
Intel recently announced that High-Bandwidth Memory (HBM) will be available on select “Sapphire Rapids” Xeon SP processors and will provide the CPU backbone for the “Aurora” exascale supercomputer to be sited at Argonne National Laboratory.
Paired with Intel’s Xe HPC (codenamed “Ponte Vecchio”) compute GPUs running in a unified CPU/GPU memory environment, Aurora will deliver more than an exaflop/sec of double-precision performance. Realizing or exceeding an exaflop/sec performance metric using 64-bit data operands means programmers don’t have to take shortcuts or accept precision compromises by using reduced-precision arithmetic. It does mean that the memory system has to deliver data far more rapidly than previous generations of processors. Along with HBM for AI and data intensive applications, the Sapphire Rapids Xeon SPs also implement the Advanced Matrix Extensions (AMX), which leverages the 64-bit programming paradigm to speed tile operations and gives programmers the option of using matrix reduced-precision operations for convolutional neural networks and other applications.
Maintaining sufficient bandwidth to support 64-bit exascale supercomputing in an accelerated, unified memory computing environment is a significant achievement that is cause for serious excitement and raises expectations in both the enterprise and HPC communities. The unified memory environment means, as Argonne: “Programming techniques already in use on current systems will apply directly to Aurora.” By extension, institutional, enterprise and cloud datacenters will be able to design highly optimized systems using next generation Intel Xeon SPs for simulation, machine learning, and high performance data analytic workloads (or succinctly HPC-AI-HPDA) using applications written to run on existing systems.
Rick Stevens, associate laboratory director of computing for environment and life sciences at Argonne National Laboratory, codifies the significance of the achievement and need for HBM when he writes: “Achieving results at exascale requires the rapid access and processing of massive amounts of data. Integrating high-bandwidth memory into Intel Xeon Scalable processors will significantly boost Aurora’s memory bandwidth and enable us to leverage the power of artificial intelligence and data analytics to perform advanced simulations and 3D modeling.”
Why Is HBM Important
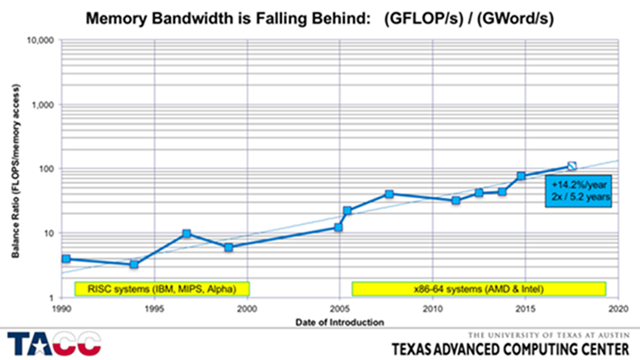
It has been known for a number of years that the ability of modern processors and GPUs to deliver flops has been rapidly outpacing the ability of memory systems to deliver bytes/sec. John McCalpin, the author of the well-known STREAM benchmark, noted in his SC16 invited talk Memory Bandwidth and System Balance in HPC Systems that peak flop/sec per socket was increasing by 50 percent to 60 percent per year while memory bandwidth has only been increasing by approximately 23 percent per year. He illustrated this trend with the following graph, where he charted the flops to memory bandwidth balance ratio of commercially successful systems with good memory performance relative to their competitors since 1990. Computer vendors are aware of the memory bandwidth problem and have been adding more memory channels and using faster memory DIMMs.
HBM devices reflect an alternative approach that utilizes 3D manufacturing technology to create stacks of DRAM chips built on top of a wide bus interface. An HBM2e device, for example, connects the DRAM stack to the processor through a bus interface of 1,024 bits. This wide data interface and associated command and address requires that the DRAM be built on top of a silicon interposer that essentially “wires” up the approximately 1,700 lines required for the HBM read/write transactions. The silicon approach is necessary as it is impractical to create such a large number of lines using printed circuit board (PCB) technology.
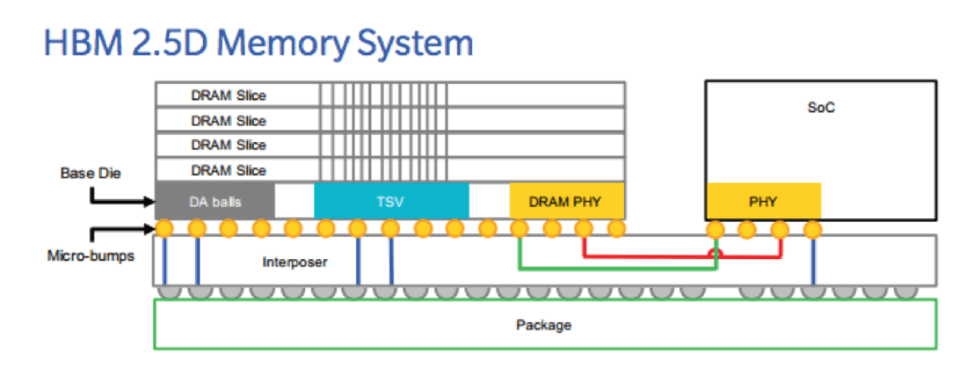
The result is a huge jump in memory bandwidth and a significant savings in power over DDR memory systems. EEWeb notes that “a single HBM2e device consumes almost half the power as for a GDDR6 solution.” It concludes, “HBM2e gives you the same or higher bandwidth than GDDR6 and similar capacity, but power consumption is almost half, while TOPS/W are doubled.” The TOPS or Tera Operations Per Second is a measure of the maximum achievable throughput given the bandwidth of the memory device. It is used to evaluate the best throughput for the money for an application such as neural networks and data intensive AI applications.
The Past is Prelude to the Future — Memory Bandwidth Benchmarks Tell the Story
Benchmarks demonstrate the impact of memory bandwidth increases on HPC applications quite well. Intel recently published an apples-to-apples comparison between a dual-socket Intel Xeon-AP system containing two Intel “Cascade Lake” Xeon SP-9282 Platinum and a dual-socket AMD “Rome” 7742 system. As can be seen below, the Intel twelve memory channels per socket (so 24 channels in the two-socket configuration) Intel Xeon SP-9200 series system outperformed the AMD eight memory channel per socket (sixteen total with two sockets) system by a geomean of 29 percent on a broad range of real-world HPC workloads.
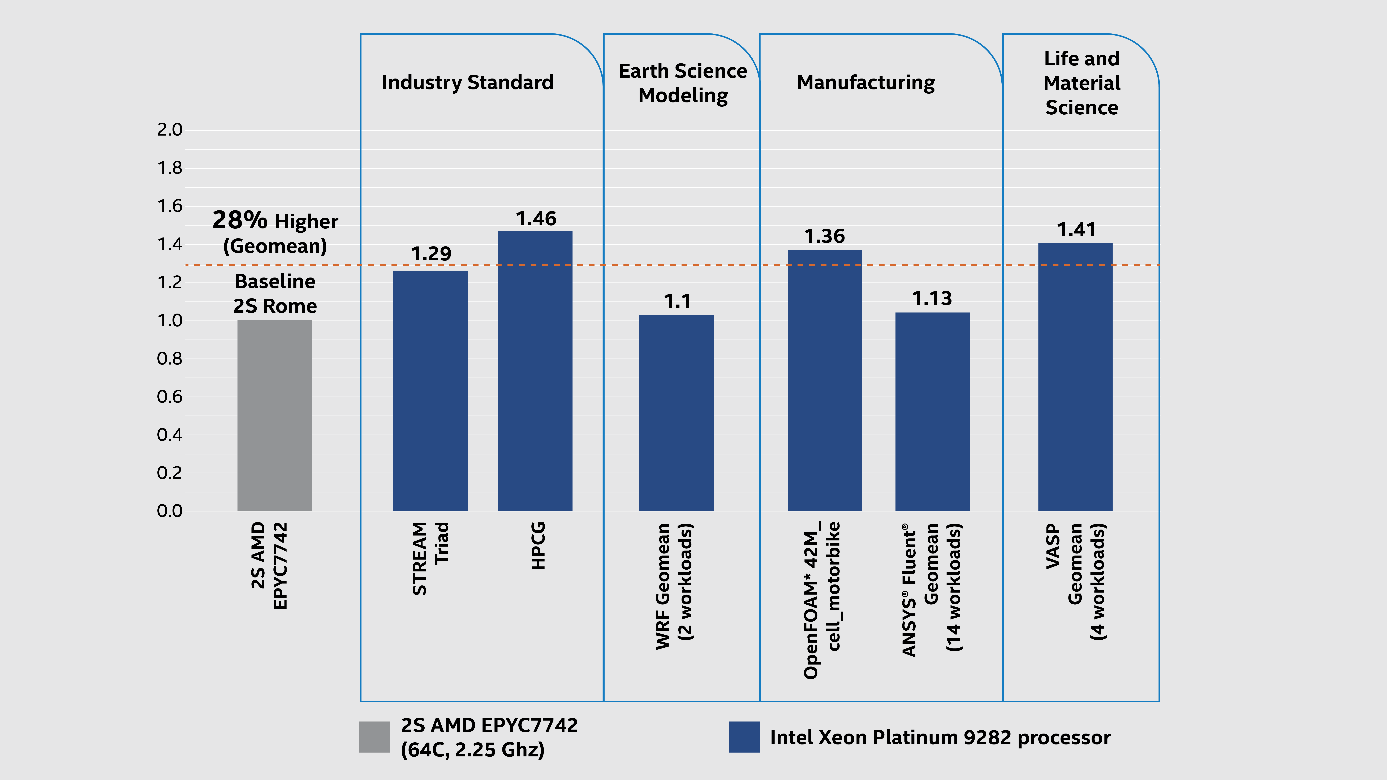
Impact of twelve memory channels versus eight memory channels on a variety of HPC benchmarks (Source: Only memory bound results reported in https://www.datasciencecentral.com/profiles/blogs/cpu-vendors-compete-over-memory-bandwidth-to-achieve-leadership)
The reason is that these benchmarks are dominated by memory bandwidth while others are compute-bound as shown below:
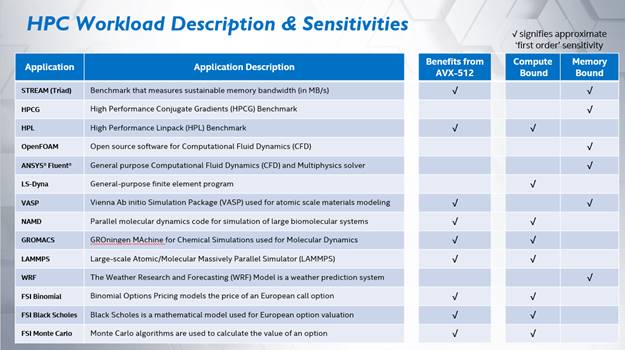
oneAPI Heterogeneous Programming Enables Next Gen Capabilities
The compute versus memory bandwidth bottleneck dichotomy illustrated in the chart above highlights how the combined efforts of the oneAPI initiative can help solve a multitude of compute and memory bottlenecks at the same time in an environment using a combination of CPUs, GPUs, and other accelerators. Succinctly, high memory bandwidth is fundamental to keeping multiple devices in a system and the per-core computational units supplied with data. Once there is sufficient bandwidth to prevent data starvation, then programmers can get to work to overcome the compute bottlenecks by making changes to the software.
The oneAPI heterogeneous programming approach helps enable these purpose-built, cutting-edge capabilities.
- HBM memory: Very simply, high computational performance cannot be achieved when the compute cores and vector units are starved for data. As the name implies, and as presented in this article, HBM delivers high memory bandwidth.
- Unified Memory Environment: A unified memory space gives both CPUs and accelerators such as the Intel Xe compute GPU the ability to access data in a straightforward manner. This means users can add the Intel GPU based on Xe architecture or based on Xe HPC microarchitecture speed compute-bound problems that are beyond the capabilities of the CPU cores. The additional bandwidth of the HBM memory system helps keep multiple devices busy and supplied with data.
- Intel AMX instructions: Intel added the AMX instructions to speed SIMD processing of some heavily utilized compute-bound operations in AI and certain other workloads. Core to the AMX extensions is a new matrix register file with eight-rank, two-tensor (matrix) registers — referred to as tiles. The programmer is able to configure the number of rows and bytes per row in the tile through a tile control register (TILECFG). This gives programmers the ability to adapt the characteristics of the tile to more naturally represent the algorithm and computation. The Sapphire Rapids Xeon SPs support the full AMX specification including AMX-TILE, AMX-INT8, and AMX-BF16 operations.
- oneAPI Cross-architecture Programming: oneAPI’s open, unified, cross-architecture programming model lets users run a single software abstraction on heterogeneous hardware platforms that contain CPUs, GPUs, and other accelerators across multiple vendors. Central to oneAPI is the Data Parallel C++ (DPC++) project that brings Khronos SYCL to LLVM to support data parallelism and heterogeneous programming within a single source code application. SYCL is a royalty-free, cross-platform abstraction layer built entirely on top of ISO C++, which eliminates concerns about applications being locked in to proprietary systems and software. DPC++ enables code reuse across different hardware targets such as CPU, GPUs, and FPGAs individually or orchestrating all the devices in a system can into a powerful combined heterogeneous compute engine that can perform computations concurrently on the varied system devices. A growing list of companies, universities, and institutions are reporting the benefits of oneAPI and its growing software ecosystem.
Looking To The Future
Of course, everyone wants to know how much memory bandwidth the new Intel Xeon Scalable HBM memory system will provide. This information still remains to-be-announced. According to Mark Kachmarek, who is Xeon SP HBM product manager at Intel: “The new high-bandwidth memory system for Intel Xeon processors will provide greater bandwidth and capacity than was available on the Intel Xeon Phi product family.” This provides a lower bound, which is exciting.
The real bandwidth of the Sapphire Rapids HBM memory system will be defined by the number of memory channels and performance of the HBM devices on each channel. Current HBM2 devices deliver between 256 GB/sec to 410 GB/sec, which gives us an idea of the performance potential of a modern HBM2 stacked memory channel. The number of memory channels supported by the HBM-enabled Sapphire Rapids Xeon SPs has not yet been announced.
Rob Farber is a global technology consultant and author with an extensive background in HPC and machine learning technology development that he applies at national labs and commercial organizations. Rob can be reached at info@techenablement.com.

Intel Puts Its Xe GPU Stakes In The Ground
For about a decade, Intel has sold GPUs, in recent years with its integrated CPU-GPU devices used in client and entry servers. But for the most part, at its heart and despite acquisitions of FPGA and NNP makers, Intel is still a CPU maker. Nvidia and AMD have for years …

3D XPoint Memory At The Crossroads
Like many system architects the world over, we had high hopes for the 3D XPoint variant of phase change memory (PCM) when it launched with much fanfare back in July 2015 after being developed jointly by Intel and Micron Technology for many, many years. This represented a new kind of …

Covering All The Compute Bases In A Heterogeneous Datacenter
Intel has spent more than three decades evolving from the dominant provider of CPUs for personal computers to the dominant supplier of processors for servers in the datacenter. While Intel has argued that Moore’s Law is not dead – that the pace of innovation with transistors and therefore semiconductors has …
“Sapphire Rapids Xeon SPs also implement the Advanced Matrix Extensions (AMX), which leverages the 64-bit programming paradigm to speed tile operations”
I believe the AMX operations on Sapphire Rapids only support bfloat16 and int8 operations … nothing 64 bit.
“The number of memory channels supported by the HBM-enabled Sapphire Rapids Xeon SPs has not yet been announced.”
I’ve seen different photos, each claimed to be Sapphire Rapids, one with 8 HBM stacks and the second with only 4. I believe HBM has 8 memory channels per stack, so either 32 or 64 channels added to the 8 channels of DDR5.
see the tomshardware article, “Intel Shows Off Multi-Chiplet Sapphire Rapids CPU with HBM”, from Oct 16, for example.