

Steve Fingerhut looks to the GPU when explaining what his company, Pliops, is working to achieve.
Driven by Nvidia over the past several years, GPUs have become the go-to processors for running artificial intelligence (AI) and machine learning workloads in datacenters and in the cloud. In the same sense, Pliops, a four-year-old Israeli startup, is looking to do the same with its new Extreme Data Processor (XDP): Make it the domain-specific chip architecture for accelerating data-intensive workloads.
“Our approach is what’s been termed a domain-specific architecture has been used a lot in the AI space,” Fingerhut, Pliop’s president and chief business offer, tells The Next Platform. “Think about the GPU for AI. Let’s do the same thing for all the applications that drive most of the flash consumption, which are database analytics, software-defined storage, that class of products. What can we do that will make that GPU-like? You can run all your algorithms on an X86 processor [or] an Arm processor, but if you run them on a GPU, they’re just going to be many times faster. Let’s take that same approach and find fundamental functions that are universal across these different applications, build a dedicated processor for them that will accelerate and offload those functions.”
The data challenges for enterprises have become familiar. First, there is a lot of it being generated and that trend is only accelerating. IDC is forecasting that in 2025, there will be 175 zettabytes of data created. In addition, organizations need fast access to that data to run analytics on it, essentially turning those mountains of data into information upon which business-critical decisions can be based. All of this data processing and analytics takes significant compute power, putting tremendous strain on the CPU. Pliops is looking to offload much of that work from the x86 or Arm CPU and onto its XDP, which will free up compute power for other tasks and while enable the system to accelerate the performance of those workloads.
Domain-specific processors have come to the forefront in recent years, as new use cases have emerged that need more performance than general-purpose CPUs can offer and Moore’s Law continues to slow, making it more difficult for CPUs to match the compute needs of these use cases. There are now GPUs, data processing units (DPUs), digital signal processors (DSPs), among others. Pliops wants to slip its XDP into this growing list.
The company – whose backers include Intel, Nvidia, Xilinx, and Western Digital – has been working on the storage processor since 2017 to make it easier and faster for enterprises to access data kept in flash storage. Pliops is continuing to broaden its use cases to include relational, NoSQL and in-memory databases as well as AI, machine learning, analytics, 5G and Internet of Things (IoT) workloads.
The XDP is an accelerator in a PCI-Express card form factor that attaches via the PCI bus of a server or as a cloud service. The XDP uses a thin host layer for transferring I/Os to the flash storage. It allows for scalability and cost efficiency by supporting whatever flash the organization wants, whether its TLC (triple-level cell) NAND flash or QLC (quad-level cell) flash.
It presents two interfaces to the host using the NVM-Express driver. One is a block interface, which uses compression, enables storage of up to 128 TB of data on 64 TB of SSDs and essentially looks like any other block device. The other is a native key-value (KV) interface.
“This is what applications are using to talk to what’s called the Storage Engine,” Fingerhut says. “It allows us to replace that using the existing API. If a product like MySQL or Ceph is using standard RocksDB for its storage and in function, we can replace that as binary compatible. It really does not require recompile. It’s just a dynamic link change. You’ll get basically the hardware-accelerated performance that we offer. That’s a big strategy for us. You don’t need to change your software, you don’t need to change your architecture. We fit into existing APIs.”
Through the block interface, organizations will see as much as three to five times improvement in workload performance, he says. With the KV interface, performance increases can be as high as 15 times over general-purpose CPUs. The XDP delivers up to 3.2 million random read and 1.2 million random write IOPS.
“Once the I/Os are in inside of our device, then we perform very fast, efficient compression fully hardware offloaded,” Fingerhut says. “That’s the easy part. The hard part is our core IP, this key value-based Storage Engine. When you get these variable size objects, in the case of block, we treat them as a special a special key value type, essentially. But no matter what, once you compress even a fixed block, it’s variable inside. The hard part is then merging, sorting, indexing and then garbage collecting, meaning something changes or is deleted, you have to unpack [and] eventually update that and then we commit that to disk. That’s where you get those huge write amplification numbers. We’re doing this in hardware. This is where we’ve created a new data structure, new algorithms that are extremely efficient. We bring read, write and space amplification to their theoretical minimums.”
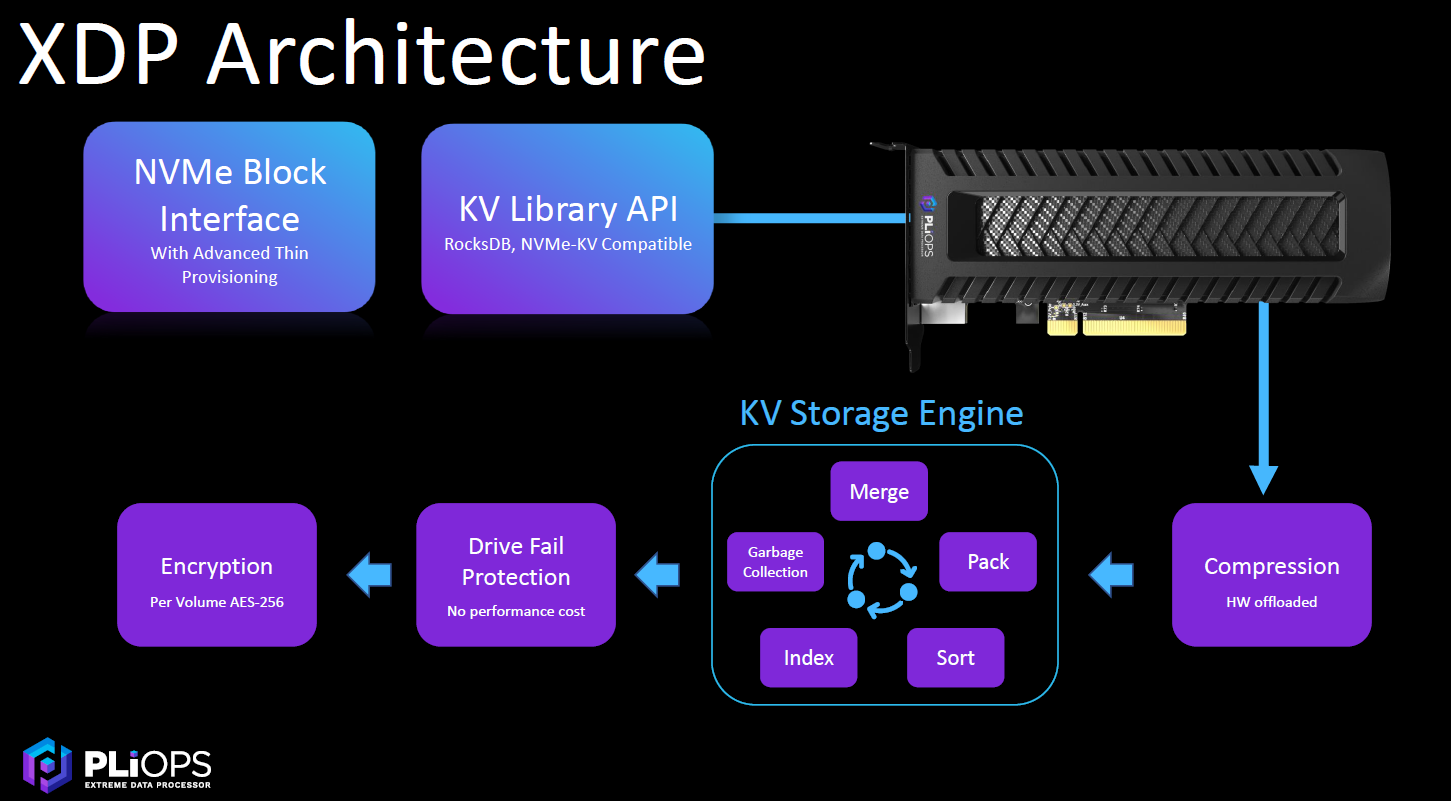
The Storage Engine is a RocksDB-based feature that can handle such relational databases as MySQL, Oracle and MariaDB, NoSQL databases like Redis, MongoDB and Apache HBase, analytics workloads like Spark, Hadoop and Splunk, and software-defined storage offerings like Nutanix and Ceph.
Fingerhut says the XDP shouldn’t be confused with DPUs.
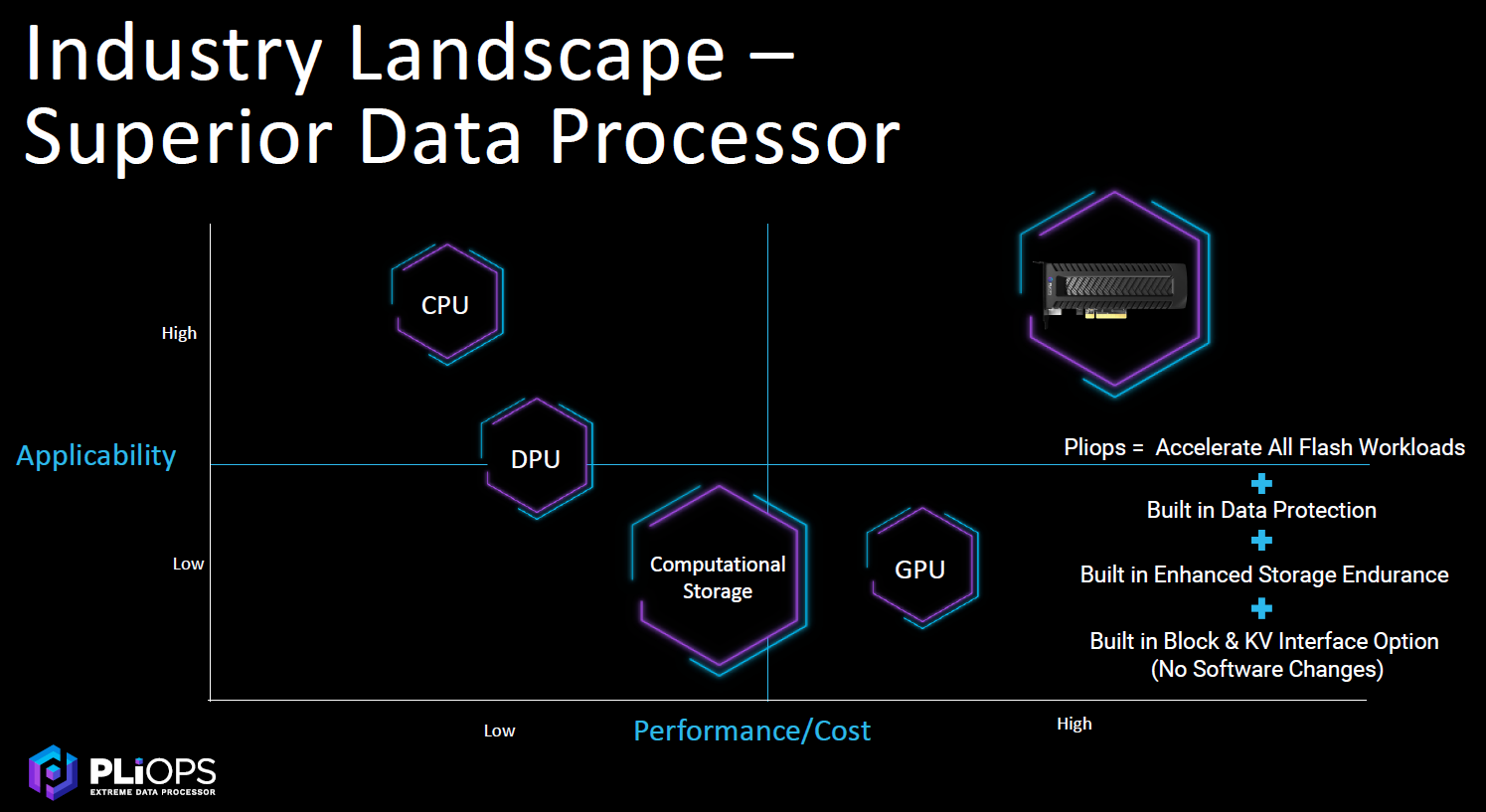
“DPUs as we see it are focused on the offload and isolation for security and there is a performance gain and for the replication management,” he says. “We really focus on that last mile. You want to go from your processor – whether it’s the CPU or the DPU – to storage. That’s where all that hard work has to be done. If you just move from CPU to the DPU, you free up your CPU cores, but it hasn’t really become more efficient. You’re still going to get that same read, write and space [amplification], just now you’re not using x86 cores, you’re using your DPU cores. … All you’re doing is really moving it there and what we’re focused on is that architectural innovation. We basically treat whichever one it is as our host. The DPU, that’s our host. We take our I/Os from it. If it’s the CPU, we treat it. The flexibility there is a benefit.”
Pliops sees a potential total market for its technology standing at $10.2 billion, ranging from $55 billion in AI and machine learning workloads to $95.9 billion in operational and transactional databases, with the XDP playing a complementary but distinct role from CPUs, GPUs and DPUs.
“Those have important values, but from a performance perspective and applicability perspective, Pliops is superior,” he says. “We accelerate all flash workloads, build in data protection [and] extend the life of flash, which is a big challenge, especially when a large datacenter’s buying a lot of flash; how to manage end of life? Then no software change is required. So it really does support this universal acceleration.”
Pliops is coming off a $65 million funding round in February that included Intel, Nvidia and Softbank (which owns Arm, at least until Nvidia grabs it for $40 billion). The company said the plan was to expand the reach of the XDP into new use cases and double the size of the company by the end of the year.


Computational Storage Winds Its Way Towards The Mainstream
Enterprises are said to be awash in data, and one of the problems posed by all this data is not just storing it, but processing it. Storage architectures have by and large been keeping up with the capacity problem, while the introduction of flash has also given storage a much-needed …
So how exactly is this different from a hardware offload VDO (virtual data optimizer, now part of Redhat)?
Not the least bit of technical detail, even in the white paper.
The KV sounds much like FusionIO’s “native API”.
So I guess they are using a big chunk of MRAM or similar to commit writes while they are doing VDO?