
Any tech startup that wants to live beyond is seed and venture funding rounds and make it to either an initial public offering or an acquisition by a company threatened by their very existence has to do two things. One, have a laser focus on precise markets and products that meet them. And two, have a maniacal focus on execution.
Last week, we had a long chat with Renee James, founder and chief executive officer of Arm server chip upstart Ampere Computing last week, about the prospects of selling millions of server CPUs to the hyperscalers and cloud builders, many of whom can’t easily or cost-effectively create their own Arm compute engines despite the fact that Amazon Web Services is clearly showing it can be done with its Graviton line and its Nitro DPU offshoot. This week, we want to go over the Ampere Computing roadmap, which is a kind of barebones form for public consumption but which no doubt has a lot more meat on it when it is given to the hyperscaler and cloud builder customers that the company is clearly, vocally, and solely targeting.
And then we want to do a thought experiment about how Ampere Computing might be pulled into the enterprise server CPU space anyway. A bit like a fox and a wolf being tricked by a rabbit into throwing the bunny into the briar patch, perhaps.
With that, onto the barebones Ampere Computing processor roadmap, which you can take a gander at here:
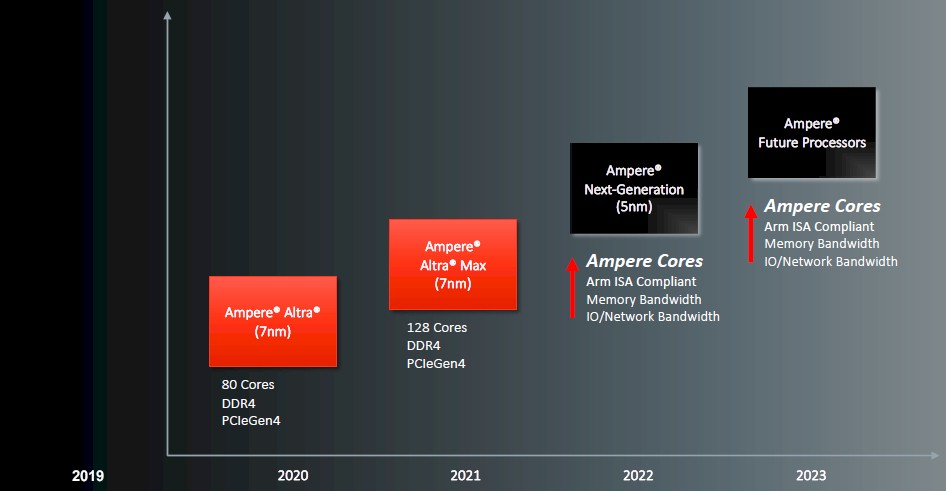
And here is how we augmented it to show what happened from the beginning and what we think is happening in the future:
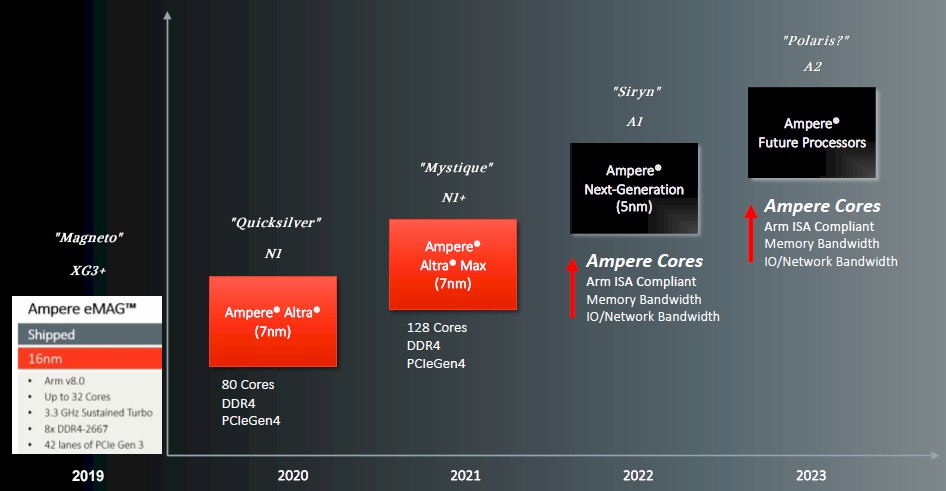
We added in the code names of the first three chips that Ampere has brought to market, and we find it funny that to date the codenames for the four chips under construction by the company have been based on Marvel (one L) superheroes and that Marvell (two Ls) was the main rival of Ampere Computing in delivering Arm server chips to the hyperscalers and cloud builders. Marvell has since left the field after not finding buyers for its “Triton” ThunderX3 chip and its custom, hyperthreaded core. The 80-core “Quicksilver” Altra chips have been shipping since last year, and the 128-core “Mystique” Altra Max chips are sampling now and will ship in the third quarter. The “Siryn” chip will be the first 5 nanometer Ampere Computing part, and we are assigning the future 2023 chip the codename “Polaris,” after the Marvel superhero of that name who is the sister of Quicksilver – both the children of Magneto, as it turns out. (If we are wrong, we will update this story.)
What was also not shown on this new 2021 roadmap is the original Ampere Computing eMAG 1 chip, which was roughly based on the intellectual property that it acquired from Applied Micro, the original enterprise grade, server class Arm CPU startup. So we added that back in. The X-Gene 3 design was tweaked, of course, when Ampere Computing decided to enter the server racket. eMAG could possibly refer to “Magneto,” the archvillain turned good guy from the X-Men franchise, of course, but we long thought it was also short for Microsoft, Amazon, Google, who were the three most likely hyperscaler and cloud builder customers interested in Arm server chips when Ampere Computing was founded in October 2017. Why not both?
In any event, if hyperscalers and cloud builders buy roadmaps, not point products, as James told us, they didn’t buy this one we are seeing above and that we augmented a little to add in the complete history. The roadmaps that these customers are seeing must have a lot more feeds and speeds on it. Feel free to send it to us, Google or Microsoft. Or Amazon, which may find itself buying future Altra processors from Ampere Computing at some point, too. The Graviton chips are differentiating now because there was no other decent Arm server CPU in the field, and Amazon has to build its Nitro DPU processors anyway. But, if the Altra volumes ramp up and Ampere Computing makes better chips at a cheaper price than Amazon can do itself, you can bet your Prime delivery service contract that AWS will change the tune in a heartbeat. Particularly if there are SKUs of the Altra line that can work like a Nitro DPU as well.
This vertically integrated stack argument for the hyperscalers and cloud builders can be taken too far. Why spend a few hundred million bucks on chip design and manufacturing tuning to save a few hundred million bucks off the price of commercial CPUs if, in the end, there might not be any real differentiation? We shall see how the costs and strategies line up, and we think that the hyperscalers and cloud builders might hedge for a while and build as well as buy Arm server chips as well as pit Intel and AMD against each other in the X86 server CPU space.
It is going to get real interesting, folks.
There are a couple of things to notice in that Ampere Computing roadmap above. First, there is an annual cadence to product releases, which is why hyperscalers and cloud builders want. And the reason is simple: A new product implies a price/performance improvement at list price. This is how it used to be in the server CPU racket for so long, and product roadmaps got all stretched out by the death of Dennard scaling a decade ago and by Moore’s Law being sick now.
Let’s go back a little further in history with Applied Micro. Take a look:

The Applied Micro cadence was about two years between generations, with the “Storm” X-Gene 1 that debuted in 2014 having eight cores running at 2.4 GHz and four DDR3 channels, etched in 40 nanometer processes from Taiwan Semiconductor Manufacturing Corp. The “Shadowcat” X-Gene 2 that started sampling in 2014 and that came out in 2016, stayed at eight cores and shrank to 28 nanometers with a slight boost in clock speed to 2.8 GHz and integrated RoCE RDMA for the Ethernet controllers on the chip. The “Skylark” X-Gene 3 chip was slated for a shrink to 16 nanometers with 16 cores, and somewhere along the way that core count was bumped up. And that is what Ampere Computing delivered in the eMAG 1 chip, but the company didn’t just slap a new name on the Skylark chip from Applied Micro.
Ampere Computing is picking up the pace as well as also committing to not missing a step – something that Applied Micro and Intel have done, and in the latter case, that AMD has been able to exploit with its Epyc line of X86 server processors as Intel has had delay after delay with its Xeon SP lineup.
From the looks of things, we would guess that Ampere Computing will try to get two generations out of each manufacturing process node, the same as AMD has been doing with the “Rome” Epyc 7002s and “Milan” Epyc 7003s. AMD has put out a new core with each generation but sometimes kept the core count constant (as it did with the Milan chips, for instance).
Ampere Computing could do that, or it could just keep trying to cram more cores into each new generation. It is far more likely, however, that Ampere Computing will fall into a pattern like AMD’s Epycs have started to have, where the new process allows a bump in core count and the refined process allows for a new core and some faster clocks and a chance to increase the amount of work done per core. The memory and I/O will be updated along with the process shrink, so in this case moving to PCI-Express 5.0 peripherals and DDR5 memory with the “Siryn” generation of Altra chips in 2022, and then doing refinements with the cores and I/O on the “Polaris” kickers in 2023, which we expect to also be etched in a refined 5 nanometer process rather than a 4 nanometer or 3 nanometer shrink.
As the eye doctor once said to us when she showed us what real 40/20 vision might look like using her computer-enhanced eye testing gear: “You can’t have that now. You gotta save some for later.”
The question we have, and that Ampere Computing did not answer, is whether the Siryn and Polaris chips will be compliant with the new Armv9 specification and instruction set, but we strongly suspect they will be. What they will not be is based on Arm’s own Neoverse V1 or N2 cores, but a core designed by Ampere Computing, and one that does not have simultaneous hyperthreading because that doesn’t boost performance enough to sacrifice the predictable, deterministic performance that comes from having the core as the fined grain of compute in the chip. The Quicksilver chips were based on Neoverse N1 cores, and the Mystique chips have a modified N1 core – without hyperthreading since Arm Holdings doesn’t believe in it any more than Ampere Computing does. It is not clear what Ampere Computing is doing in its cores, but Jeff Wittich, chief product officer at the company, hints that the design is as much about taking out stuff that hyperscalers and cloud builders don’t need as it is about adding in things that they do.
“We are an Arm licensee and we have been working on these Ampere cores for the past three and a half years, since Day One,” Wittich tells The Next Platform. We are calling the initial one the A1 core and the follow-up the A2 core because Ampere Computing has not given them names, and we added this to the official Ampere Computing roadmap that we edited above. “They will be Arm ISA compliant, and we want to remind everyone that it takes years to build a core from scratch. These cores were not derived the N1 cores used in Altra and Altra Max, or from Arm N1 or V1. We built these from the ground up and it is our own microarchitecture.”
While not being specific when we asked what makes the Ampere cores different, when pressed for some insight, Wittich says that the noisy neighbor problem is tough, and isolating workloads for performance and security reasons – or rather, doing it well – requires for it to be built in from the beginning. Wittich also says the Ampere core design will inherently support horizontal scaling across sockets and nodes better and have less sharing of resources within the socket (presumably caches and other features) and better isolation of resources. More than this, Wittich is not at liberty to say right now.
We also know that the Siryn chips will have more cores than the Altra Max chip, which could mean 192 cores or even possibly 256 cores. Ampere Computing could do 192 of what we are calling the A1 cores in 2022 and then ramp that up with a refined 5 nanometer process to 256 cores in 2023, using a refined A2 core. Or it could save a radically improved A2 core for the 2024 annual upgrade bump. A lot depends on the needs of the market.
We will close with an important question: If a hyperscaler or cloud builder doesn’t need it, why do you? If these chips are good for the Super 8 and their Slightly Less Super friends who are near hyperscale – sorry Oracle, but you ain’t a hyperscaler and neither is ByteDance and a few of the other early Altra adopters – then why not for any enterprise customer who is looking to build a modern platform to run microservices on a Kubernetes container platform?
Technology has to trickle down from on high as well as seep upwards from below. That is what The Next Platform is all about. And Arm server chips bring both of these forces to bear. That’s why we think eventually Ampere Computing will go mainstream, whether or not it wants to talk about it today. Some server maker somewhere will want to sell these. For sure.

Power Efficiency, Customization Will Drive Arm’s Role In AI
More than a decade ago, executives at Arm Ltd saw the energy costs in datacenters soaring and sensed an opportunity to extend the low-power architecture of its eponymous systems-on-a-chip that has dominated the mobile phone markets from the get-go and took over the embedded device market from PowerPC into enterprise …
The Big Clouds Get First Dibs On AMD “Genoa” Chips
The expanded lineup of AMD’s 4th generation “Genoa” Epyc server chips – built atop “Zen 4” core and some with the chip maker’s L3-boosting 3D V-Cache – unveiled at a high-profile event in San Francisco this week is quickly making its way into the cloud. Microsoft and Amazon Web Services both …

Where China’s Long Road To Datacenter Compute Independence Leads
While we are big fans of laissez faire capitalism like that of the United States and sometimes Europe — right up to the point where monopolies naturally form and therefore competition essentially stops, and thus monopolists need to be regulated in some fashion to promote the common good as well …
Price/performance improvement at annual cadence below 7nm would imply continues architectural evolution if one wants to avoid the area-yield inverse proportionality. This is something very challenging to achieve and it would be interesting to observe if Rene can outperform her former employer in the long term. One thing is certain – the industry wants them to succeed.