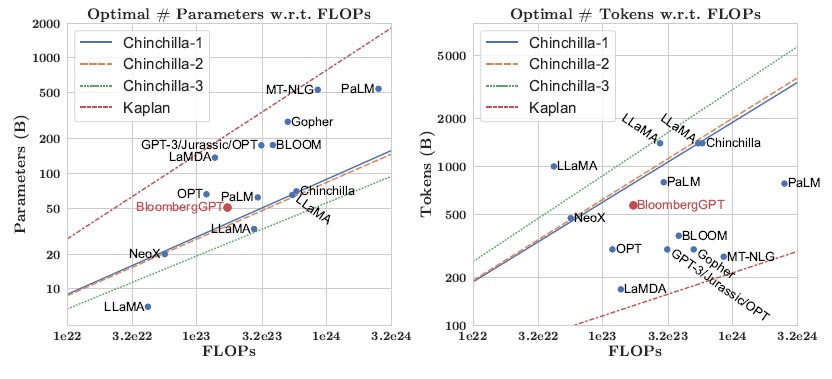
As you can see, the BloombergGPT model did not hit the ideal Chinchilla scaling. Bloomberg allocated 1.3 million GPU hours to train its model on AWS instances with eight Nvidia A100 GPUs. To be specific, Bloomberg was willing to pay for 64 of the p4d.24xlarge instances, for a total of 512 GPUs. The nodes were linked over the AWS Elastic Fabric Adapter interconnect running at 400 Gb/sec and being fed by the FSX implementation of the Lustre parallel file system, which delivers 1 GB/sec of read and write throughput for every 1 TB of storage. If Bloomberg had more financial data, it would have been able to get more ideal scaling, the researchers said. But they did not and at the same time they did not want to have less than half of the data coming from financial sources.
‘Since we are data limited, we choose the largest model that we can, while ensuring that we can train on all our tokens and still leave ~30% of the total compute budget as a buffer for unforeseen failures, retries, and restarts,” the Bloomberg and Johns Hopkins researchers write. “This leads us to a 50B parameter model, which is also roughly the Chinchilla optimal size for our compute budget.”
BloombergGPT is a PyTorch model and all of the training sequences are the same length, at 2,048 tokens, which apparently maximizes GPU utilization. The LLM makes use of the SageMaker Model Parallelism library from AWS, and drives 102 teraflops. At 32.5 sec/step, the training run took 2.36 x 10 23 flops to process 569 billion tokens and drive 50.6 billion parameters, or about 53 days.
The resulting model is particularly good at sentiment analysis for public companies compared to other general LLMS that have been tuned for financial data. Take a look:
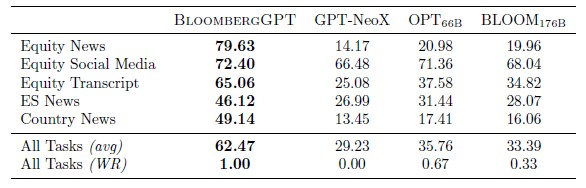
It is not clear to us how such sentiment is gauged to reckon a percentage; there must be a labeled dataset against which the model is run. What does seem clear is that at some point, you can expect the BloomergGPT Sentiment Analysis TM API to be a supplemental revenue generator for the 325,000 Bloomberg Terminal subscribers worldwide. . . .
For other financial tasks, BloombergGPT has mixed results:
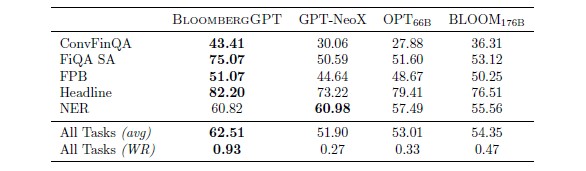
The one that BloombergGPT is pretty good at is searching through a headline with a keyword and seeing if other associated words are nearby. In this case, the Headline benchmark looks for “gold” in the title and various keywords in a human-annotated dataset. The Financial Phrase Book and Financial QA SA tests are human-annotated sentiment analysis tests that examine a news story and asks if it will help or hurt a company. The Named Entity Recognition test was developed for credit risk assessments, and the ConvFinQA test is run against S&P 500 earnings reports and at least one table and asks BloombergGPT to answer conversational questions about the report. The paper is chock full of tables that show BloombergGPT is about as good as general purpose models, trained with hundreds of billions of parameters, on general topics, too.
Not that you were expecting this, but you should not expect for the BloombergGPT or related datasets used to train it to be available openly. It ain’t gonna happen, and the paper makes that clear:
“One of Bloomberg’s core business propositions is around providing access to data that has been collected over the course of decades. As is well known, LLMs are susceptible to data leakage attacks and it is possible to extract significant segments of text given model weights. Moreover, even giving selective access to researchers isn’t a guarantee that the model cannot be leaked. Without strong privacy guarantees, we must be concerned that providing access to model weights entails giving access to FinPile. For this reason, we err on the side of caution and follow the practice of other LLM developers in not releasing our model.”
But, Bloomberg LP is releasing the paper, which is helpful for those who are new to LLMs, and the company has said that it will release the training logs that details its experience in training the model.

Precision, Accuracy, Scale – And Experience – All Matter With AI
When it comes to building any platform, the hardware is the easiest part and, for many of us, the fun part. But more than anything else, particularly at the beginning of any data processing revolution, it is experience that matters most. Whether to gain it or buy it. With AI …

OpenAI To Join The Custom AI Chip Club?
It would be hard to find something that is growing faster than the Nvidia datacenter business, but there is one contender: OpenAI. Open AI is, of course, the creator of the GPT generative AI model and chatbot interface that took the world by storm this year. It is also a …
H100 GPU Instance Pricing On AWS: Grin And Bear It
UPDATED: It is funny what courses were the most fun and most useful when we look back at college. Both microeconomics and macroeconomics stand out, as does poetry writing, philosophy, and religious studies despite the focus on engineering and American literature. The laws of supply and demand rule our lives …
Yes, WoW! This is where I would expect LLMs to truly shine (along with mass surveillance of communication networks, phones, emails, chat rooms, etc…), much more so than in the reasoned fields of engineering, math, physics, medicine, “trick-cycling”, and related journalism. Financial analysis (esp. stock market predictions) needs to consider a broad array of factors, on top of analyst experience, including product annoucements, past company performance, evolving government policy, public sentiment, local and world events, and natural disasters, and gathering all these from daily reading of TNP and (few) necessary others, can be painstaking at times, potentially leading one’s eyeballs to sweat profusely (side-effect of blue light). Training LLMs on historical stock market trends and conterminous news reports (at large) should free us of this laborious toil, especially if linked directly to algorithmic trading systems. No more fretting about whether to sell Intel stock and buy AMD instead, or sell AMD and buy NVIDIA, or sell NVIDIA and buy IBM, or sell IBM and buy Cerebras, or sell Cerebras and buy Intel, Ventana, or Ampere … especially now that ARM is also coming to the NASDAQ. Bloomberg has the killer LLM app with this one (no contest, clean off)!
Agreed! Stock market predictions are like witchcraft in three-piece suit. Harder than filling-up the dishwasher, but less so than chess and calculus. They baffle Moravec’s paradox with successful rote learning and autoregressive recall (not much to meaningfully understand, mostly smoke correlations and mirror likelihoods). Just this past Sunday (Apr. 9), the Grand voodoo priest of the horror backpropagation plague said this about LLMs/GPTs (in: “Ng and LeCun on the 6-Month Pause”, at lesswrong dot com, pointed-to by Sally Ward-Foxton):
“the amount of data they’ve been trained on, […] a trillion words, it would take […] 22,000 years for a human reading eight hours a day to go through […] So clearly the […”] intelligence [“] that is formed by this is not the type that we observe in humans.”
But it should be the perfect sorcery to cast fortune-inducing spells (word!) on stock portfolio wallets.
Picture hordes of bloody marys, sacrificed on the altar of the killer-app cult, as Bloomberg’s viral plague-orithm outmagics Oracle-of-Omaha, with most potent all-you-can-eat LLM frog soup (eh-eh-eh)!
I see it Dr. Smith, I see the light. But then I also have to deal with this: “Danger HuMo Robinson! Danger! GPT-4 is sparking up AGI! Danger!” — it’s just one treacle fire after the other (or maybe it’s Sandra Snan’s praise-worthy “most blank on the cinder” — who knows?). Well, at least they clear everything up on page 80 (but why wait so long? — GPT, can you summarize Microsoft’s paper “Sparks of Artificial General Intelligence: Early experiments with GPT-4” in just 2 or 3 sentences of normal human language, not product placement?). Here goes:
The paper suggests a “distinction between two types of intellectual tasks”:
“Incremental tasks” — rote learning with autoregressive next-word recall, that GPT-4 does well.
“Discontinuous tasks.” — actual reasoning, that GPT-4 fails at.
Treacle fire tamed. Bloomberg wins this killer-app round hand downs, for “clover and clover, over and over”, or even “moolah-moolah, oh, honey-honey”; sweeeet! Case closed. Bloody marys all around!