
Any on premises HPC cluster has its own limits of scale and throughput. While end users always want to run their simulations and models faster, there are often practical limits to the scale of any particular code, and even if there are not, there are economic ones. No one can have a cluster sized for some big jobs but idle most of the time.
This is why the promise of HPC in the cloud has been dangling in front of cluster managers and researchers for so long it seems like it has been available for decades. But it is only now, with the advent of containerized applications, sophisticated scheduling tools for systems software and the hardware underneath it, and the availability of large amounts of capacity that finally allows companies to put the idea of bursting some simulation and modeling workloads to the public cloud.
Disk drive and flash storage maker Western Digital has been putting cloud bursting to the test as it designs its next generation of products, and enlisted the support of Amazon Web Services, the juggernaut in cloud infrastructure, and Univa, which makes some of the most popular cluster scheduling software in the HPC space – that would be Grid Engine – as well as Docker container management tools based on Kubernetes that interfaces with it. Western Digital didn’t just dabble with cloud bursting when it went to test the idea; the company fired up 1 million cores that ran 2.5 million tasks on over 40,000 spot instances on AWS to run its verification tests, which took eight hours to run rather than the 20 days it would have taken to dispatch this work on the internal cluster residing one of Western Digital’s datacenters.
To get some insight into how this massive experimental run was done, we talked to Rob Lalonde, vice president and general manager of the cloud division at Univa, which did the hard work of configuring the massive virtual cluster on the AWS cloud and dispatching work to it.
The exact workloads that Western Digital ran are supersecret and so is the configuration of the internal cluster at the company that the cloud run was benchmarked against – this is the nature of competitive advantage and intellectual property at modern corporations. We do know that Western Digital uses Grid Engine as its job scheduler for its in-house cluster, so choosing Univa to help with a big cloud deployment was logical.
Very generally, the simulations done by Western Digital involve looking at the effects on disk drive performance by changing different materials in the disk platters, the energy levels and design of the read/write heads that fly above the platters, and the rotational speed of the platters themselves to get a desired mix of capacity and read and write times across the area of the platter. The normal product design cycle at Western Digital is about six months, and two years ago it started to experiment with bursting some product verification tests to the cloud to try to speed up the overall product design cycle.
The company, according to AWS, started out with 8,000 virtual CPUs running on the EC2 service, and kept doubling up the cluster sizes to 16,000 and then 32,000 vCPUs as it ran its experiments. Late last year, Western Digital decided to push further up to 40,000 instances with over 1 million vCPUs. The test ran on C3, C4, M4, R3, R4 and M5 instance types on the EC2 service at AWS, which were scattered across different availability zones but within one AWS region (US East in Virginia) to keep the latencies between nodes down to a bare minimum.
One of the big challenges, says Lalonde, was running the Western Digital verification tests on spot instances. These are the cheapest compute resource that AWS has available, but spot instances present very interesting challenges that HPC cluster managers and end users usually don’t have to worry about. The combination of Navops, the management stack for Kubernetes and Docker containers wrapping around applications, and Grid Engine, the job scheduler that actually provisions compute capacity and puts jobs on it, did not work out of the box on such a massive job, and it certainly was not created to cope with ephemeral capacity.
According to Lalonde, Grid Engine could provision 500 new AWS instances per minute so work could be dispatched on them, which is easy enough on reserved or on demand instances, but with spot instances, depending on what everyone else is doing on the AWS cloud, somewhere between 10 and 25 spot instances per minute are turned off to meet demand for reserved and on demand instances that have priority over spot. Grid Engine had to save the state of these spot instances before they vanished, and because time is money, it also had to be tweaked so that work would be dispatched to the virtual cluster on AWS as soon as instances were open. Grid Engine checkpointed all instances every 15 minutes and restarted from the checkpoint when a spot instance was grabbed back by AWS. Moreover, given that it took 1 hour and 32 minutes to get the 40,000 EC2 instances up and running, and that time costs money, so Grid Engine and Navops needed to be tweaked to so work was dispatched to configured instances as soon as they were up rather than waiting for the whole cluster to come up at once, as you would do in an on premise datacenter.
To deal with these issues, Univa created an extension of Navops to do remote procedure calls called Fantasia, after the Disney movie where a young sorcerer Mickey Mouse tries to automagically orchestrate the house to clean itself and hijinx ensue. This is in the process of being productized, but if you want to scale to 100,000 vCPUs or more on AWS, Univa knows how to do it thanks to the Western Digital run.
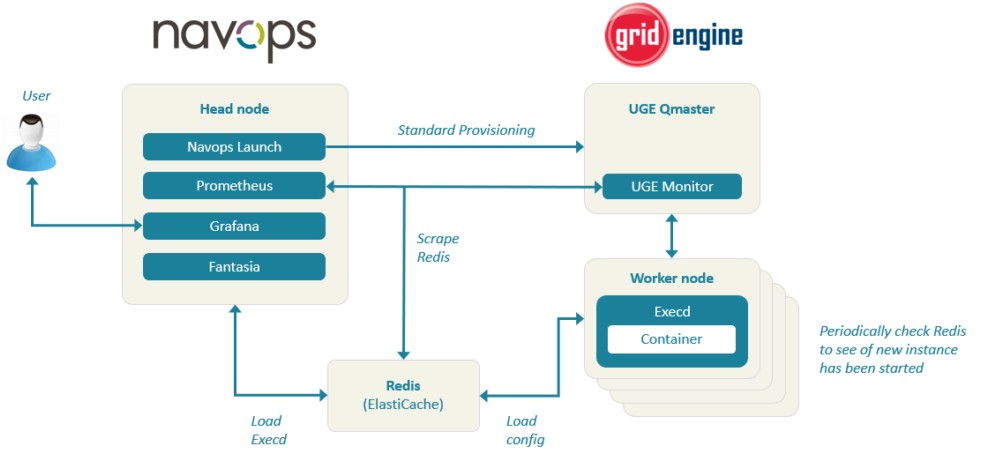
As you can see, the Navops stack includes Navops Launch, which Univa unveiled back in late 2015 as its entry into the Kubernetes orchestration arena. The Navops stack now includes the Prometheus monitoring tool, which Google has backed as the companion to Kubernetes, which is integrated with the Grid Engine Monitor; similarly, Navops Launch is integrated with the Grid Engine QMaster daemon. By linking these two, Grid Engine can spin up virtual resources on the AWS cloud and Navops can drop containerized applications on those resources and start them running. Navops includes Grafana for graphically presenting performance and monitoring data.
Just for perspective, scaling an HPC application over 1 million vCPUs – and below is the management screen to show the peak resources under management – is the kind of thing that used to be done only by the largest national labs:
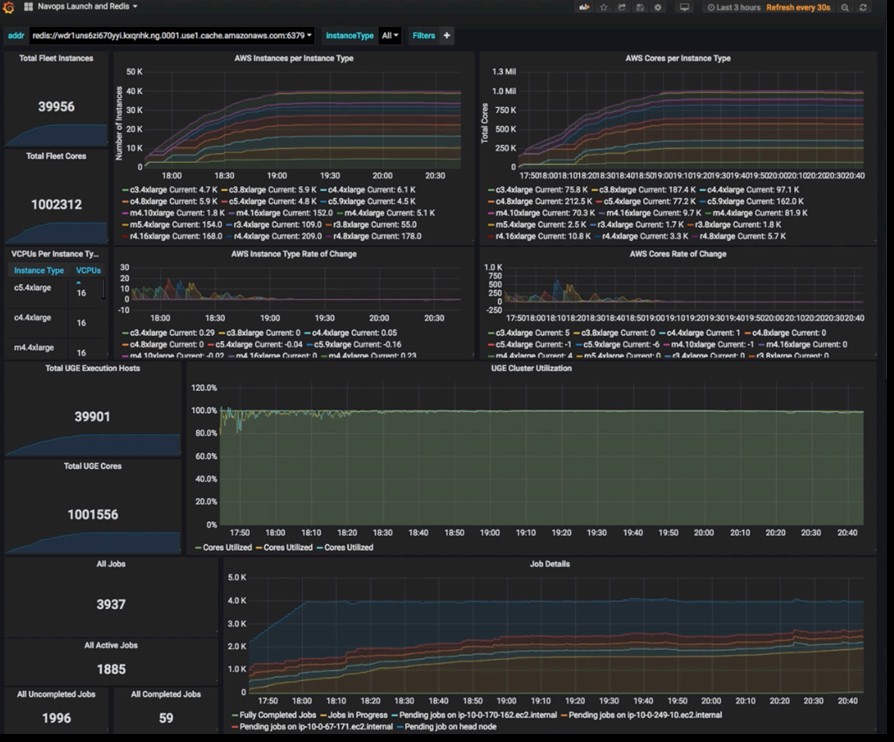
Lalonde offers some observations about running at such scale, and as you might expect, in a complex system like this, Amdahl’s Law comes into play all over the place. Before even going down the road on this large simulation, Univa, Western Digital, and AWS all knew that a Docker container registry, whether it was embedded on the Elastic Container Registry (ECR) service on AWS, the commercial Docker Hub, or a privately hosted Docker registry on AWS, was going to be a bottleneck. So Western Digital baked the applications and their Docker containers into a set of Amazon Machine Images (AMIs) and cached them on S3 so they could just be pulled and run rather than configuring the containers on the fly.
Checking the status on the running instances, Univa learned, was also going to be an issue at this scale, and this had to be done a lot given the spot nature of the instances used. So rather than use the normal AWS APIs to check the instance status, Univa set up an ElastiCache for Redis in-memory store, which is a managed version of the open source Redis key-value store. So as Grid Engine fired up new instances, their basic data – instance type, IP address, vCPU count, memory, and other salient characteristics – and Navops Launch pinged this Redis store instead of the AWS APIs to find resources on which to place the containers running the Western Digital applications.
Moreover, Lalonde says that the domain name server (DNS) service on AWS are fine for a certain scale, but at 40,000 instances all hooked together into a cluster, it starts to hit a ceiling. So Univa baked its own DNS server into the Navops stack and use static IP addresses for reverse IP lookups (which you normally would not do for infrastructure that is going to be around for a long time) wherever it could to avoid hitting the DNS at all.
For storage, rather than using any local disk or flash on the instances, or Elastic Block Storage, Univa just dumped all of the data into the S3 object storage. “If you have 40,000 instances and 2.5 million tasks, and they are all trying to hit data, and we were not too sure when we started how we would manage this,” Lalonde concedes. “But the data accesses were mostly embarrassingly parallel, so we put it all pout onto S3, and with some minimal tuning, we were able to get really fast data rates, peaking out at 7,500 PUTs per second and S3 was not really a bottleneck for us on the compute.”
Add it all up, and the Navops and Grid Engine hybrid software stack was able to keep the instances running workloads at 99 percent of their capacity, which is crazy impressive considering the ephemeral nature of some of those spot instances.
The workload being run by Western Digital to simulate read/write head performance took about 2 hours to run with about 20 minutes to wind down and aggregate and visualize data. Not all of the instances running different permutations of materials and head and platter design started at the same time, so naturally there was a kind of squared off bell curve of the instances over time to the aggregate runs. It looked like this:
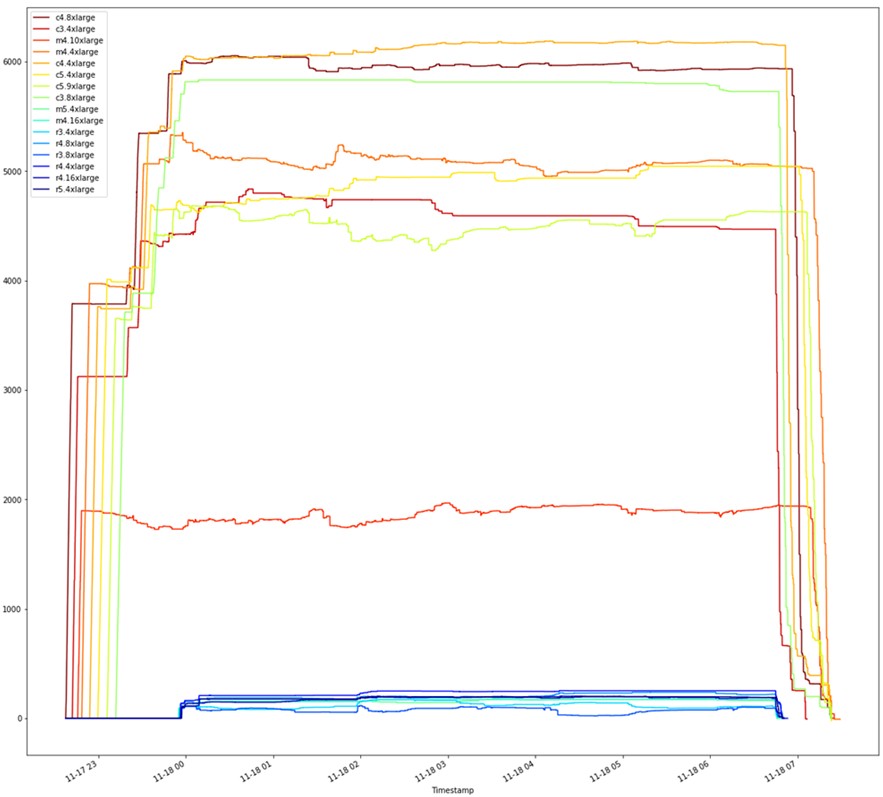
The total Western Digital simulation took eight hours to run, and it cost $137,307. Lalonde estimates that, based on what other customers have spent on bursting to the cloud, that using on demand instances rather than spot instances would cost anywhere from 4X to 6X more, so you can immediately see the value of that extra software that Univa cooked up to deal with the ephemeral nature of spot instances.
The other thing to observe is that the cost of that eight hour run across nearly 40,000 instances on AWS is enough money to build relatively small cluster. While cloud capacity can cost anywhere from 2X to 9X more to buy – yes, those are some very wide variables, but there are a lot of dependencies and contingencies – than on premises gear when you look at running everything full-bore over the three or four years that an HPC cluster is typically installed, there is something to be said for faster time to market on critical workloads.
The dream has been, for a long, long time, to be able to mix and match on premises and cloud capacity to do HPC work, and this shows it can be done. Finally. The trick will be to find the right mix of on demand and spot instances in the public clouds and the right mix of on premises and cloudy capacity. Those balances will only come through experience.


AWS Pushes Bang For The Buck With Graviton 4 Instances
UPDATED: Mea culpa. Due to an error in calculating the performance of the Graviton 4, we wrongly asserted that the price/performance of these chips was worse than, not better than, that of the Graviton 3. Below is a corrected story and set of data. The decades of Moore’s Law …

Sizing Up AWS “Blackwell” GPU Systems Against Prior GPUs And Trainiums
This week, Amazon Web Services announced the availability of its first UltraServer pre-configured supercomputers based on Nvidia’s “Grace” CG100 CPUs and its “Blackwell” B200 GPUs in what is called a GB200 NVL72 shared GPU memory configuration. These machines are known as the U-P6e instances, and come in full rack and …
With Project Beacon, Nutanix Opens Up And Reins In Cloud Infrastructure
Here is a question for you. Which is more proprietary? The Nutanix hyperconverged compute, storage, and networking platform or a cloud like Amazon Web Services or Microsoft Azure? It was a trick question. They are all proprietary, but oddly enough if you mix them together, you can get something that …
Unfortunately there are many errors in this article.
“super secret” not really. The theory behind the simulation was published here: https://iopscience.iop.org/article/10.1088/1367-2630/17/10/103014 based on code written and sold to Seagate 16 years ago, rewritten from scratch for Hitachi GST and then acquired by WD. The general purpose was to find the areal density limit for heat assisted magnetic recording. Unfortunately, i don’t know the result since i left before the final run and the post-processing script (which would have calculated the final areal density) wasn’t run due to some errors when Univa tried to incorporate it into the workflow.
AWS Batch is currently limited to 5000 instances in one availability zone so even using large instance types, the limit was ~360k concurrent runs (100k was the sweet spot). Univa had no such limitation. If i recall, Amazon suggested the 1million core run. While the scale was achieved, it wasn’t run in an optimized compute/$ metric since there was only a handful of instance types that provided the optimal point (as determined by extensive testing). In fact, because non-optimal instances were used, three executables had to be baked in to support different classes of processors (mostly AVX, AVX2 or AVX512 support) and the appropriate executable was chosen at runtime. This was also done for AWS Batch to avoid availability issues with spot instances.
Simulations are single threaded and required no communication between nodes, so i don’t know where this latency comes in- has nothing to do w/ the simulation itself- there is no OpenMP or MPI. The post-processing (using Octave) was compiled with OpenMP, but as stated, it was not included in this run.
What was notable other than scale, i believe, was that all input/output used S3. To avoid overloading any node on S3, it was required to disperse the objects on S3 and this was done by prepending a hash value to the object names and compressing any files (zstd was chosen for speed and resulting compression of binary files). S3 never exhibited any problems. This was done on the typical workflow w/ AWS Batch and Univa simply used the same glue. In fact, from the simulation point of view only a few things changed between AWS Batch and Univa, namely ‘aws batch …’ -> ‘qsub ….’ and swapping out AWS_BATCH_* environmental variables w/ corresponding SGE_* variables. So, it should not be surprising that the same thing is achievable on Azure (never tried GoogleCloud, but…) which a POC showed 150k concurrent simulations using only Azure provided tools.
Checkpointing (to restart if a spot instance was lost) had nothing to do w/ Univa. It was baked into the simulation/run scripts. The same support for checkpointing worked under AWS Batch (or Azure Batch)- did have to change the exit code so Univa GE would retry failed runs (required ’99’ instead of non-zero). Here, also, the compressed checkpoint files were pushed to S3 as the run progressed and deleted on successful completion.
While i applaud Univa for being able to spin up this number of instances this quickly, the workflow was already available and required trivial changes to support Univa Grid Engine. I was actually pleasantly pleased (not surprised) it held together. So, if you have a workflow that can scale past the internal limits of AWS (or Azure), clearly Univa can help. If you desire such a workflow for scale, i’ve demonstrated it can be done easily and can help you achieve it also: https://entonos.com.
Finally, Amdahl’s Law does not apply here. These simulations are single threaded and so are embarrassingly simple parallel- there is perfect scaling. It does come in due to the infrastructure of AWS (and, perhaps, Univa’s stack), but not from the simulations themselves. Saying this is HPC is somewhat misleading, it’s really HTC (high throughput computing).