

The hyperscalers and cloud builders have been setting the pace for innovation in the server arena for the past decade or so, particularly and publicly since Facebook set up the Open Compute Project in April 2011 and ramping up as Microsoft joined up in early 2014 and basically created a whole new server innovation stream that was unique from – and largely incompatible with – the designs put out by Facebook.
Microsoft is not talking much about its hardware designs at the most recent virtual Open Compute Summit this week, but Facebook is. Vijay Rao, director of technology and strategy at Facebook, unveiled the “Zion” machine learning training system at the OCP Summit last year, with the innovative OCP Accelerator Module architecture that we think will take off in the industry because of the density and modularity it offers and the plethora of interconnects and accelerators that can make use of this architecture. Rao hinted at how smaller M.2 inference engines might be ganged up and deployed in Facebook’s “Yosemite” microserver designs, which made their debut in March 2015 and which was also the month we started The Next Platform. The Yosemite chassis is a one-third width compute sled which fits into the 21-inch Open Rack enclosures championed by Facebook and initially had up to four single-socket microservers plus shared networking and storage across those nodes, and up to 24 of these sleds plus two power shelves and some airspace filled up a single Open rack for a total of 96 servers.
At our The Next AI Platform event last year, Rao talked a little bit more about how Facebook might go massively parallel with relatively modest inference engines and deploy them inside machines like Yosemite, and this year at the virtual OCP Summit, Facebook’s engineers have outlined precisely how they are going to do this as well as talking about future one-socket and two-socket servers based on Intel’s “Cooper Lake” Xeon SP processors, which will also be doing some inference work thanks to their support of half precision FP16 and Bfloat16 data formats and processing in the AVX-512 vector units on those processors.
The Yosemite chassis is a big part of Facebook’s infrastructure, along with various generations of two-socket machines. We profiled how Facebook configures its servers for different workloads back in 2016, and the “Leopard” two-socket systems plus Yosemite represented the vast majority of its infrastructure, with the “Big Sur” GPU-enabled machines being relatively low volume but growing fast in importance. But Facebook has created more than two machines and contributed them to open source, as this overview from Katharine Schmidtke, director of sourcing for ASICs and custom silicon at the social network, outlined in her keynote address:
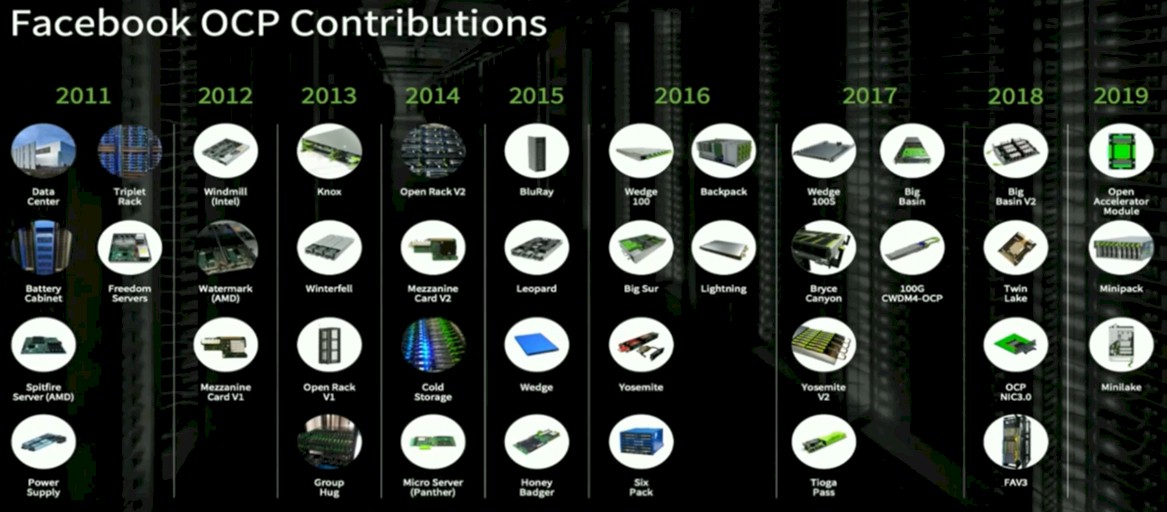
Facebook has kicked in designs for datacenters, racks, servers, storage servers, various kinds of mezzanine and network interface cards and accelerator modules for servers, modular and chassis switches, and optical transceivers, not to mention a bunch of software. You could build a pretty decent datacenter even from the old Prineville designs opened up in 2011 and fill it with lower cost, vanity free gear had you the mind to do so.
Last year, Facebook talked vaguely about the modifications it might make to the Yosemite chassis and how it might create massively parallel inference complexes using relatively modest inference engines from a number of suppliers using a “Glacier Point” carrier card for the inference sticks that fits into the Yosemite enclosure. This year, they provided details on the updated Yosemite V2.5 chassis and the Glacier Point V2 carrier card that is actually in production. Facebook has a bunch of reasons why it wants to use baby inference chips on M.2 form factor PCI-Express cards. For one thing, the company doesn’t want inference, which is a vital part of its application stack, to have a huge blast area if something goes wrong. Moreover, inference is a pretty light and naturally massively parallel workload (like Web serving) and that lends itself naturally to running on small devices. The price/performance and thermals on these devices are also very attractive to running inference on GPUs or FPGAs – by Facebook’s math, anyway. But these devices are not really good at training, and go in the exact opposite direction that Nvidia is doing by converging HPC, AI training, and AI inference all onto the new “Ampere” GA100 GPU engine announced this week. But Facebook has other workloads it needs to support, such as video encoding and decoding, which can run on M.2 sticks as well and be deployed in carrier cards and housed in the Yosemite servers. Moreover, its homegrown GLOW compiler, which we have talked about here, allows for inference models to be split across multiple, relatively small devices, so it doesn’t have to choose heavier compute to do inference just because it has heavier inference.
To update the Yosemite chassis to take on the heavier workloads of parallel inference, some changes needed to be made, as outlined here:
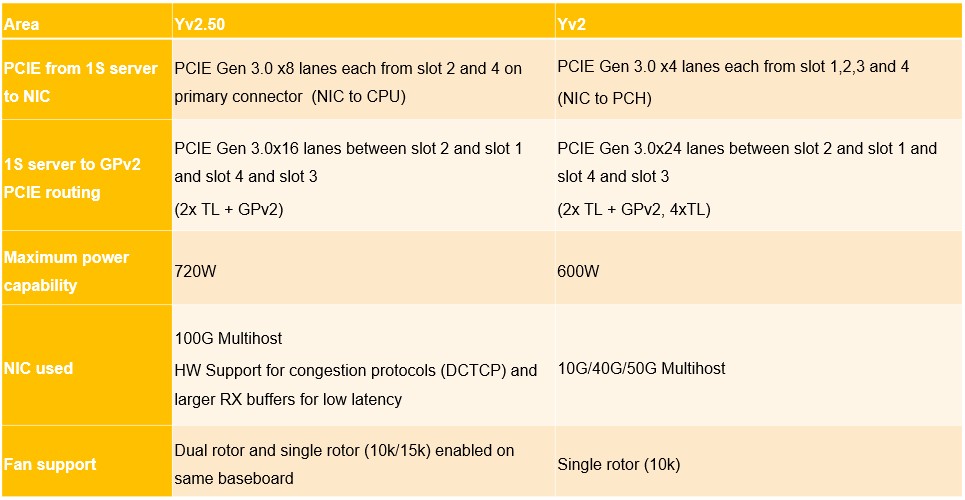
The big changes is that the PCI-Express 3.0 switching between the modules in the Yosemite chassis were rebalanced, with more bandwidth going from the CPU to the network interface card and fewer lanes linking the modules together. The maximum power for the enclosure was boosted by 20 percent to 720 watts, and higher speed 15K RPM fans were allowed to move this heat off the compute. A 100 Gb/sec multihost NIC was added and it was given a NIC that had large receiver buffers to get low latency as well as hardware support for congestion control. (We are pretty sure this is a ConnectX card from Mellanox, now Nvidia, but Facebook doesn’t say.)
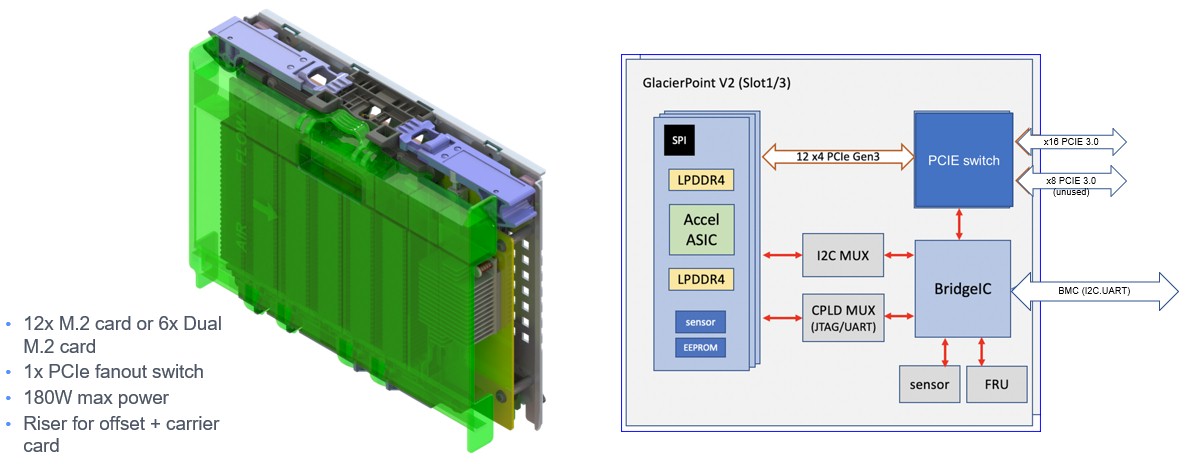
Here’s what the Glacier Point V2 carrier card, which has been tweaked, looks like:
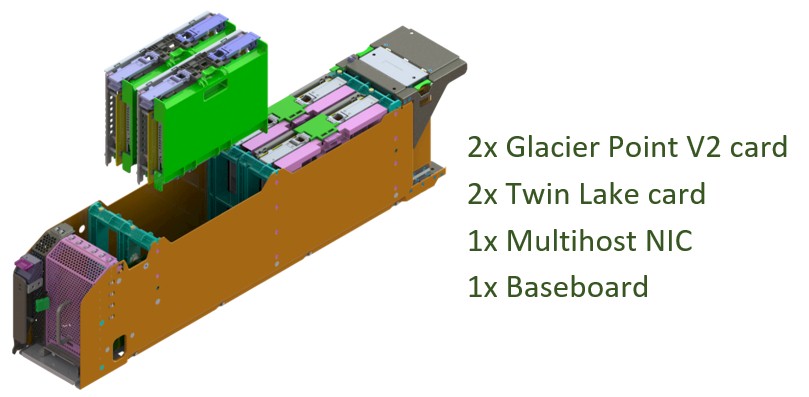
And here is what the whole assembly looks like:
And here is what the finished iron looks like:

Each Glacier Point carrier card maxes out at 180 watts and can have a dozen M.2 cards or a half dozen double-wide M.2 cards. Here are the specs on the two M.2 inference cards Facebook has put out to the industry so they can make them:
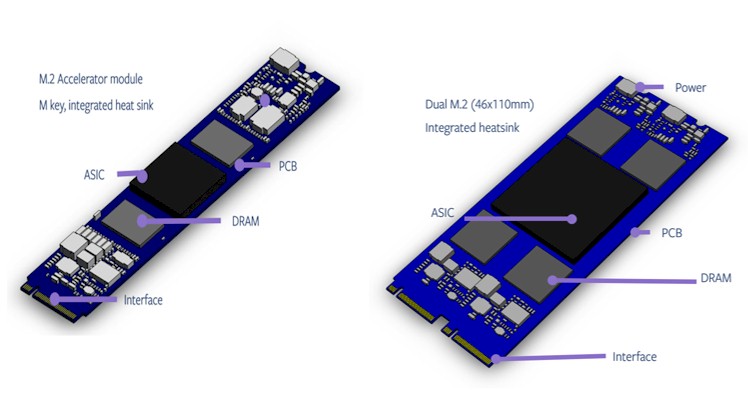
The M.2 modules have to support PCI-Express 3.0 and 4.0 (one x4 slot) and they have to fall in the range of 10 watts to 14 watts, all in. These are useful because they can plug into existing servers that have M.2 slots, if need be. It also allows for multiple modules to be used within Facebook for different kinds of acceleration and Facebook can also mix and match local acceleration of many types with local Optane or flash M.2 modules if it chooses. The double-wide M.2 is designed to hold fatter and hotter ASICs, in the range of 15 watts to 25 watts, and the larger board area also allows for larger local memory on the package. The same need for PCI-Express 3.0 and PCI-Express 4.0 (a pair of x4 lanes, either way) is a requirement.
The inference team at Facebook suggests that with the Yosemite V3 chassis, which we will talk about in a minute, it will want a standalone NIC for each sled in the enclosure because the PCI-Express switching between the carrier cards and the CPU host – especially at PCI-Express 3.0 speeds – can be a bottleneck when trying to create low latency inference using modest components. The wish list also includes a separate baseboard management controller for each server in the Yosemite chassis and the use of PCI-Express 4.0 switches to link carrier cards to the hosts.
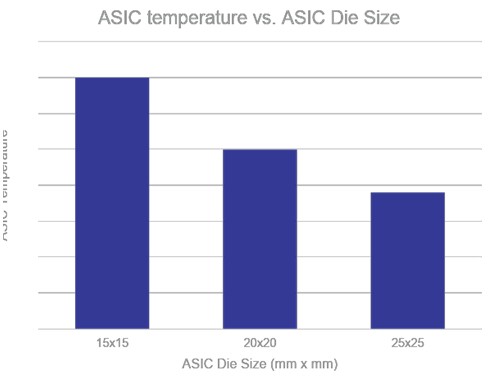
Which brings us to the Yosemite V3 design. Now, Facebook is going to be rotating the electronics in the enclosure by 90 degrees, making things that were vertically oriented horizontal. What Facebook has learned from the M.2 experiment with Yosemite V2.5 is that the vertical orientation with the CPU in the middle and carriers front and back is not ideal for cooling thermally more dense accelerator carriers. But turning everything on its side, the thermal distribution becomes more uniform across the same number of devices, and frankly it is easier to cool relatively modest CPUs and the accelerator motherboards become the systems heat baffles. Facebook’s inference team is looking down the road, and they want to be able to have flexibility in the size and shape and number of storage devices and accelerators in the Yosemite chassis as well as being able to support faster (and presumably hotter) PCI-Express 5.0 interconnects and power and cool devices that run up to 30 watts. The thinking among at least some at Facebook is that single and dual M.2 form factors are not going to work, and that is, we think, mostly due to the fact that PCI-Express 5.0 devices are not going to come to market fast enough in those form factors. Moreover, the future needs larger die sizes because they are more thermally efficient. Here is a chart that shows a 20 watt bare die on a simulated dual M.2 card, showing the interplay of temperature and die size:
So, with Yosemite V3, there is a new Delta Lake single-socket server, and now you can cram four uniprocessors into the unit, but now they are front loaded instead of top loaded, which is a real hassle when you have to do it hundreds of thousands of times.
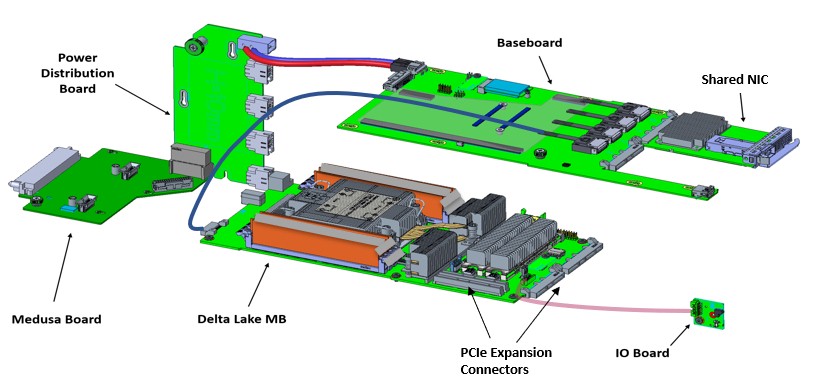
Here is what the base components inside the Yosemite V3 chassis look like:
And here is what it looks like loaded up with four Delta Lake compute cards:
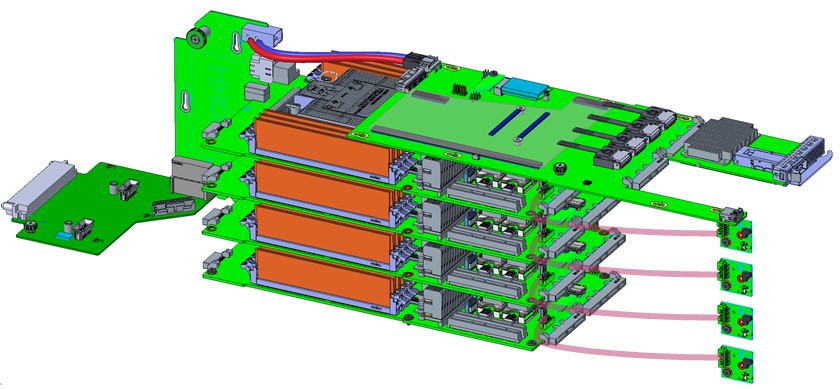
Here is the same box with four servers nodes and flash storage per node:
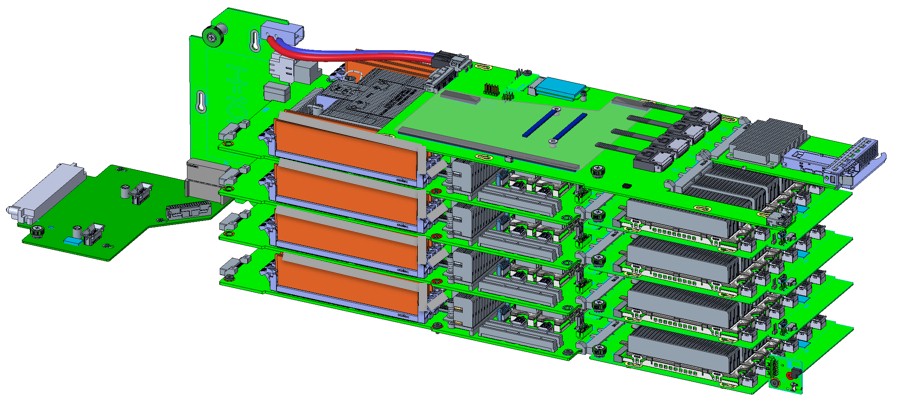
Here is a setup of Yosemite V3 with two beefier servers each with two accelerators:
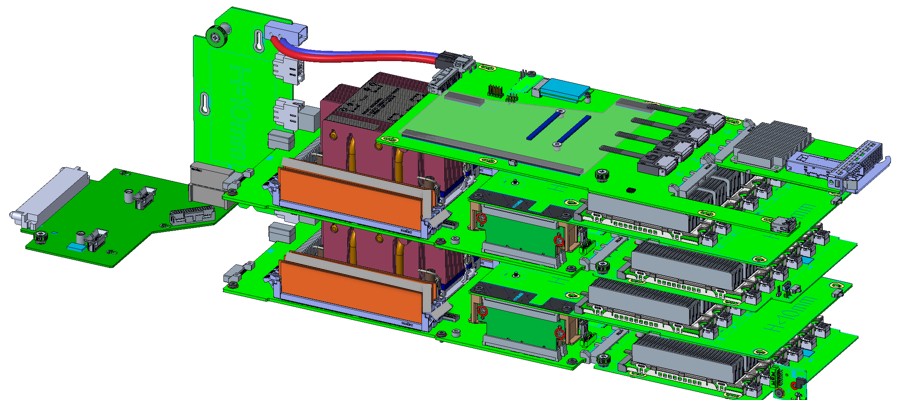
And here are two beefy server nodes with two heftier accelerators and a switch linking them plus a dedicated network interface per node:
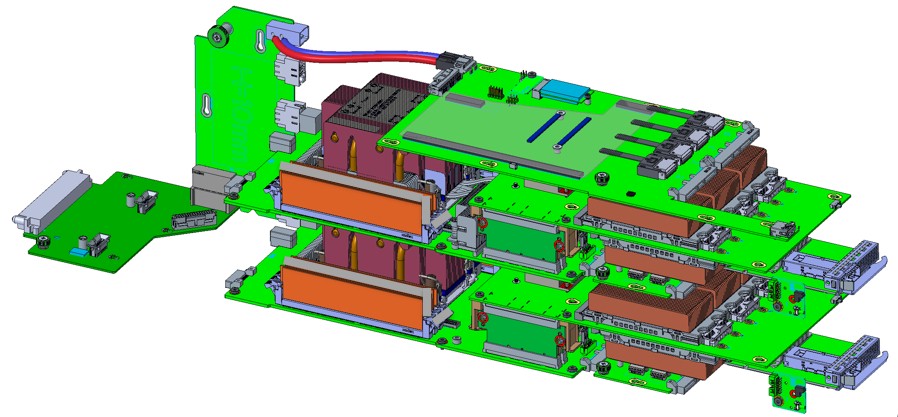
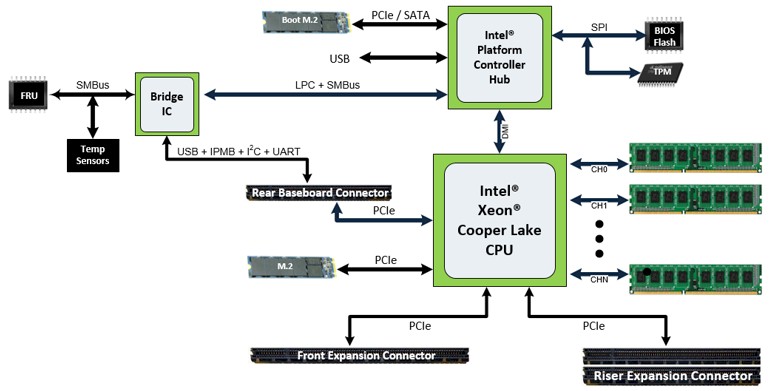
The Delta Lake server node is based on the future Cooper Lake processor that is coming out from Intel later this year. Facebook can’t say much about the capabilities of that third generation Xeon SP processor, but it will apparently have support for future “Barlow Pass” Optane persistent memory sticks and have more PCI-Express lanes and a pair of local M.2 connectors. Here’s the Delta Lake server mode:

And here is the Delta Lake server schematic, which has had the number of memory channels obscured. (Perhaps there is more than six? One can hope. . . . )
And this is four possible configurations of sleds based on Delta Lake:

OK, that brings us, finally, to rack-mounted servers, and we spotted two at the virtual Open Compute Summit that were based on the Cooper Lake Xeon SPs.
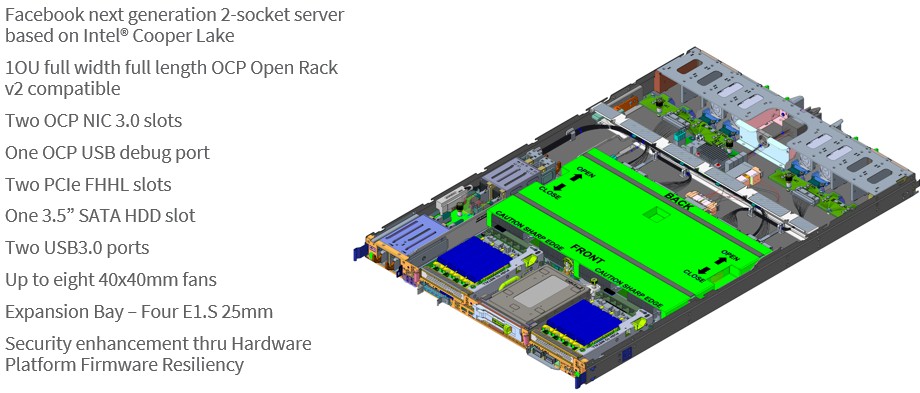
The one from Facebook is called “Sonora Pass,” and it is a two-socket machine, thus:
The schematics were blanked out in the official presentation, but we took a blurry screen shot during the session that has the data:
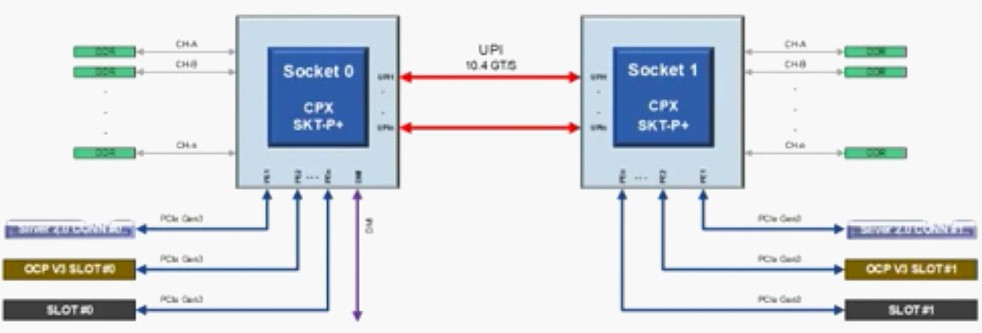
Aside from the mystery around memory controllers, we can see that it is still PCI-Express 3.0 and not a lot of lanes are being used by this design. One interesting thing is that a lot of the peripheral components have been moved to the from inside the box to the front panel and the top of the rack chassis has a split cover so when it rolls out, you can pop the cover off and replace the units in the front – storage, NICs, and such. The design also sports four E1.S storage modules on the right hand side and comes with four fans expandable to eight for extra cooling.
The other Cooper Lake machine we spied was the “Catalina” system from Hyve Solutions, which is an eight-socket system than can be scaled back to four sockets, and which is not a Facebook design, but we are tossing it in here. This is the slide that popped up in an Intel presentation:

Once again, the memory modules were blocked out to create mystique.


MGX: Nvidia Standardizes Multi-Generation Server Designs
Updated With More MGX Specs: Whenever a compute engine maker also does motherboards as well as system designs, those companies that make motherboards (there are dozens who do) and create system designs (the original design manufacturers and the original – get a little bit nervous as well as a bit …

A Complete Rethinking Of Server Virtualization Hypervisors
Server virtualization has been around a long time, has come to different classes of machines and architectures over the decades to drive efficiency increases, and has seemingly reached a level of maturity that means we don’t have to give it a lot of thought. But some researchers at the Institute …

Groq Says It Can Deploy 1 Million AI Inference Chips In Two Years
If you are looking for an alternative to Nvidia GPUs for AI inference – and who isn’t these days with generative AI being the hottest thing since a volcanic eruption – then you might want to give Groq a call. It is ramping up production on its Language Processing Units, …
Be the first to comment