

There are good reasons for the persistence of C, C++ and Fortran in high performance computing, even with some the inherent productivity challenges (extensive memory management and debugging in particular). There are plenty of workarounds for these issues but they can sometimes come with a performance price.
Even though languages with managed runtimes have had a tough time finding an entry point, some argue that the benefits of automatic memory management and built-in bounds checking are more critical than ever, especially with growing heterogeneity.
Enter the Julia programming language, which got its start in 2012 with HPC in mind and has slowly (but surely) established a bit of a cult following. That anecdotal evidence has been tested recently across a number of hardware platforms (CPU/GPU from Intel, AMD, Nvidia, Marvell, Fujitsu) and compared to other parallel programming frameworks (OpenMP, Kokkos, OpenCL as well as CUDA, oneAPI and SYCL) by a team at the University of Bristol with positive results.
“Traditionally, HPC software development uses languages such as C, C++, and Fortran, which compile to unmanaged code. This offers the programmer near bare-metal performance at the expense of safety properties that a managed runtime would otherwise provide. Julia, on the other hand, combines novel programming language design approaches to achieve high levels of productivity without sacrificing performance while using a fully managed runtime.”
One benefit of paying attention to work out of Bristol is because HPC teams have broad access to a wide range of hardware platforms, including Fujitsu A64X devices. The nearby Isambard supercomputer and HPC Zoo, both at Bristol, are solid platforms for evaluating system architectures. Teams also used Intel’s Dev Cloud cluster for Intel-specific comparisons among other HPC compute resources.
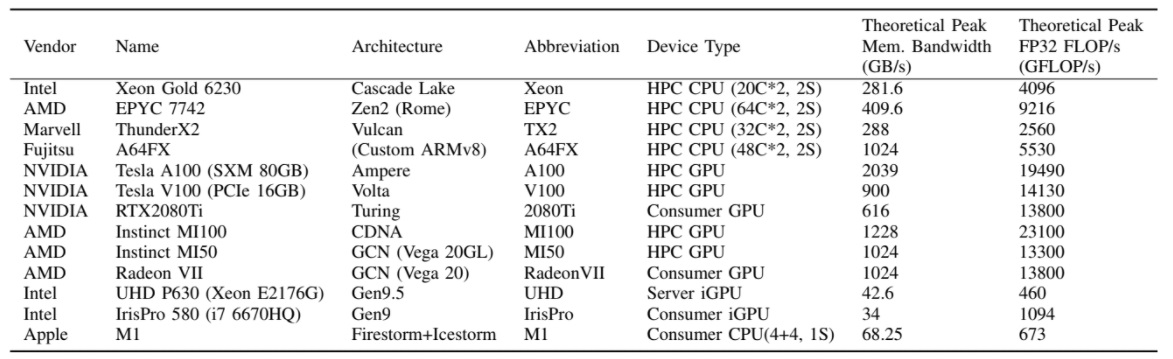
The Bristol results, gathered by leads Simon McIntosh-Smith and Wei-Chen Lin are based on two mini-apps designed to evaluate performance portability, one memory-bound (BabelStream) and another compute-bound (miniBUDE). The codebase for both provide multiple implementations of the kernels for the various frameworks.
For this comparison, Julia was stacked against Kokkos and OpenMP for BabelStream for CPUs and for Nvidia GPUs, they compared against CUDA, Kokkos and OpenCL. For AMD GPUs they compared the AMDGPU.jl and KA.jl implementations to HIP, Kokkos and OpenCL with Intel GPU comparisons based on oneAPI.jl to oneAPI, SYCL, and OpenCL with the above hardware configurations.
For memory-bound BabelStream, performance was almost the same against OpenMP and Kokkos for CPU but the Fujitsu A64X took some extra footwork given some compiler holes. Once those were worked out, Julia matched LLVM performance. For GPU, Julia performed close to vendor frameworks but for AMD the package was around 40% slower than the best framework. Authors say this is because of the immaturity of the ROCm stack and the fact that the AMDGPU.jl base is still in beta.
For compute-bound miniBUDE, the team says they could get a better grasp on floating point optimizations. “In general, x86 CPU platforms performed well, although Julia was not able to permit AVX512 on platforms that support it.” The A64X problems surfaced here too as both LLVM and Julia had trouble capturing high peak FP32 performance. “For GPUs and miniBUDE, they say Julia was similar to OpenCL.
“Julia’s performance either matches the competition or is shortly behind,” project leads explain. “Julia offers us a glimpse of what is possible in terms of performance for a managed, dynamically-typed programming language. Given the overall performance-guided design of Julia, the LLVM-backed runtime, and comparable performance results, we think Julia is a strong competitor in achieving a high level of performance portability for HPC use cases.”
Full benchmarking and configuration details here.




Be the first to comment