

Sometimes a microserver is just a little too micro to do the job, something that a lot of skeptics have been saying about so-called “wimpy core” machines since the idea took off about five years ago. In launching a new microserver based on Intel’s Xeon D processor, Open Compute founder Facebook showed that it was willing to admit publicly when an idea did not work out as expected, go back to the drawing board, and share its experiences and improved designs to help others move forward with their adoption of diminutive disaggregated systems.
Facebook likes to “fail fast” and “break things” when it comes to software development, but this takes a bit more time with hardware designs. Two years have passed between the debut of the “Group Hug” microserver chassis, Facebook’s first run at the idea, and the new “Yosemite” enclosure and “Mono Lake” microserver, which Facebook created in conjunction with Intel and original design manufacturer Quanta. Facebook has not given up on the microserver idea even though it has been quiet about its efforts, and in his Open Compute Summit keynote, Jay Parikh, vice president of infrastructure engineering at Facebook, explained Facebook’s experimentation with and continuing enthusiasm for microservers.
“We took a look at our heavy compute workloads and we said that this traditional two-socket architecture that we are so used to in the industry was not quite optimal for us. There was wasted resources, there was difficulties around getting the efficiencies, around the performance and the utilization that we wanted to get from the device itself with our software. There were challenges around balancing and managing NUMA and other kinds of difficulties that we have from a software perspective, and we broke this down and said we can actually do something better here.”
The idea with the Yosemite/Mono Lake combination is simple: Use an SoC with enough oomph to run a selection of Facebook workloads, and pull the networking, power, cooling, and baseboard management control into the enclosure, leaving just compute, memory, and local flash storage on the tiny server node. This is not a new idea – the Group Hug setup did the same thing. The difference here is that Intel has gone through two chip manufacturing process shrinks – from 32 nanometers to 22 nanometers to 14 nanometers – on its single-socket Xeons. Intel has also implemented SoC packaging for the new Xeon D, putting the processor and its chipset into the same package, simplifying the elements needed to make a small server.
Type 1 Personality
Jason Taylor, vice president of infrastructure at Facebook, said in the same keynote that Facebook has a few different server designs that it deploys in its facilities, and each type of machine is aimed at a specific set of workloads. The Mono Lake microserver was initially created as what Facebook calls a Type 1 workload, which means it is made specifically to host the web serving front end of the Facebook platform.
“When we do hardware design, we put blinders on and really only focus on one workload, and for the web tier, it is always the most performance per watt, how do you get the maximum amount of compute online with as few residuals as possible. And what is so nice about the SoC design is that so many of the components that normally go into motherboards are in the package. That efficiency has really enabled us to go from a 2P system to a 1P system, and from an operating system perspective, you are dealing with one processor, one cache and you are not having to futz around with NUMA. We think that it will be a nice step back to simplicity.”
The complexity with NUMA on two-socket servers is not to be underestimated. To get the maximum amount of performance out of these increasingly complex systems means having to pin data in specific parts of the memory subsystem. This has to be done within the application itself – a very tedious and low-level sort of programming.
Facebook has created its own virtual machine for running its PHP web front end, which is called the Hip Hop Virtual Machine and which is open source, so it knows very well how to get down in the weeds of this code to tune it for NUMA. But this job gets more complex as Intel adds more and more cores and caches and rings to connect them to its Xeon E5 processors. The chips are getting so complex that Intel is beginning to partition the caches and cores on a single processor socket to help automatically squeeze more performance out of two-socket systems. (This NUMA partitioning is a feature of the “Haswell” Xeon E5 processors launched last September.) Of course, on a massively distributed web application like Facebook’s front end, it would be best to not have to do such NUMA tuning at all. Facebook can scale out web performance by increasing the number of nodes running its HHVM and PHP front end – provided those nodes are running the code sufficiently fast.

This was the idea behind Group Hug from the get-go. The Group Hug chassis, which was 2U tall, crammed 36 microservers based on SoC processors into a single enclosure, with each microserver having all of the components excepting main memory integrated on the processors. There were Group Hug microserver cards based on Intel “Centeron” Atom S1200 and “Avoton” Atom C2000 processors, low-powered AMD Opteron processors, and even ARM processors from AMD, Applied Micro, and now-defunct supplier Calxeda. Most of these SoC chips, said Facebook, consumed 30 watts or less, and it could get a maximum of 540 chips in a single Open Rack.
If you added up all of the threads in the Group Hug machine and multiplied by the clock speeds, you would reckon that three dozen of these microservers could replace a decent number of the Type 1 systems that were running the Facebook web front end. But the problem, Matt Corddry, director of hardware engineer and supply chain at Facebook, explained to The Next Platform, is that the Group Hug microservers that Facebook tested running its PHP front end did not have enough single-threaded performance, and the latencies on its web page composition were just too high. “It just wasn’t rendering a page fast enough,” Corddry said, without getting into too much more detail about the difference in performance between the existing Type 1 machines, the Group Hug microservers, and the new Yosemite/Mono Lake machines.
(One aside about the Group Hug project. While the Group Hug system did not take off inside of Facebook for its intended use as a Type 1 system aimed at web serving, the microserver cards have made their way into various Facebook and Open Compute systems as adjunct processors. For instance, the “Panther” variant of the Group Hug card based on the Avoton Atom is used as a storage controller in the “Honey Badger” storage sled designed by Facebook that fits into the Open Compute racks. This same Panther microserver is the controller brain inside of Facebook’s “Wedge” top of rack switch and “6 pack” spine switch, running its FBOSS switch operating system.)
D Is For Density
There is some chatter out there that the new Xeon D chip was designed by Intel specifically at the behest of Facebook to suit its very specific web serving needs, but Yan Zhao, the hardware engineer at Facebook who was responsible for the Yosemite project, tells The Next Platform that this is not the case. Zhao says that it is more accurate to say that the chip was developed by Intel with input by Facebook – and presumably with input from a bunch of other hyperscale customers who like the microserver concept but have found the performance of the existing SoC chips was not up to snuff for their workloads.
To its credit, Intel has done a lot of work making the Atom processors suitable for servers, but the Xeon D is a much better chip for the kinds of workloads that Facebook and its hyperscale peers are trying to run. For one thing, these are true Xeon cores, and better still, they are the latest “Broadwell” cores that are not even yet available in the Xeon E5 line and will not be until later this year. The Broadwell cores have Xeon-class performance, and importantly, reasonably beefy L3 cache memory – something that is missing from the Atom server chips. They fit in a 45 watt thermal envelope, which is not as low power as the SoCs that Facebook was playing around with during the Group Hug experiment, but it is low enough that four of these processors plus some memory and M.2 flash storage can all be jammed into a single Open Compute sled.
Truth be told, the biggest difference between Group Hug microservers and the Yosemite microservers is the benefit of process shrink at Intel over the past several years. A single socket Xeon can do the web serving job provided it can be implemented in a 14 nanometer process that gives it a relatively low thermal profile (45 watts) while also yielding decent application performance even with a modest 2 GHz clock speed. This, more than any other factor, is why it took 18 months to bring the Yosemite microserver design to market. To be fair, it also took some time for Facebook, Intel, and Mellanox Technologies to come up with the multiport, OCP-compliant network interface card that provides 50 Gb/sec of uplink capacity for the aggregated network ports coming out of the four microserver nodes in the Yosemite enclosure. The Xeon D chip has enough processing oomph and network bandwidth, with ports running at 10 Gb/sec, to match it. The Avoton was bandwidth constrained with only a pair of 1 Gb/sec links coming off the Panther microservers.
Given all of this, Facebook expects to be able to use Yosemite nodes in production, not as a science experiment. “This gives us a huge amount of flexibility because we are going to apply this to other workloads as well,” Parikh explained. “This is going to help us with one of our workloads to get started, but the basic building block of Yosemite is going to be applied to other workloads that we have.”
Facebook has a massive Memcached web caching farm – said to be the largest in the world – and that might be the next place Yosemite gets deployed if this caching software and a 128 GB memory footprint per node is a good fit.
A Look Inside the Yosemite/Mono Lake Microserver
One way to think about the Yosemite system is that it is a slice of the Group Hug tipped on its side with a radically better SoC for compute that also includes local storage on the nodes and much faster and aggregated networking coming off the sled. The Yosemite sleds fit into the three-wide “Cubby” enclosure that is part of the Open Rack V2.
According Zhao, who hosted an engineering workshop at the Open Compute Summit to go over details of the new microserver, the design goals for Yosemite microserver node were to build a processor-agnostic motherboard that could accommodate X86, ARM, and Power processors and that would allow for different configurations of memory slots as well. Facebook also wanted to have local storage on the node, with an SSD being an option but with the much smaller M.2 flash sticks being preferred.
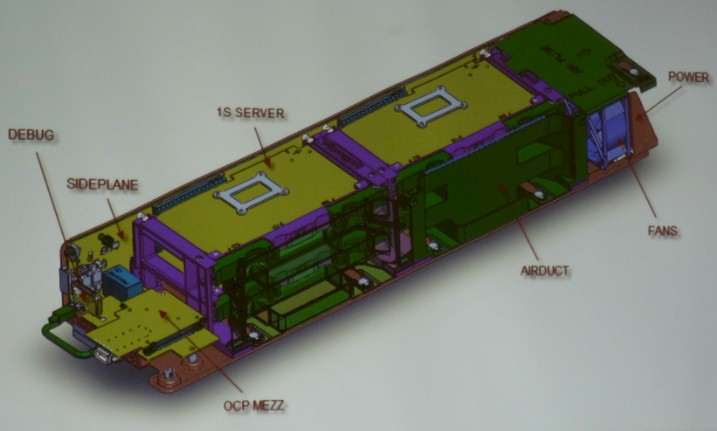
The Yosemite unit is designed so that four microservers in the sled can have a thermal design point of up to 65 watts each, which is enabled mostly because Yosemite is a much less dense design, in terms of socket count, than Group Hug was. Total power draw for each microserver card is capped at about 90 watts, and the Yosemite sled has a maximum power draw of about 400 watts. The Yosemite design allows for 192 SoCs to be put into an Open Rack, which works out to 1,536 cores and a maximum of 24 TB of memory across the nodes.
The Mono Lake microserver is the first Yosemite-compatible device, and its motherboard measures 210 millimeters by 110 millimeters and has room for one Xeon D processor and four memory slots, for a maximum of 128 GB using 32 GB DDR 4 memory sticks. There is a second motherboard profile that measures 210 millimeters by 160 millimeters that will allow for larger processors or more memory slots and still fit inside the Yosemite enclosure. Facebook chose an M.2 flash memory stick for local operating system storage, and there are a wide variety of capacities available for these. It won’t be long before Intel delivers its 3D NAND flash and it will be able to put terabytes of capacity on one of these SSD gum sticks.
The Yosemite microservers will use the same PCI-Express x16 mechanical slots to provide power and connectivity that were used in the Group Hug microservers, with some slight modifications. The other change is that the Yosemite design has a primary x16 connector and an extension x16 connector instead of the single one used with Group Hug. Many microservers will eventually make use of both the primary and extension x16 slots as the bandwidth increases on the SoCs. The primary x16 connect provides electrical links out from one 10 Gb/sec Ethernet interface on the SOC as well as links to three PCI-Express 3.0 x4 slots and one SATA 3.0 port, which could in theory be embedded in a Yosemite enclosure for more connectivity. The extension x16 connection adds three more PCI-Express 3.0 x4 slots and a 40 Gb/sec Ethernet link.

If you look carefully at the Yosemite sideplane, you will see that only one of the x16 connection slots is being used, and that is because Intel does not have an SoC that can drive higher speed networking. (No other company does, either. Although you could use the second connector to try to drive both 10 Gb/sec ports that are physically on the Xeon D chip.) At some point, SoCs will have ports running at 25 Gb/sec or 40 Gb/sec and the upstream top of rack switches will be running at 100 Gb/sec and this extension x16 connector will be put to use. The Hybrid OCP Mezzanine 2.0 card that plugs into the front of the Yosemite sled aggregates a PCI-Express x2 port and a 10 Gb/sec Ethernet port coming off the Xeon D chips and through the sideplane. The mezzanine card aggregates the networking for all four Mono Lake nodes and runs them through a single QSFP port up to the top of rack switch.
To accommodate multiple processor architectures, Facebook has used a Tiva microcontroller from Texas Instruments as a bridge chip between the SoCs and an AST1250 baseboard management controller. This bridge chip and BMC reside on the sideplane, and both are abstracted from the individual four nodes in the Yosemite sled. The server cards talk through the BMC to USB hubs, hot swap controllers, temperature sensors, fan controllers, and the OCP debug card. The Yosemite sled also has a knob to dial up a particular node for the reboot button if a hard boot is necessary. (That should probably be automated somehow.)
The Yosemite system was designed with a group effort. Intel created with Xeon D processor and worked with Quanta to design the Mono Lake board and to get the microserver manufactured. Facebook and Quanta designed the sideplane and the hybrid mezzanine card along with Mellanox. In the demo system at Intel’s booth in the Open Compute Summit expo, Quanta had manufactured all of the boards in the system. Presumably Quanta also bent the metal for the Yosemite sled and formed the plastic for the insert snaps and air flow baffles for each Mono Lake microserver.
Intel intends to donate the specs for the Mono Lake board to the OCP and Facebook will do the same for the Yosemite sled, so if this system architecture has appeal – and there is reason to believe it will – others will be making variants of the microserver and the sled in short order, particularly ARM server chip makers hoping to hop on the Open Compute gravy train.
There is no word as yet on what kind of price/performance and performance/watt advantage the Mono Lake cards have compared to a two-socket Xeon server running Facebook’s workloads, but we will try to find out.


Open Compute Really Is Open For Business
Open source hardware is something that is intellectually satisfying as well as economically rewarding, but it is clearly not something for everyone. At least not yet. But the Open Compute Project ecosystem that social network and hyperscale application provider Facebook started back in April 2011 has always taken the very …
AMD Gets Inside Facebook’s Latest – And Most Powerful – Microserver
Sometimes, you do put new wine in old bottles. This is what it looks like Meta – well, really its Facebook social network group – is doing as it adds a microserver node based on a custom AMD “Milan” Epyc 7003 processor to its datacenter infrastructure. Facebook has been one …

Getting Meta: Abstracting And Multisourcing The Network Like An FBOSS
If you want to build the world’s largest social network, with 2.9 billion users, and the massive PHP stack that makes it into an application, you need a lot of infrastructure and you need it to arrive predictably. Through its own supply chain management and the Open Compute Project ecosystem, …
The PUE metric, used by datacenter operators to tout their efficiency is the biggest farce hoisted upon the gullible public. It allows google, facebook and amazon to claim high efficiency while completely ignoring the biggest power burner of all, the compute efficiency. Micro-servers or wimpy core look good on paper, but are horribly energy inefficient. The latest decade of computer science graduates are too stupid or lazy to properly program the traditional ‘big iron’ or beefy core machines to do the job that they can do well, so instead of learning from a half century of experience and optimization decided to start over, and finally admitted they were wrong. Meanwhile, as much as I bristle at their monopolistic practices it seems that Intel has kept the faith and delivered the solution that the market needs with the Xeon Phi. It’s binary compatible with 90% of the installed base and will obliterate ARM core based microserver architecture and processor manufacturers. Take a lesson from Smoothstone/Calxeda, cut your losses and run. Intel is back.
this aged like milk
Well, then it must be good cheese!