

One of the great things about the database market is that there are many different kinds of data and the problems that need to be addressed to store, organize, and query that data are also increasing with the speed and amount of data stored. It is an IT organization’s nightmare and a software engineer’s dream, and hence the proliferation of database management systems of all types.
As is usually the case, a particular technology is developed to tackle a specific set of issues – relational, object, document, spatial, graph – and the first generation of tools do a pretty good job and the technology gets a toehold. But there are usually issues of performance and scale in this first pass, and sometimes it takes a new approach to better adapt the software to whatever hardware is available in the datacenter. Sometimes, the hardware itself has to evolve – compute engines need more threads or memory bandwidth, storage devices need higher throughput or lower latency or more capacity, distributed nodes need high bandwidth and low latency interconnects to scale – before the software can be pushed further or meet the expectations of enterprise customers.
It is usually the second or sometimes the third generation that brings it all together, and then a technology can really take off. It is a fortunate company that can do all of these things in-house, but as many times as not, it takes innovators multiple passes at different companies before they can being all of their learnings to bear and create what they think is a product that can tick all the boxes in an RFP. So it is with vesoft, which was founded by Sherman Ye, who is the company’s chief executive officer and who is bringing the Nebula Graph database to market after building some of the largest graph databases in the world.
Ye has been coding since the dot-com boom back in the late 1990s, and among other things was a senior software engineer at Open Text, which sells various web application frameworks, and a team leader at LogLogic, which was acquired by TIBCO and which as the name suggests sells tools to manage log data to enhance IT security. In early 2011, Ye moved to Facebook, where he worked for four years on the social network’s graph database, which is a pretty important task given that Facebook is the world’s largest social media network. And four years later, based on Ye’s substantial experience, he was tapped by the Ant Financial payment processing arm of Chinese hyperscaler Alibaba to create its own internal graph database. In October 2018, Ye struck out on his own to found the open source Nebula Graph database project and to also found the vesoft company that would provide commercial-grade support for Nebula Graph to enterprises. Like Ant Financial, vesoft is located in the city of Hangzhou in the province of Zhejiang in China, which is a big tech center.
Ye participated in The Next Database Platform event here at The Next Platform a few months ago, and has just put Release Candidate 1 of the Nebula Graph v2.0.0 version of the database out the door, and we thought this would be a good time to talk about vesoft and how Nebula Graph is different from the competition, which among others includes Neo4j, TigerGraph, JanusGraph, and Dgraph.
The Nebula Graph project was kicked off in May 2019, and most of that year, says Ye, the company focused on creating the foundation for its distributed graph database. At the end of 2019, Ye started soliciting early customers in various Internet sectors to give it a spin, and the first full release of Nebula Graph debuted in June 2020.
“This were selective customers,” Ye tells The Next Platform. “We chose the leader in each Internet sector in China, and we did so because each of them is taking on the stronger, more traditional companies and they are willing to try a new technology to try to get ahead. They also have a lot of data and complicated business logic and business scenarios, so this is perfect for us to get trial time with them to improve our product.”
Starting in China was logical for vesoft in a number of ways. First, the big hyperscalers and cloud builders in China are not as old as Google, Amazon Web Services, Facebook, and Microsoft, and these companies are not just older but they have been bigger longer and in some cases they needed various kinds of database technologies to change before any commercial entity could provide it. That was not so with Alibaba until recently and is still not so with Baidu, Tencent, and a slew of other service providers in China. To be sure, some of these big companies in China have created their own NoSQL and relational databases and they have been on the forefront of new technologies such as machine learning. Alibaba has its own iGraph variant of the Gremlin graph query language, more of an overlay than a database, and its Ant Financial division created GeaBase for risk analysis for financial applications, which Ye helped create. Aside from these, as far as Ye knows, none of the other Chinese hyperscalers had as yet tackled graph databases, which in many ways are more useful if you can get them to scale.
That scale is particularly important in China, which has 1.4 billion people compared to 1.37 billion in India, 446 million in the European Union, and 328 million in the United States. Given the population differences between the United States and China, it is also safe to say that the hyperscalers in the Middle Kingdom will ultimately have more customers and be considerably larger. So getting in now with graph database technologies could be a very profitable proposition for an indigenous Chinese open source project and the commercial entity that is supporting that project.
The good news is that anyone in the world can use Nebula Graph. It remains to be seen how easily vesoft will be able expand beyond China, but that market is plenty big enough to keep Ye and his team busy for many years to come. Unlike relational databases and their SQL query language, which has been around for more than four decades and therefore there are lots of people who understand them inside and out, graph databases have only been around for a decade or so and have really only started taking off in the past three years or so as people get their brains wrapped around their ideas and run up against problems that are, in fact, best solved through graph techniques.
Ye cut his teeth on graph databases at Facebook helping to create the Dragon distributed graph query engine, which Facebook talked a bit about in March 2016, and this is a much more complex project that the relatively simple The Associations and Objects server, a massive single-hop query engine that keeps all of the messages, likes, comments, and shares that users create current across the social network.
Ye says that he took the architectural learnings he had with Dragon and applied those, as well as some new approaches, when he moved to Ant Financial, working on the Graph Exploration and Analytics, or GeaBase, graph database mentioned above. Back October 2018 was presented at the USENIX Symposium on Operating Systems Design and Implementation conference and at the time was said to scale to 10 billion nodes (vertices) and 100 billion edges. It is now said to scale to trillions of nodes and trillions of edges.
The nodes represent entities in the graphs and the edges represent relationships between the entities, and as we have said before, the powerful thing about a distributed graph database that is working properly – meaning it can scale across more than one node without serious performance degradation or data consistency issues – is that, unlike a relational database, a graph database has all of its joined done by default. You just walk the database to pull out the required relationships without having to consolidate data to a big wonking table and then query it. Here is a very interesting graph that illustrates the point, showing the relationships between the companies funded by Alibaba founder Jack Ma:
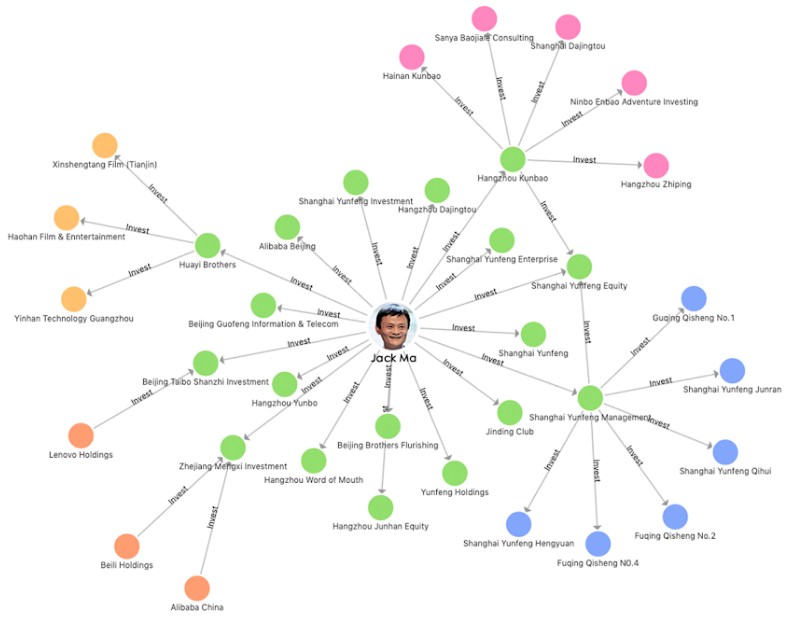
Ant Financial uses GeaBase to do risk analysis, including sifting through transactions for fraud, money laundering, and other risk analytics that have to be done at transaction speed across a very high volume of users.
“This experience I have had has been wonderful, and it is vesoft’s biggest advantage,” says Ye.
Another advantage that Nebula Graph has over some existing graph databases, like Neo4j, is that around 93 percent of its code its written in C++, not Java. Some of the utility programs that work with Nebula Graph are written in Go, the language created by Google to kind of mix and match some of the benefits of C and Java without taking on some of the performance issues. Other bits of it are done in Yacc, Thrift, Scala, and Lex. The code is under an Apache 2.0 license, but one that keeps the public clouds and hyperscalers honest through a Commons Clause 1.0 addendum that does not allow companies to grab the code, modify it, host it as a service, and not give code modifications back to the community. (This always seemed wrong to us. If you are making money or gaining influence or data that allows you to indirectly make money, then either give back or write your own code from scratch.)
There are two different kinds of graph databases, ones that are involved in transaction processing and ones that are involved in deep analytics, and Nebula Graph is more the former than the latter; TigerGraph, by contrast, was formed to do more of the latter, not the former. (Although these lines are sometimes hard to draw and they often blur over time. Every major relational database can do OLTP and OLAP.)
You might be thinking that a distributed graph database might need big fat servers with lots of network bandwidth, but it is not too bad. Ye says Nebula Graph runs fine on server clusters using 10 Gb/sec Ethernet interconnects, but in some cases, it will do better with 40 Gb/sec, 100 Gb/sec, or faster interconnects. The machines should, however, be equipped with lots of cores to increase throughput – 32 cores or 48 cores per server node works, but the more the better, says Ye. vesoft is supporting X86 and Arm architectures, and is excited to be deploying on the Graviton2 Arm server instances on AWS for customers who want to kick the tires on some of the cheapest infrastructure on the public clouds. Each node or cloud instance should have at least 128 GB of main memory, and again, the more the merrier. And here is one final thing to consider: Fat server nodes cost more, but Nebula Graph will perform better for a given number of cores on machines that are beefier, and that is because of the network latency. (We imagine that Nebula Graph might scream on a very fat NUMA server with 32 or 64 sockets and tens of terabytes of main memory, but that is not its design point.)
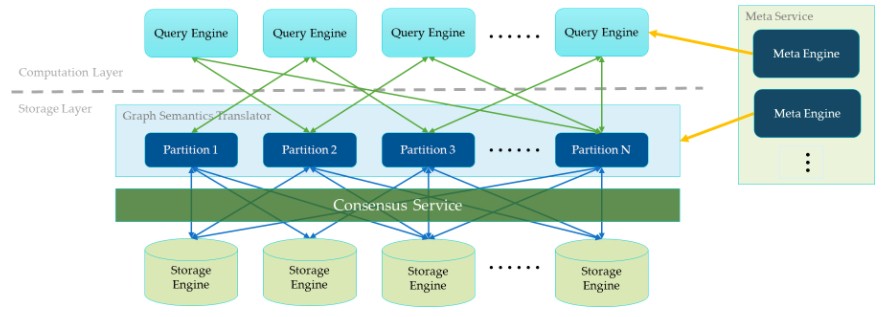
Scale is always matter on the nature of the data and the queries run against it, but generally speaking, Nebula Graph cab scale to billions of vertices (nodes) and trillions of edges. Early customers are teaching vesoft how to push the scalability limits and tune up performance.
Like other graph database makers, vesoft has its own variant of a graph query language, called nGQL, which is SQL-like with graph principles added to it. (There is not, as yet, a standard GQL as there is a standard SQL for relational databases, but the industry is inching closer and closer.) Nebula Graph Studio is also used for data importing and data visualization.
To get going, vesoft raised some money (an unspecified amount) from angel investor Matrix Partners China and when it dropped out of stealth mode in June 2020, the company said it had picked up $8 million in what it called “Series Pre-A funding,” which we never heard of before, with Redpoint China Ventures as the lead investor. In December 2020, vesoft picked up another 410 million in Series Pre-A funding, with Source Code Capital being the lead investor.
vesoft cites Gartner data that suggests that the relational database market is around $50 billion worldwide right now, and that graph databases are going to grow at a triple-digit rate in the next three years to comprise a $10 billion market. It is not yet clear how incremental – or creatively destructive – this will be for the relational database incumbents.


Be the first to comment