

There may not be a lot of new systems on the November 2020 edition of the Top500 rankings of supercomputers, but there has been a bunch of upgrades and system tunings of machines that have been recently added, expanding their performance, as well as a handful of new machines that are interesting in their own right. But even with that, all eyes are poised on the push into exascale that will begin in earnest this time next year and that will, for the most part, demonstrate the many faceted nature of hybrid computing in HPC and AI.
Before we get into all that, let’s run through the changes in the list and the rankings among the ten systems.
The “Fugaku” system at RIKEN lab in Japan remains the most powerful supercomputer on the list, a position it took in the June 2020 list, and its performance lead extended a bit as more nodes were added to the all-CPU system based on Fujitsu’s A64FX processor. The A64FX is what happens when an Arm server CPU has a lovechild with a wide vector math unit on each core, and it represents a very good balance in architectures and a continuation of the work that RIKEN and Fujitsu have been doing since the K supercomputer a decade ago. As was the case with the K machine, we expect that, thanks in part to the third generation Torus Fusion, or Tofu D, 6D mesh/torus interconnect, that Fugaku will be a very long-lived and energy efficient machine for real-world workloads. Just like K was, even though it was not the top of the raw flops rankings for many years.
For the November rankings, RIKEN added another 331,766 cores to the Fugaku machine and it also tuned up the software stack on the system. And in fact, we think a little less than a third of the performance increase on the Fugaku machine came from software tweaks and two thirds came from the additional hardware, which pushed the system up from 415.4 petaflops to 442 petaflops on the High Performance Linpack (HPL) matrix math test used to rank supercomputers on the Top500. The increase in performance on HPL was in fact larger than the increase in raw performance, with the upgraded Fukagu machine having 23.35 petaflops more peak but yielding 26.48 petaflops of actual performance on Linpack. The computational efficiency of Fugaku – HPL performance divided by peak performance – actually rose by 1.4 percent thanks to the tuning, to 82.3 percent. That’s not bad for a machine that has a concurrency of just under 7.3 million cores. But it is still far below the very high bar of 93 percent computational efficiency on Linpack that the K machine set with supposedly more primitive technology.
The hybrid “Summit” pre-exascale system at Oak Ridge National Laboratory, which was installed completely in 2018, remains number two on the list at 148.6 petaflops and has a computational efficiency of 74 percent, and its companion “Sierra” system at Lawrence Livermore National Laboratory, which has a slightly different balance of IBM Power9 CPUs and Nvidia V100 GPU accelerators, comes in at 94.6 petaflops on Linpack and a computational efficiency of 75.3 percent. The Sunway TaihuLight massively parallel system based on the custom SW26010 processor and launched more than four years ago at the National Supercomputing Center in Wuxi, is still the fourth most powerful system in the world. This is noteworthy considering how aggressive China was to stay at the top of the rankings back then. China has not really put a pre-exascale system in the field.
The number five system on the list, the “Selene” parallel DGX A100 supercomputer that is comprised of 64-core AMD Epyc processors paired with Nvidia’s own “Ampere” A100 GPU accelerators and that is used by Nvidia itself for its own HPC and AI research and development, moves up two notches in the Top500 rankings thanks to an upgrade that nearly doubled its performance, from 34.6 petaflops peak to 79.2 petaflops peak. This updated Selene has 555,520 units of compute – that’s cores on the CPUs added to SXM streaming processors on the GPUs (not CUDA cores, which are not analogous to cores on the CPU to the way of thinking of the organizers of the Top500 list) – and delivers 63.5 petaflops of oomph on the Linpack test, for a computational efficiency of 80.1 percent. It obviously uses 200 Gb/sec InfiniBand interconnect from Nvidia.
The Tianhe-2A machine at National Supercomputer Center in Guangzho is the second most powerful system in China and ranked sixth on the November 2020 Top500 list. This is an upgrade to the original Tianhe-2 machine installed in 2013 and the most powerful supercomputer in the world for two and a half years. The original machine was a based on a mix of Intel Xeon CPUs and Xeon Phi accelerators, with nodes linked by a variant of InfiniBand from Mellanox, and the upgraded Tianha-2A machine that came out in the summer of 2015 was based on Intel Xeon processors and a custom accelerator called the Matrix-2000 based on digital signal processor (DSP) engines instead of GPU cores.
The other new machine in the top ten is the JUWELS Booster Module, an Atos Bull Sequana system that extends the system of that nickname – short for Julich Wizard for European Leadership Science – that debuted more than two years ago and that was originally based on Intel’s “Skylake” Xeon SP processors and 100 Gb/sec InfiniBand interconnect from Mellanox (now part of Nvidia). The JUWELS Booster Module installed at Forschungszentrum Juelich (FZJ) in Germany is based on 24-core AMD Epyc 7402 processors and Nvidia A100 GPU accelerators and has a peak theoretical performance of 71 petaflops and delivers 44.1 petaflops on Linpack, for a computational efficiency of only 62.2 percent. There is obviously some headroom in that system for performance tweaks, and we expect to see them in the coming months.
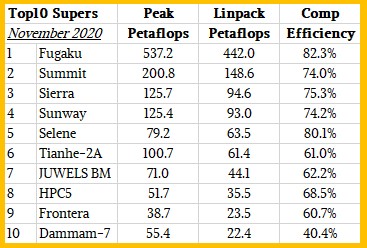
The HPC5 system at oil and gas giant Eni in Italy, at 35.5 petaflops, the “Frontera” system at the Texas Advanced Computing Center, at 23.5 petaflops, are ranking number eight and number nine, respectively and we have detailed them in the past under the links above. HPC5 is a mix of Intel Xeon SP Gold CPUs and Nvidia V100 CPUs with nodes linked by 100 Gb/sec InfiniBand, and Frontera is an all-CPU machine based on Xeon SP Platinum CPU nodes linked by 100 Gb/sec InfiniBand.
Rounding out the top ten is the “Damman-7” system at Saudi Aramco, the Saudi Arabian oil and gas giant, which is a Cray CS Storm system from Hewlett Packard Enterprise that has a mix of Intel Xeon SP-6248 Gold processors and Nvidia V100 GPU accelerators that delivered 22.4 petaflops. This machine had a computational efficiency of only 40.4 percent, which is pretty low for an InfiniBand cluster, even a hybrid one mixing CPUs and GPUs. Saudi Aramco has just installed another Cray CS Storm machine, called “Unizah-II,” rated at 3.5 petaflops that is just based on those Xeon SP processors – no Nvidia GPU accelerators – and using only 10 Gb/sec Ethernet interconnect; this machine had a computational efficiency of just under 51 percent, which is also low. The point is this: There seems to be latent capacity in these machines, and even with inefficiencies, Saudi Aramco is able to get at the top of the list.
Over the next two years, the top ten will be almost completely rewritten, and it is likely that Fugaku and Summit will stay on the top ten, but there is a very good chance that Sierra and Sunway will not. You can bet Jensen Huang’s last dollar – and there will be no such thing – that Nvidia will keep a machine in the top ten from here on out, no matter what. It is not just a matter of pride, but a matter of expanding what Nvidia does in AI and sometimes in HPC. Selene is a tool that demonstrates AI scale and is used to drive AI innovation, and is not just a publicity stunt.
To get on the Top500 list this time around, a machine had to have at least 1.32 petaflops, up 7.3 percent from 1.23 petaflops only six months ago. If we eliminated the substantial number of machines installed in hyperscaler and service provider datacenters that ran Linpack as a political stunt – and this is definitely a stunt since these machines do not do 64-bit precision HPC or AI as part of their day job – and only included machines that did HPC and AI for real, that entry point would obviously be a lot lower. How much lower we cannot say. Ditto for the aggregate performance of the list, which was 2.43 exaflops this time around, up 9.5 percent from 2.22 exaflops in the June 2020 list. (We have complained about this gaming of the Top500 for years – see here and there for just two examples – and we are not in the mood to do it again. The list is still useful, even if it is not perfectly reflective of the actual HPC and AI distributed systems arenas.)
The important thing we are concerned about is that despite these two new systems in the top ten and the upgrades, the churn in the list was the smallest that its organizers have seen since the list was established since they started this project 27 years ago. This is probably just a matter of the HPC market coiling to spring for the jump to exascale-class technologies and the economic uncertainty due to the coronavirus pandemic. We suspect that things will pick up after Nvidia, Intel, and AMD get their new CPUs and GPUs in the field. There is a lot of digestion – and in the case of the once and future “Aurora” A21 supercomputer at Argonne National Laboratory, whose motors have been delayed again, indigestion – going on.
There is a lot to digest.
For one thing, there is the use of mixed precision inherent in GPUs and now CPUs rather than just running in 64-bit floating point for simulation. AI training is still largely done with 32-bit math, although there is a bit of 16-bit data and math with 32-bit accumulation starting with Nvidia’s Tensor Core matrix units. Others are developing similar techniques for CPUs (IBM’s Power10 has tensor-like vector engines, for instance) and GPUs. People often talk about the mixing of AI and HPC within a workload or across workloads, but this is different. This is retrofitting HPC solvers so they can take advantage of mixed precision and tensor units so they get to the same answer if they can make the linear algebra solver converge on the answer.
We talked to Jack Dongarra, professor of computer science at the University of Tennessee, the creator of the Linpack linear algebra benchmark, and one of the originators of the Top500 list, about this back in June 2019 when he rolled out the HPL-AI adjunct to the HPL test. The iterative refinement solver allowed the Summit supercomputer, rated at 148.8 petaflops on the real HPL test in 64-bit floating point precision to do the work 2.9X faster using a FP16, FP32, and FP64 math, making it feel like it was a 445 petaflops 64-bit machine. With the Fukagu supercomputer at RIKEN, using this iterative solver method in mixed precision, the slightly smaller system in June was able to behave like it was a 1.4 exaflops 64-bit machine as far as HPL goes, and with the increased core count here in the fall of 2020 and tweaks to the iterative solver used in the HPL-AI test, Fugaku did the work of a hypothetical 2 exaflops machine running in 64-bit mode, which is a factor of 4.5X boost.
This is stunning. And important. And as much HPC code as possible needs to be written this way, for obvious reasons.
It is not clear how these iterative solvers can be embedded in all kinds of HPC applications. Our initial reaction to calling a machine with mixed precision exascale because it does exaops was as you might expect. A frown and a raised eyebrow: That’s cheating, and that’s not what we meant by exascale, and you all know that. Fugaku was particularly annoying to us initially in this regard because we expected an actual exascale – meaning as expressed in 64-bit floating point – machine. And we were tempted to take a hard line and say we would only count 64-bit floating point processing as the finish line crossing into exascale. But, the reality is this: We can’t afford such purity. And we need to cheat everywhere and everywhen we can to keep the performance growing, and if that means using iterative solvers to get something that does the work of a 1 exaflops machine at 64-bit precision but only needs 350 petaflops or 250 petaflops, so be it. So if it looks like an exascale duck, and it quacks like an exascale duck when it is using an iterative solver, then maybe it has to be perceived as an exascale duck.
And then there is the idea that HPC and AI will work together to try to actually mix simulation and modeling with data analytics, machine learning training, and machine learning inference to accelerate HPC applications. We have seen numerous examples of these over the past several years, including some of the Gordon Bell Prize winners in the past several years.
It is with this, and knowing the behemoth supercomputers on the horizon, in mind that the following chart is not depressing:
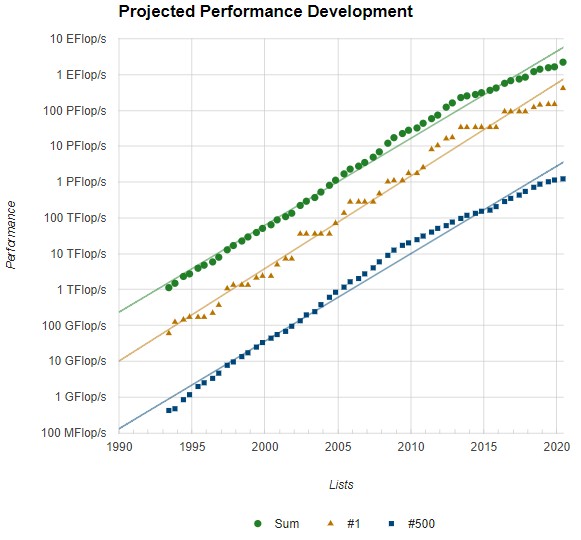
We have been under the expected exponential performance growth curve since 2015 thanks to the slowdown in Moore’s Law improvements in compute and networking and the end of Dennard scaling in 2000 or so. But, we were there in the early 1990s and we figured out a way to move to more loosely coupled systems, invented the Message Passing Interface (MPI) to parallelize workloads and developed OpenMP to parallelize across CPU core and now GPUs. We bent that curve up again and got more than back on track. And while somewhere between a 3X and 5X performance boost by shifting to mixed precision solvers only gives us a step function of that size increase, that coupled with a lot more iron could make real world applications run a lot faster than we might be planning, thus improving their price/performance and making HPC better pay for itself. We have no question that AI will pay for itself, and in fact, the use of AI by all kinds of organizations may help drive HPC adoption because the hardware will be out there.
It certainly looks like accelerator engines are becoming more normal, at least according to the Top500 rankings. Here is the distribution of machines with accelerators of some kind over time since 2006, when ClearSpeed floating point accelerators were added to Sun Microsystems supercomputers:
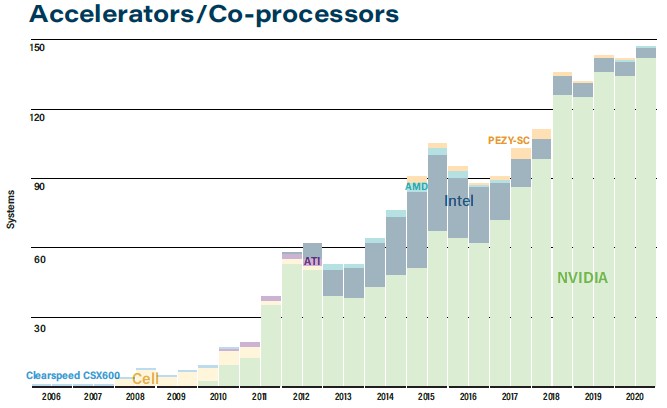
This time around, 146 systems on the list use some sort of accelerator or coprocessor, and of these, 136 machines use Nvidia GPU accelerators of various types and vintages. AMD is bringing better and better GPU accelerators to the HPC space, and Intel will be entering the fray, providing feature and price competition. Future exascale systems in the United States are using AMD CPUs and GPUs – that would be the 1.5 exaflops “Frontier” supercomputer coming next year at Oak Ridge and the 2 exaflops-plus “El Capitan” machine at Lawrence Livermore coming in 2022 – and at some point Argonne will get its 1 exaflops-plus A21 machine based on Xeon CPUs and Xe GPUs from Intel. (Neither IBM nor Nvidia got any piece of that action, and we think it came down to price, plain and simple.)
Here is the larger point: Somewhere north of 90 percent of the aggregate computing in most capability-class hybrid CPU-GPU systems comes from the GPUs. And this ratio has been creeping up over time and we think it will find a natural balance point at around 95 percent. We realize that machines like Fukagu are the exception, where the math is on the CPU itself, but Fugaku is a lot more expensive per unit of compute, too. And this will matter. Not only will we need accelerators to bend the performance up, but we will need iterative solvers to get HPC back on track and keep it there for a while – especially when Moore’s Law improvements actually stop somewhere between 2025 and 2030.
After that, it’s anybody’s guess.


At Long Last, HPC Officially Breaks The Exascale Barrier
Significant business and architectural changes can happen with 10X improvements, but the real milestones upon which we measure progress in computer science, whether it is for compute, storage, or networking, come at the 1,000X transitions. It has been nearly two decades since the “Roadrunner” hybrid Opteron-Cell was fired up at …

Injecting Machine Learning And Bayesian Optimization Into HPC
No matter what kind of traditional HPC simulation and modeling system you have, no matter what kind of fancy new machine learning AI system you have, IBM has an appliance that it wants to sell you to help make these systems work better – and work better together if you …

One Way To Bring DPU Acceleration To Supercomputing
That is not a typo in the title. We did not mean to say GPU in title above, or even make a joke that in hybrid CPU_GPU systems, the CPU is more of a serial processing accelerator with a giant slow DDR4 cache for GPUs in hybrid supercomputers these days …
Be the first to comment