

Datacenters have evolved from physical servers, to virtualized systems, and now to composable infrastructure where resources such as storage and persistent memory are disaggregated from the server. At the same time, processing has evolved from running only on CPUs to accelerated computing running on GPUs, DPUs, or FPGAs to handle data processing and networking tasks. The software development model has likewise evolved from programs that run on a single computer to distributed code that runs on the entire datacenter, implemented as cloud-native, containerized microservices.
In this new world, developers need a programmable datacenter fabric to assemble the diverse processor types and resources to compose the exact cloud compute platform needed for the task at hand.
The first age of datacenters was CPU-centric and static, running one application on one computer. Software ran on the CPU and programmers developed code that ran on just one computer. Since resource assignment was static and changing servers could take weeks or months, servers were usually overprovisioned and underutilized.
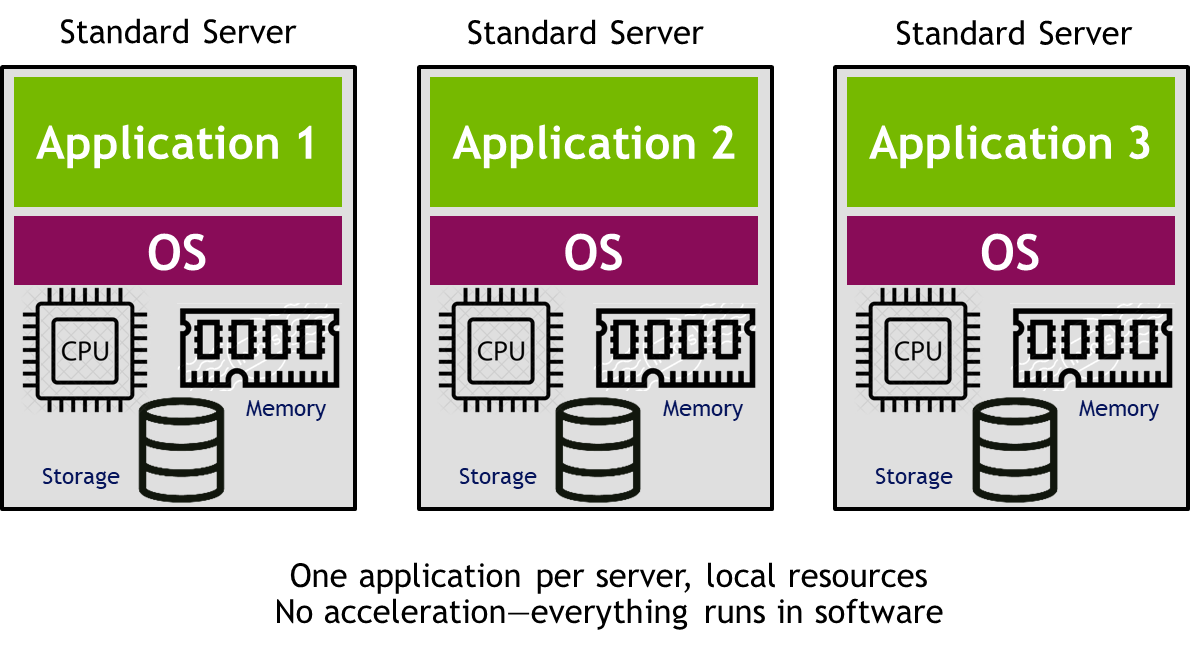
In the second age of datacenters, virtualization became the norm with many VMs running on each server. Resources are somewhat dynamic, with VMs created on demand. When more CPUs, memory, or storage are needed, a workload can be migrated to a VM on a different server.
Processing is still performed primarily by CPUs, with only the occasional GPUs or FPGAs involved to accelerate specific tasks. Nearly everything still runs in software and application developers still mostly program to only CPUs on one computer at a time. Datacenters of the second era are still CPU-centric and only occasionally accelerated.

The Datacenter Is The Computer
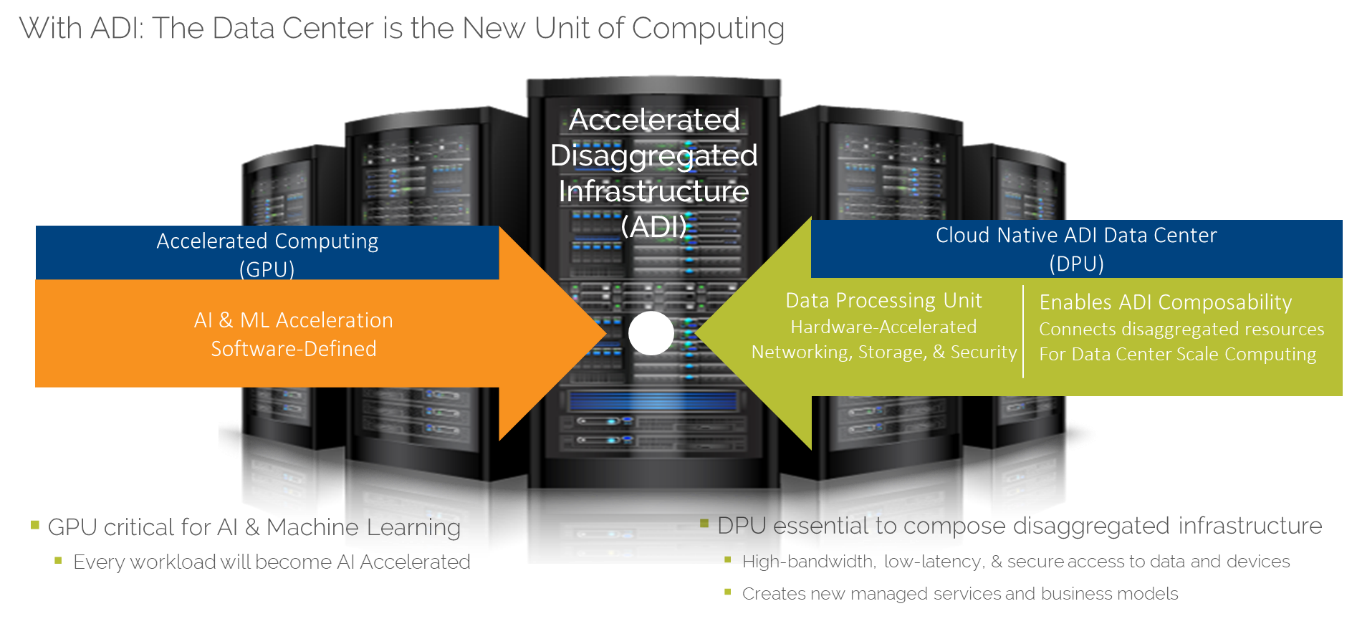
Today we are entering the third age of datacenters, which we call Accelerated Disaggregated Infrastructure, or ADI, built on composable infrastructure, microservices, and domain-specific processors.
Let’s talk about these important elements separately.
Accelerated: Different workloads are accelerated by different processors, according to whatever is optimal. CPUs run general purpose single-threaded workloads, GPUs run parallel processing workloads, and data processing units (DPUs) manage the processing and low-latency movement of data to keep the CPUs and GPUs fed efficiently with the data they need. For example, the CPUs might run databases, GPUs might handle artificial intelligence (AI) and video processing, while DPUs deliver the right data quickly, efficiently, and securely to where it’s needed.
GPU-accelerated AI and machine learning are now being used everywhere: to improve online shopping, 5G wireless, medical research, security, software development, video processing, and even datacenter operations. The rapid growth of cloud, containers, and compliance concerns requires DPUs to accelerate networking, storage access, and security.
Disaggregated: Compute, memory, storage, and other resources are separated into pools and allocated to servers and applications dynamically in just the right amounts. The applications themselves are typically built of interacting microservices instead of as one monolithic block of code. This makes it easier to compose an application with the correct ratio of resources and change that ratio as needed.
With the ADI model, GPUs, DPUs, and storage are available to connect to any server, application, or VM as needed. Use of technologies like Nvidia’s GPUDirect and Magnum IO allow CPUs and GPUs to access each other and storage across the network with nearly the same performance as if they were all on the same server. The right number and type of GPUs can be assigned to the workloads that need them. DPUs within each server manage and accelerate common network, storage, security, compression, and deep packet inspection tasks to keep data movement fast and secure without burdening the CPUs or GPUs.
To Program The Datacenter, You Must Program The Network
With the ADI, the datacenter is the new unit of computing, and the network fabric provides an agile, automated, programmatic framework to dynamically compose workload resources on the fly. This means programming not only the CPUs, GPUs, and DPUs, but the network fabric itself – extending the advantages of DevOps into the network, an approach known as “infrastructure as code.”
The fabric must be programmable, scalable, fast, open, feature-rich, automation-friendly, and secure. It must offer multiple high-bandwidth pathways between CPUs, GPUs, and storage and the ability to prioritize traffic classes. With Cumulus Linux and SONiC running on Spectrum switches, and BlueField-based DPUs, Nvidia offers a best-in-class end-to-end fabric solution that allows optimized programming across the entire datacenter stack. These solutions – plus, of course, the many Nvidia GPU-powered platforms and software frameworks – deliver outstanding levels of datacenter performance, agility, composability and programmability to customers, supporting the vision of Nvidia co-founder and chief executive officer Jensen Huang that the datacenter is the new unit of computing, which was discussed at length here at The Next Platform as Nvidia closed its acquisition of Mellanox Technologies and was getting ready to acquire Cumulus Networks.

Open Networking OS Supports ADI
Traditionally, switches have been designed as proprietary “black boxes” where the network operating system (NOS) is locked to a specific switch hardware platform, requiring customers to purchase and deploy them together.
Nvidia’s approach is to offer the best open end-to-end solution. Customers can take switches with the best switch ASIC — Spectrum — and choose the best NOS for their needs: Cumulus Linux, Mellanox Onyx, SONiC, or others. A customer could even choose to run SONiC on spine switches while using Cumulus Linux on top-of-rack and campus switches. At the same time, Nvidia sells extra-reliable cables and transceivers but does not lock customers in, allowing them to choose other cables and optics if desired.

Now, enterprise, AI, cloud, and HPC workloads can run flexibly across any part of the entire datacenter using the optimum resources including GPUs, CPUs, DPUs, memory, storage, and high-speed connections. With the demand for this kind of accelerated elastic computing, there’s no going back to the past where each server has its own dedicated, isolated resources and each application developer programs to one server at a time.
 Ami Badani is vice president of Ethernet switch marketing at Nvidia, and was previously chief marketing officer at Cumulus Networks.
Ami Badani is vice president of Ethernet switch marketing at Nvidia, and was previously chief marketing officer at Cumulus Networks.




Terrible article that is basically an ad for Nvidia. Mellanox and Cumulus are not part of open networking any more. You keep talking about vendor lock in and disaggregation, cumulus are aggregated and locked in with a vendor now! Nvidia have caused more harm to the open networking ecosystem than anything before it.
If you look closely, there is non-ADA-compliant fine print contained in the image associated with the article indicating content sponsored by Nvdia. Please include this notice in an accessible text format as well (like it used to be), not just in the image.