
The hyperscalers and cloud builders are not the only ones having fun with the CXL protocol and its ability to create tiered, disaggregated, and composable main memory for systems. HPC centers are getting in on the action, too, and in this case, we are specifically talking about the Korea Advanced Institute of Science and Technology.
Researchers at KAIST’s CAMELab have joined the ranks of Meta Platforms (Facebook), with its Transparent Page Placement protocol and Chameleon memory tracking, and Microsoft with its zNUMA memory project, is creating actual hardware and software to do memory disaggregation and composition using the CXL 2.0 protocol atop the PCI-Express bus and a PCI-Express switching complex in what amounts to a memory server that it calls DirectCXL. The DirectCXL proof of concept was talked about it in a paper that was presented at the USENIX Annual Technical Conference last week, in a brochure that you can browse through here, and in a short video you can watch here. (This sure looks like startup potential to us.)
We expect to see many more such prototypes and POCs in the coming weeks and months, and it is exciting to see people experimenting with the possibilities of CXL memory pooling. Back in March, we reported on the research into CXL memory that Pacific Northwest National Laboratory and memory maker Micron Technology are undertaking to accelerate HPC and AI workloads, and Intel and Marvell are both keen on seeing CXL memory break open the memory hierarchy in systems and across clusters to drive up memory utilization and therefore drive down aggregate memory costs in systems. There is a lot of stranded memory out there, and Microsoft did a great job quantifying what we all know to be true instinctively with its zNUMA research, which was done in conjunction with Carnegie Mellon University. Facebook is working with the University of Michigan, as it often does on memory and storage research.
Given the HPC roots of KAIST, the researchers who put together the DirectCXL prototype focused on comparing the CXL memory pooling to direct memory access across systems using the Remote Direct Memory Access (RDMA) protocol. They used a pretty vintage Mellanox SwitchX FDR InfiniBand and ConnectX-3 interconnect running at 56 Gb/sec as a benchmark against the CXL effort, and the latencies did get lower for InfiniBand. But they have certainly stopped getting lower in the past several generations and the expectation is that PCI-Express latencies have the potential to go lower and, we think, even surpass RDMA over InfiniBand or Ethernet in the long run. The more protocol you can eliminate, the better.
RDMA, of course, is best known as the means by which InfiniBand networking originally got its legendary low latency, allowing machines to directly put data into each other’s main memory over the network without going through operating system kernels and drivers. RDMA has been part of the InfiniBand protocol for so long that it was virtually synonymous with InfiniBand until the protocol was ported to Ethernet with the RDMA over Converged Ethernet (RoCE) protocol. Interesting fact: RDMA is actually is based on work done in 1995 by researchers at Cornell University (including Verner Vogels, long-time chief technology officer at Amazon Web Services) and Thorsten von Eicken (best known to our readers as the founder and chief technology officer at RightScale) that predates the creation of InfiniBand by about four years.
Here is what the DirectCXL memory cluster looks like:

On the right hand side, and shown in greater detail in the feature image at the top of this story, are four memory boards, which have FPGAs creating the PCI-Express links and running the CXL.memory protocol for load/store memory addressing between the memory server and hosts attached to it over PCI-Express links. In the middle of the system are four server hosts and on the far right is a PCI-Express switch that links the four CXL memory servers to these hosts.
To put the DirectCXL memory to the test, KAIST employed Facebook’s Deep Learning Recommendation Model (DLRM) for personalization on the server nodes using just RDMA over InfiniBand and then using the DirectCXL memory as extra capacity to store memory and share it over the PCI-Express bus. On this test, the CXL memory approach was quite a bit faster than RDMA, as you can see:
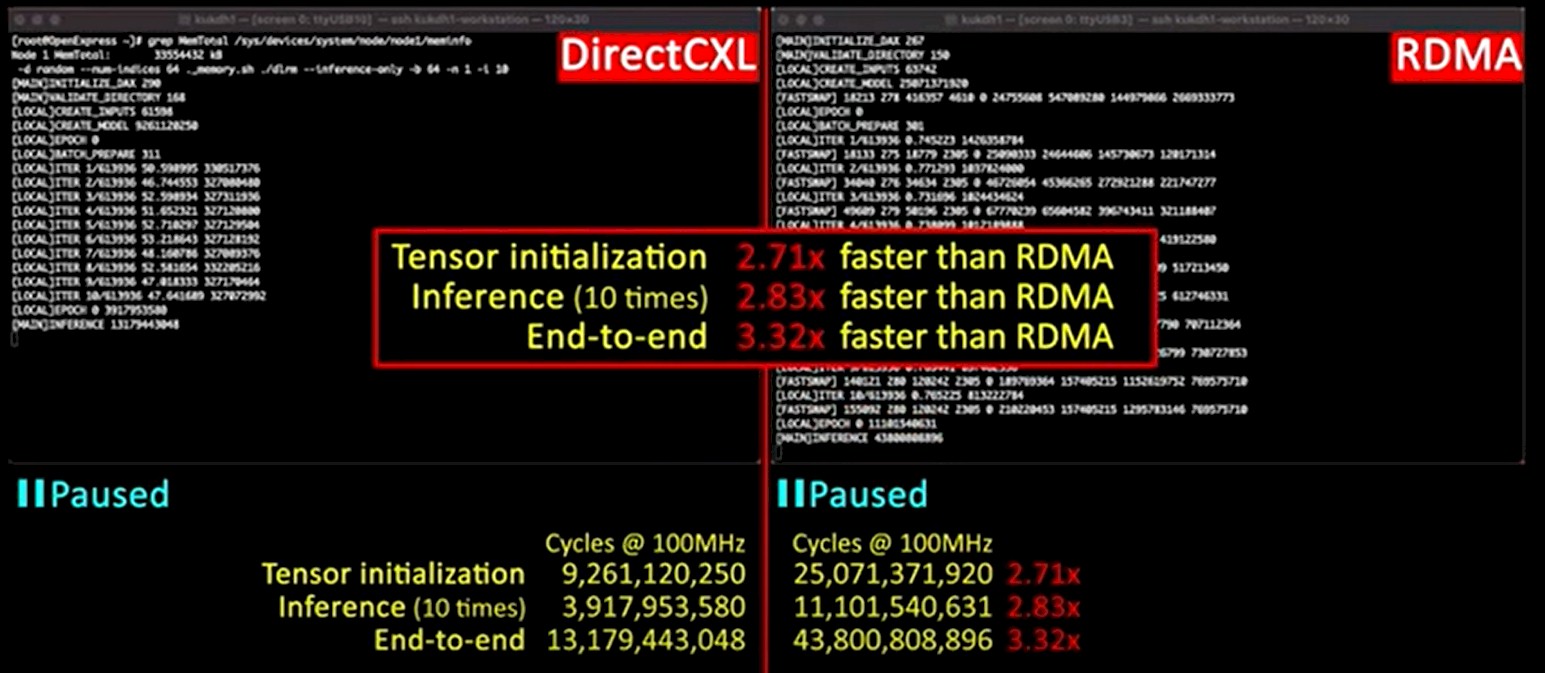
On this baby cluster, the tensor initialization phase of the DLRM application was 2.71X faster on the DirectCXL memory than using RDMA over the FDR InfiniBand interconnect, the inference phase where the recommender actually comes up with recommendations based on user profiles ran 2.83X faster, and the overall performance of the recommender from first to last was 3.32X faster.
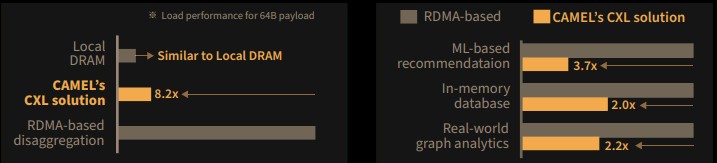
This chart shows how local DRAM, DirectCXL, and RDMA over InfiniBand stack up, and the performance of CXL versus RDMA for various workloads:
Here’s the neat bit about the KAIST work at CAMELab. No operating systems currently support CXL memory addressing – and by no operating systems, we mean neither commercial-grade Linux or Windows Server do, and so KAIST created the DirectCXL software stack to allow hosts to reach out and directly address the remote CXL memory using load/store operations. There is no moving data to the hosts for processing – data is processed from that remote location, just as would happen in a multi-socket system with the NUMA protocol. And there is a whole lot less complexity to this DirectCXL driver than Intel created with its Optane persistent memory.
“Direct access of CXL devices, which is a similar concept to the memory-mapped file management of the Persistent Memory Development Toolkit (PMDK),” the KAIST researchers write in the paper. “However, it is much simpler and more flexible for namespace management than PMDK. For example, PMDK’s namespace is very much the same idea as NVMe namespace, managed by file systems or DAX with a fixed size. In contrast, our cxl-namespace is more similar to the conventional memory segment, which is directly exposed to the application without a file system employment.”
We are not sure what is happening with research papers these days, but people are cramming a lot of small charts across two columns, and it makes it tough to read. But this set of charts, which we have enlarged, shows some salient differences between the DirectCXL and RDMA approaches:
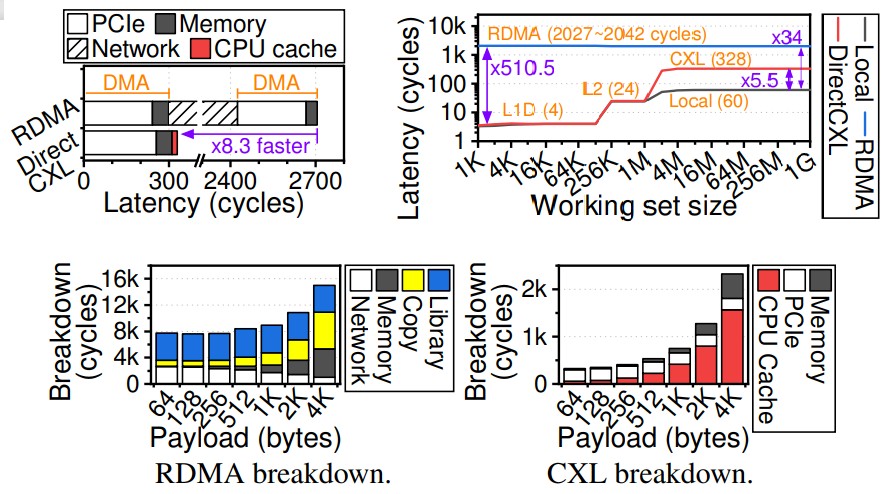
The top left chart is the interesting one as far as we are concerned. To read 64 bytes of data, RDMA needs to do two direct memory operations, which means it has twice the PCI-Express transfer and memory latency, and then the InfiniBand protocol takes up 2,129 cycles of a total of 2,705 processor cycles during the RDMA. The DirectCXL read of the 64 bytes of data takes only 328 cycles, and one reason it can do this is that the DirectCXL protocol converts load/store requests from the last level cache in the processor to CXL flits, while RDMA has to use the DMA protocol to read and write data to memory.


The Path Is Set For PCI-Express 7.0 In 2025
The ink is barely dry on the PCI-Express 6.0 specification, which was released after years of development in January 2022, we hardly have PCI-Express 5.0 peripherals in the market, and the PCI-SIG organization that controls the PCI-Express standard for peripheral interconnects already has us all coveting the bandwidth that will …

CXL And Gen-Z Iron Out A Coherent Interconnect Strategy
To one way of looking at it, a reprise of the Bus Wars from days gone by in the late 1980s and early 1990s would have been a lot of fun. The fighting among vendors to create standards that they controlled ultimately resulted in the creation of the PCI-X and …
How High-Bandwidth Memory Will Break Performance Bottlenecks
Intel recently announced that High-Bandwidth Memory (HBM) will be available on select “Sapphire Rapids” Xeon SP processors and will provide the CPU backbone for the “Aurora” exascale supercomputer to be sited at Argonne National Laboratory. Paired with Intel’s Xe HPC (codenamed “Ponte Vecchio”) compute GPUs running in a unified CPU/GPU …
Be the first to comment