

We talk about scale a lot here at The Next Platform, but there are many different aspects to this beyond lashing a bunch of nodes together and counting aggregate peak flops.
For instance, for the past decade, and certainly since the rise of GPU-accelerated AI training in the cloud, the most powerful HPC system in the United States at any given time could fit in the back pocket of one of the datacenters inside one of the multi-datacenter regions of one of the multi-region facilities of any one of the big three cloud providers (two of which are also hyperscalers serving out applications to billions of users). That would be Amazon Web Services, Microsoft Azure, and Google Cloud, in the order of infrastructure size.
It is natural enough to wonder why all HPC is not done in the cloud, or at least all in one place for those organizations that want or need to control their own data and infrastructure.
If you pushed economics to its logical extreme and if you assume latency did not matter and network security for external users could be guaranteed – both of which are dubious assumptions, but this is a thought experiment – then the US federal government would build – or rather probably pay UT Battelle to build and manage – one giant HPC system located in Lawrence, Kansas or in Omaha, Nebraska that the five HPC centers at the US Department of Defense, the seventeen labs of the US Department of Energy, and the six labs of the National Science Foundation would share.
The reason there is not just one big, wonking HPC system funded by the US government – as is the case in Japan, by the way, which is a much smaller country in terms of its economy and its geography – is precisely because latency and security matter. If these HPC labs want to keep their data local to increase the security of that data, then it is logical to assume that the compute also needs to be local. And everybody wants to control their own computation and data, anyway.
But as the Extreme Science and Engineering Discovery Environment (XSEDE), a collaboration between nineteen difference academic and government HPC centers, shows, HPC resources can be shared across vast distances. XCEDE is spearheaded by National Center for Supercomputing Applications (NCSA) at the University of Illinois, the Pittsburgh Supercomputing Center (PSC) jointly run by Carnegie Mellon University and the University of Pittsburgh, the San Diego Supercomputer Center (SDSC) at the University of California, and the Texas Advanced Computing Center (TACC) at the University of Texas. It brings to bear 165,000 server nodes with over 50,000 GPU accelerators and over 6.8 million CPU cores to bear, with an aggregate computing capacity of 600 petaflops. That is on par with somewhere between one and two hyperscaler datacenters.
Here is the point that XSEDE demonstrates: If you can share remote resources on someone else’s supercomputer, then as far as the user is concerned, that looks the same as only computing on the Vast Wonking Uncle Sam Super Computer in Omaha or Lawrence. It is all remote from the HPC user workstation.
What it all comes down to, then, is data management and data security. If you can manage the placement of data across a geographically distributed network of storage and compute – what we call a hyperdistributed system – then you can do some conscious aggregations and centralization without sacrificing autonomy at these HPC centers.
And to that end, the Department of Energy has started the bidding process for what it calls the High Performance Data Facility, which will be a centralized hub of shared datasets and other resources located in one of its HPC labs that connects out through spokes of network to storage and computation in the pother centers. You can read the initial proposal here, which was announced on March 10.
Over 160 subject matter experts that work for DOE labs submitted input about their current and future workloads about how the Integrated Research Infrastructure vision of the Office of Science could be implemented. Here’s that vision:
“DOE will empower researchers to seamlessly and securely meld DOE’s world-class research tools, infrastructure, and user facilities in novel ways to radically accelerate discovery and innovation,” the HPDF announcement explains. “From an infrastructure perspective, the vision seeks to create a DOE integrated research ecosystem that transforms science via seamless interoperability. From a human-centered perspective, the vision seeks to free researchers and user facility staff from the complexity, uncertainty, and labor-intensity of hand-crafted workflow integration.”
The DOE envisions the hub and spoke model will have the HPDF as its foundation, where shared datasets will be centralized and shared across spoke facilities. What the DOE is looking for is more of a system of systems approach than a centralized compute and storage facility, something that looks very much like XSEDE to our eye.
The hub and spokes will be linked to each other via the Energy Sciences backbone network, which looks like this:
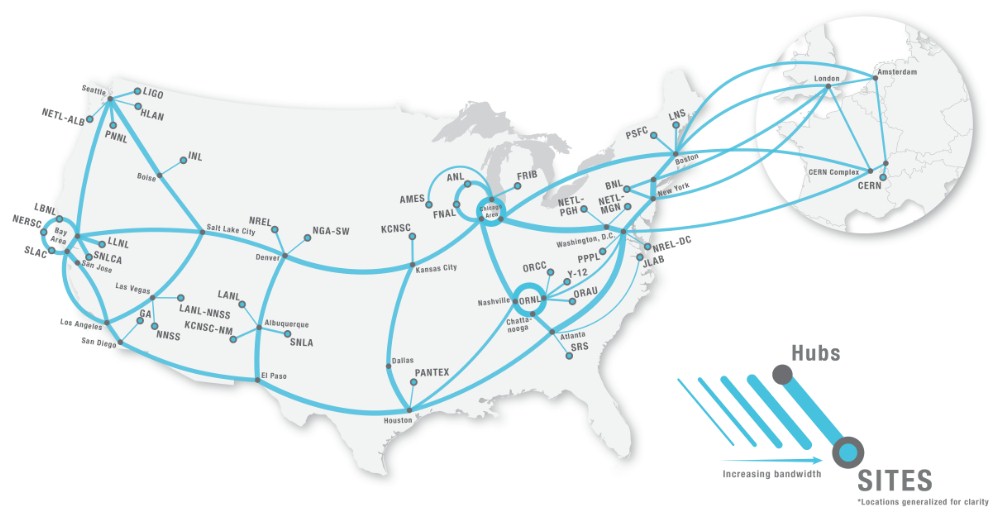
ESnet was most recently upgraded to ESnet6 in October 2022 and has 46 Tb/sec of aggregate bandwidth; its designers say that it can support multi-petabyte dataflows. One of the national laboratories is expected to host the HPDF hub, and its position on ESnet will be critical in the selection process.
“The facility will be designed to dynamically configure computation, network resources and storage to access data at rest or in motion, supporting the use of well-curated datasets as well as near real-time analysis on streamed data directly from experiments or instruments.”
The request for proposal for the HPDF project hub has three key computational and storage patterns, which often have conflicting needs and which make this whole hub-and-spoke idea a challenge to implement. We quote:
- Time-Sensitive patterns: Science cases requiring end-to-end urgency. For instance, streaming data for real-time analysis, real-time experiment steering, real-time event detection, AI-model inference, deadline scheduling to avoid falling behind.
- Data Integration-Intensive patterns: Science cases that demand combining and analyzing data from multiple sources. For instance, AI federated learning, combined analysis of data from multiple sites/locations, experiments, and/or simulations.
- Long-Term Campaign patterns: Science cases requiring sustained access to resources over a long time to accomplish a well-defined objective. For instance, sustained simulation production, large data processing and archiving for collaborative use and reuse.
Given the interplay of latency and locality with HPC compute and storage, a modest compute and storage capability located near the source of data often performance much better than a remote facility with a lot more theoretical performance. (This is why edge computing is a thing, after all.) This hyperdistributed approach is going to require new kinds of high availability and disaster recovery mechanisms and allow for the flexible provisioning across the spokes (and we would say edges connected to the spokes).
This HPDF project has been identified as a need by the Department of Energy since the summer of 2020, and the total cost of the project, including the hub and the spokes, is estimated to be between $300 million and $500 million, and DOE warns that $300 million should be the planning assumption, not $500 million because of the uncertainty of future appropriations from the US Congress. But for now, the HPDF hub is the only request for proposal; the call for proposals for the HPDF spokes will open up at an unspecified future date.
We will keep an eye out for when the HPDF bids are accepted and one is awarded to see how this will pan out. The assumption is the HPDF will be located in one of the DOE facilities on ESnet6, but you could certainly make the case for a slice of a datacenter of AWS, Microsoft, or Google located somewhere in the American Midwest. Why can’t the cloud be the HDPF and the labs be spokes? It will be interesting to see if AWS, Microsoft, or Google push to be able to bid on this HPDF proposal.

Data Reduction is the Next IT Frontier
“Ingest it all, keep everything, find that needle in the haystack,” they exclaimed. “Storage is cheap, analytics are powerful, there’s nothing you can’t do if you just keep all that data. Someday you might use it because business insights!” Remember that big data party? The one that spawned its own …

Nuclear Weapons Drove Supercomputing, And May Now Drive It Into The Clouds
If the HPC community didn’t write the Comprehensive Nuclear Test Ban Treaty of 1996, it would have been necessary to invent it. More than any of the many factors that drive the development of capability-class supercomputers, including the desire to do great science to change the world for the better …

Lawrence Livermore Kicks In Funds to Foster Omni-Path Networking
Decades before there were hyperscalers and cloud builders started creating their own variants of compute, storage, and networking for their massive distributed systems, the major HPC centers of the world fostered innovative technologies that may have otherwise died on the vine and never been propagated in the market at large. …
LANL would probably be a good spot for this (seeing how ORNL got Frontier, Argonne Aurora, LLNL El Capitan), maybe a POWER10 SerDes machine with Hopper GPUs could be justified somehow for this HPDF (it would help mix things up!). It is super to see fast networking gear and infrastructure enabling hyperdistribution of HPC; … and spreading a few HPDFs about (as you suggest I think) could certainly help with resilience and robustness of the eventual system, a kind of Redundant Array of Interconnected Data Hub Models — or RAIDHuMo — for example, eh-eh…). I could imagine one of these RAID Hubs at the CERN in Saint-Genis-Pouilly (on ESnet6) to further advance collaborative investigations on the fundamental nature of matter, keeping this EU Hub well away from Paris where there is currently 7,000 metric tonnes of uncollected trash on the sidewalks, as a result of strike action protesting the proposed retirement reform that nobody wants. 46 Tb/sec of aggregate bandwidth opens-up awesome opportunities for distributed HPC (wow!)!
Well, LANL got Tycho last October (SR Xeon apparently), in advance of Crossroads (SR Max), so the POWER10+H100 HPDF may have to land at a different labo…?