

Decades before there were hyperscalers and cloud builders started creating their own variants of compute, storage, and networking for their massive distributed systems, the major HPC centers of the world fostered innovative technologies that may have otherwise died on the vine and never been propagated in the market at large.
Lawrence Livermore National Laboratory, one of the HPC centers run by the US Department of Energy, is among the most important of such centers in the United States and in the world, and if you put a nuclear weapon to our head, we would concede that it is probably the most important. So when Lawrence Livermore invests in a technology or adopts one that has already been commercialized (or its adoption is an indication that it can be commercialized for those in-between cases), then it is important to listen.
And so it is with the $18 million investment that Lawrence Livermore is making into Cornelis Networks, the Omni-Path networking company that was spun out from Intel in September 2020. Thanks to the many acquisitions that Intel has done in the past decade, Cornelis is inheriting the rights to a lot of innovative networking technology and will be working with Lawrence Livermore to not just create faster InfiniBand switch ASICs, but to bring elements of these acquisitions together to meld a better implementation of InfiniBand from the best ideas available.
The recent Aquila networking project at Google, and its GNet protocol, which we wrote about a few weeks ago, validates many of the approaches that Cornelis is taking with Omni-Path and, we think, is strongly influenced by the idea of merging an InfiniBand-like software defined networking with the fine grained sub-packet data formats espoused by Cray in the “Aries” interconnect used in its XC supercomputers a decade ago and which has been replaced by a totally new “Rosetta” Ethernet switching system that also chopped data up into pieces smaller than a packet to do better adaptive routing and congestion control than might otherwise be possible.
The Cornelis Networks portfolio has a lot of intellectual property in it, and Phil Murphy, one of the co-founders of the company, intends to bring it all to bear in future Omni-Path Express interconnects running at 400 Gb/sec and 800 Gb/sec.
As we talked about when Cornelis Networks bought the Omni-Path technology from Intel, Murphy has deep roots in systems and networking, but what might not have been obvious is that the company has rights to all of the intellectual property related to the SilverStorm Technologies (founded by Murphy in 1999 around the same time Mellanox Technologies was founded) InfiniBand switches that are one of the foundations of the QLogic TruScale InfiniBand business. (The other is PathScale, also acquired by QLogic way back in 2006, which made InfiniBand host adapters.) And the way that the deal between Intel and Cornelis Networks is structured, the latter also has rights to the Cray “Gemini” and “Aries” supercomputer interconnects as well as the first and second generation Omni-Path interconnect created by Intel as a hybrid of TruScale and Aries.
The Omni-Path 100 Series (running at 100 Gb/sec) had a touch of Aries technology, but Omni-Path 200 was supposed to get some more and also had some differences that introduced incompatibilities that, frankly, Cornelis Networks is going to leave behind as it creates a more open implementation of InfiniBand based on the libfabric library of the OpenFabrics Interfaces working group. We did a deep dive on how Cornelis Networks is changing the Omni-Path architecture in July 2021 and it means dropping the InfiniBand verbs packet construct as well as the alternative Performance Scale Messaging, or PSM, approach created by PathScale and adopted in TruScale as an alternative to (but not a replacement of) InfiniBand verbs.
As we explained last July, this OFI stack was able to deliver 10 million messages per second per CPU core talking over the Omni-Path Express network, compared to 3 million to 4 million per core for the Mellanox implementation of InfiniBand (that’s a factor of 2.5X to 3.3X improvement) and a core to core round trip over the network is coming in at 800 nanoseconds, about 20 percent faster than using the PSM driver on the Omni-Path 100 gear from Intel.
In any case, this OFI stack is running on the existing 100 Gb/sec Omni-Path interconnect, and is available as an upgrade to the 500 or so Omni-Path customers that Intel was able to get in the HPC and AI markets.
One of the largest such Omni-Path customers is, of course, Lawrence Livermore, and Matt Leininger, senior principal HPC strategist at the lab, tells The Next Platform that machines under the auspices of the DOE’s National Nuclear Security Administration – which includes Los Alamos National Laboratory and Sandia National Laboratories as well as Lawrence Livermore, the so-called TriLabs in DOE lingo – have used earlier InfiniBand technologies from QLogic as well as Intel Omni-Path interconnects in systems. Today, says Leininger, the TriLabs have clusters that range in size from 100 nodes to as high as 3,000 nodes, which “serve as the everyday workhorses” as he put it, for a total of around 20,000 nodes collectively linked by Omni-Path. (Not all as one system, mind you.) That is a pretty big footprint.
The major HPC labs have their day jobs of running simulations and models, but their other purposes are to foster innovation, drive technology hard, and to make sure there are multiple vendors and multiple architectures to choose from in the supercomputing realm because you never know who or what might not make it and not all technologies are good at all things. This is why Tri-Labs has been a big supporter of QLogic InfiniBand and Intel Omni-Path even though, for instance, the current capability-class machine at Lawrence Livermore is “Sierra” with a 100 Gb/sec InfiniBand interconnect from Mellanox and next year the replacement “El Capitan” machine built by Hewlett Packard Enterprise will use 200 Gb/sec “Rosetta” Ethernet from its Cray unit.
The US government likes to have three choices and competition to drive down the price of supercomputers, and that is why Lawrence Livermore is investing $18 million into research and development for the next-generation Omni-Path Express technologies from Cornelis Networks. And it gets to work on co-designing the future Omni-Path interconnect alongside of the current applications running on the capacity clusters at Tri-Labs. And while no one is saying this, we will: If Omni-Path Express 400 Gb/sec and 800 Gb/sec can prove itself in terms of scale, low latency, and high bandwidth, there is no reason to believe the latter or its follow-on can’t be used in a 10 exaflops system at Tri-Labs somewhere down the road.
“We need a lot of advanced features beyond just a low latency and high bandwidth,” Leininger explains. “Things like advanced routing, congestion control, security features, traffic shaping – all of the stuff that becomes more and more important as you push to bigger machines and into topologies like dragonfly, for example. All of this is on the table, and how Cornelis goes about implementing these are up to them. They have some IP of their own and they can use IP that have from Intel. But how they decided to put things together to implement something that meets our requirements is up to them.”
One of the big goals, explains Leininger, is to drive competition for networking, which is a sizable chunk of the cost of a supercomputer cluster – somewhere around 15 percent to 20 percent of the cost is what we typically hear in high-end HPC systems, and that is in an era when memory and GPUs are very, very expensive compared to memory and CPUs in years gone by.
“Our commitment is really to drive the US HPC marketplace to be competitive with these high performance networks,” Leininger says. “We do want multiple solutions. The networks that are out there are good, but we are concerned about some of the consolidation that’s obviously going on in the marketplace over the last few years. And with the two networks that you mentioned – HPE Slingshot and Nvidia InfiniBand – one of them is tied to a system integrator and the other is tied to a component supplier. I can’t get Slingshot from anybody else but HPE. And what is Nvidia going to do over time with their support for things that aren’t Nvidia? We don’t know. So we’re concerned about losing our ability to develop best of breed solutions where I can go and choose whatever CPUs and GPUs or networks or system integrator I want and blend a solution together. By putting this funding towards Cornelis, we can meet some of those objectives. They can use various CPUs and GPUs, and multiple system integrators can use them. They’re independent, and it gets us back on track to having a good network that will give competition to those other two and allow us to continue developing best of breed solutions.”
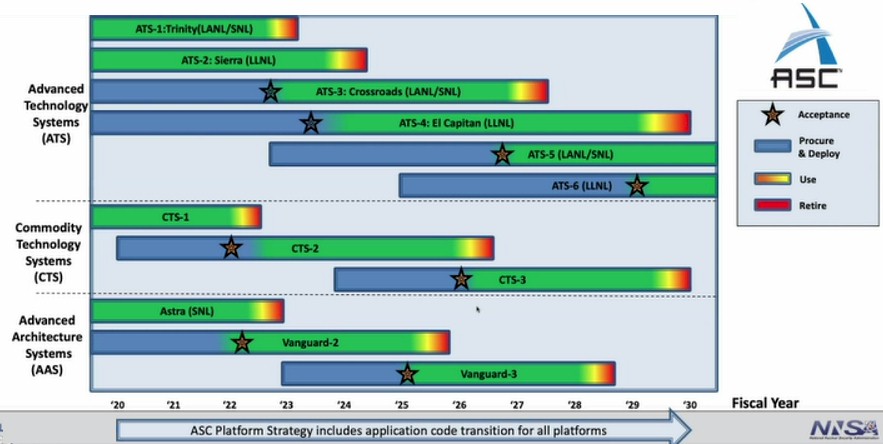
With the current Commodity Technology Systems machine, called CTS-2, which was awarded with a $40 million contract to system integrator Dell for $40 million last year, is based on Intel’s future “Sapphire Rapids” Xeon SP processors. We did a preview on Crossroads back in February, which costs $105 million, which is being installed at Los Alamos, which is based on HPE’s “Shasta” Cray XE system design, and which like El Capitan at Lawrence Livermore will use the Slingshot interconnect from HPE. The CTS-2 cluster will have a pair of Omni-Path Express adapters – one for each socket – per node and according to Leininger will have the capability of moving to the next generation Omni-Path Express 400 interconnect if this makes technical and economic sense. The CTS-3 follow-on machine is expected to be running by late 2025 to early 2026 (US government fiscal calendar, which ends in September each year, with procurement starting around two years prior to that in late 2023 to early 2024 fiscal years.
That CTS-3 upgrade times well – and intentionally so – to the Omni-Path Express roadmap, which according to Murphy has the 400 Gb/sec switches and interface cards coming out in calendar 2023 and the 800 Gb/sec devices coming out in late calendar 2025 to early calendar 2026. That timing, as you can see in the chart above, is also good for the ATS-6 kicker to El Capitan at Lawrence Livermore, whose procurement cycle starts in early fiscal 2025 and will be deploy in early fiscal 2029 (which means late 2029 to early 2030 calendar).
Cornelis Networks raised $500,000 in a venture round and another $20 million in a Series A and B funding rounds in September 2020 and August 2022, led by DownVentures with participation from Intel Capital, Alumni Ventures, Adit Ventures, and Global Brain. The $18 million coming from Lawrence Livermore does not involve the US government taking a state in Cornelis Networks, but is just accounted for as income against expenses as Cray used to do with the money it got from the US Defense Advanced Research Projects Agency to develop several of its previous supercomputer generations before Shasta.


Intel Aims For Zettaflops By 2027, Pushes Aurora Above 2 Exaflops
Just because Intel is no longer interested in being a prime contractor on the largest supercomputing deals in the United States and Europe — China and Japan are drawing their own roadmaps and building their own architectures — does not mean that Intel does not have aspirations in HPC and …

Gutting Decades Of Architecture To Build A New Kind Of Processor
There are some features in any architecture that are essential, foundational, and non-negotiable. Right up to the moment that some clever architect shows us that this is not so. What is true of buildings and bridges is equally true of systems and their processors, which is why we use the …
Intel’s Datacenter Business Goes From Bad To Worse, With Worst Still To Come
Everybody expected that Intel was going to turn in a pretty bad final quarter in 2022, and even before it posted its numbers yesterday after the market closed, there were plenty of signals that it was going to be worse. And it was. And the worst is still yet to …
Be the first to comment