

The big three clouds – Amazon Web Services, Microsoft Azure, and Google Cloud – are all addressing the same issues of scale, performance, and economics and are also trying to attract the same workloads from the same pool of enterprise, government, and academic customers. So it is not really a surprise that the compute and storage infrastructure and the database and middleware services that these three companies have created look very similar.
But they are not the same, and that causes friction that keeps applications from being as portable across these clouds as many organizations had hoped they would be. Frustrated by this, researchers at the University of Maryland and the US Army Research Laboratory have created an open source toolkit called RPAC, short for Reproducible and Portable Analytics in the Cloud, that brings some of the cloud agnosticism everyone is seeking to avoid the much-maligned vendor lock-in that the big clouds enjoy to the same degree – we have argued to a larger degree – than the dizzying array of proprietary systems from days gone by in the 1960s, 1970s, and 1980s.
This time around, to bring more portability and reproducibility to applications running on the cloud, we don’t have to have a Unix Revolution, but we do have to leverage higher-level services that are akin to the SPEC 1170 Unix APIs that made Solaris, AIX, HP-UX, and other Unixes “compatible.” (That is our analogy, not the researchers who created the RPAC abstraction layer.) That means making use of aspects of modern clouds such as serverless function processing, generic object storage, and container controller platforms, to allow applications to span multiple clouds, argue the researchers. And the RPAC toolkit, described in a recent paper, shows how this layer of abstraction might be created and the relatively small performance penalty that might be incurred in production environments as they run across multiple clouds atop this abstraction.
Reproducibility has a number of different means, and rather than fight about them and how they compare and contrast with other terms such as replicability and repeatability, the idea is that you get the same results across different clouds with the same code and pipeline of data manipulation associated with that code. It is not just being able to run the same exact dataset through and application to get the same answer that makes it reproducible, but such an environment as implemented by tools such as RPAC have to allow for different datasets and application parameters in the application pipeline and still run within the same cloud provider and also across multiple cloud environments. Like this:
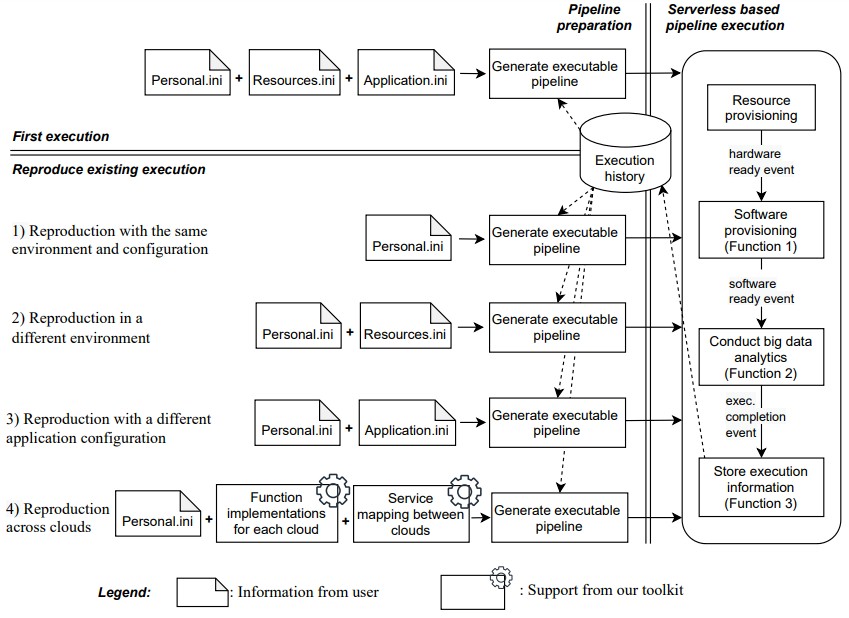
While one could build a containerized set of applications running atop Kubernetes and plunk microservices code representing an application into any of the big three clouds that the RPAC researchers examined, they suggest that wherever possible, applications should be created using serverless functions, which are priced at a much finer grain for execution – seconds for a function instead of hours for a virtual machine instance – and equally importantly, the amount of the underlying computing needed for the serverless functions and the provisioning of that capacity is managed by AWS, Azure, and Google Cloud themselves. This is a valid point, but one that will be unfamiliar to many organizations.
What really makes portability and reproducibility possible is time and the fact that all of the big clouds have seen the rise of various services at their competitors and then implemented a functional equivalent. Again, just like the SPEC 1170 standard gave Unix applications a set of APIs that would be common across Unixes, the equivalency of the services on the big clouds means that a tool like RPAC can be created to manage the differences between the clouds programmatically and automatically. Here are the key services that data analytics workloads might need – and indeed, any set of applications. The RPAC researchers focused on applications running in Spark, Dask, and Horovod for their research, but there is no reason this approach cannot be applied more generically.
Here is how the important cloud services stack up on AWS, Microsoft Azure, and Google Cloud:
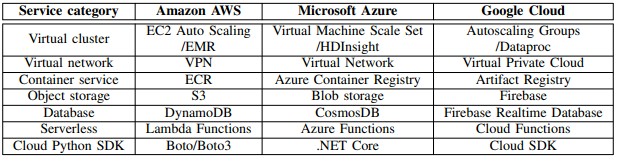
Here is how the researchers describe these functions:
- The virtual machine cluster that enables hosting distributed data analytics engines
- The virtual network service manages and monitors networking functionality for cloud resources
- The container service stores, manages, and secures container images in private or public
- The object storage service stores, manages, and secures any amount of data in storage
- The database service provides a scalable and secure NoSQL cloud database
- The serverless service runs and manages the application with zero server management
- The cloud Python SDK provides an easy-to-use interface to access cloud services
The RPAC toolkit, which is available on GitHub as open source, currently works on AWS and Microsoft Azure but has not yet been ported to Google Cloud. RPAC takes the application pipeline file and provisions the hardware and software and then the data analytics workload on top of that provisioned stack, executes it, and then shuts it down. This is, in essence, a lot of what Google’s Borg cloud controller does, and it is our understanding that many of the applications that are created at Google are written at a very high level and Borg figures out how to parallelize the data and code to run whatever batch or interactive jobs it is handed simultaneously at any given time. RPAC does not do job scheduling, as Borg does, but it looks like it is doing the kind of provisioning that Borg has to do for any given job.
Spark in-memory computing services are available as a service on some of the clouds, but neither Dask, an open source framework for parallel execution of Python applications, nor Horovod, a distributed framework for deep learning training that supports frameworks such as TensorFlow, PyTorch, and MXNet and that obviously makes use of GPU accelerators, are available as hosted services by the big clouds. So Dask and Horovod have to be containerized and loaded up on virtual machine images by RPAC. Which RPAC is happy to do. The idea is to use the automated service from a cloud when you can, and to essentially create the service yourself when you can’t.
The RPAC creators took three different data analytics workloads on these three different frameworks and implemented them atop AWS and Microsoft Azure and gauged the overhead of running the RPAC layer atop the clouds to ensure reproducibility and portability.
The first one, called cloud retrieval, has nothing to do with IT infrastructure but rather is a machine learning algorithm riding atop the Dask framework that can look at satellite images and define the clouds; it is written in Python, uses the scikit-learn library and has a dataset of around 500 MB, which is not all that fat in the scheme of things. The overhead of using RPAC compared to running it natively on the cloud iron (on from one to eight instances) averaged a mere 1.28 percent.
The second test, called causality discovery, seeks to establish cause-effect relationships in datasets. This workload runs atop Spark/Hadoop and is written in Python, and has 200,000 rows of time series records that comprises about 10 MB of data. Again, the application is run on from one to eight instances, in this case only on AWS, and the RPAC overhead averaged 3.58 percent.
The final workload, called unsupervised domain adaptation, is a machine learning technique to transfer the model created from labeled domain data and extended it to a set of unlabeled domain data. This setup was spun up in virtual machines on the AWS and Azure clouds using the PyTorch machine learning framework underpinned by Horovod and the MPI memory sharing stack commonly used in parallel HPC applications. The dataset used had about 50 MB, and scale was tested across one to eight instances on the AWS and Azure clouds. The overhead of RPAC on this workload was 2.17 percent.
There is an interesting set of charts that compares the execution time for applications, the cost, and the price-performance (not price/performance) ratio for the runs across these clouds for these three workloads. In general, as you might have guessed, scaling up an application on a larger image has a better price-performance ratio (that is a product, not a division) than scaling it out, and AWS has slightly better price-performance than Azure.
We wonder if the performance overhead of a tool like RPAC starts to come into play with larger scale applications or larger datasets, but it seems unlikely. If anything, the scale limits of the services running on the big clouds will determine which one gets used for what, and that may be the biggest limitation to cloud portability and reproducibility in the long run.




Be the first to comment