

The hyperscalers and cloud builders of the world build things that often look and feel like supercomputers if you squint your eyes a little, but if you look closely, you can often see some pretty big differences. And one of them is that their machines are not engineered for maximum performance at all costs, but rather with an optimal balance between performance and cost.
That, in a nutshell, is why social networking giant Facebook, one of the largest AI users in the world, does not just put in a massive order for HGX-1 and HGX-2 systems from Nvidia – the hyperscale versions of the DGX family of systems from the GPU accelerator maker – for its machine learning training and call it a day.
This is also not coincidentally why Microsoft, Google, Amazon Web Services, Alibaba, Tencent, Baidu, and pick your fourth favorite Chinese hyperscaler (China Mobile or JD.com) similarly design their own servers or make use of designs that come out of the Open Compute Project founded by Facebook back in 2011 or the parallel the Scorpio Project effort started by Alibaba, Baidu, and Tencent six months after OCP was launched. And in some cases, they even design their own ASICs or run algorithms on FPGAs specifically for machine learning.
To be fair, Facebook did install a semi-custom implementation of the DGX-1 hybrid CPU-GPU system from Nvidia back in June 2017, which has 124 nodes and which has a peak double precision performance of 4.9 petaflops and is rated at 3.31 petaflops on the Linpack parallel Fortran benchmark commonly used in HPC centers. But this is the exception, not the rule.
But that said, Facebook likes to design its own hardware, open source it, and try to build an ecosystem around those designs to lower its cost of engineering and manufacturing – and lower its supply chain risk – as more companies come into the Open Compute fold. This is the same reason that Microsoft joined OCP a few years back and dumped an entirely distinct set of open source infrastructure designs, from servers to storage to switching, into the OCP ecosystem. This increased innovation but caused the supply chain to bifurcate a bit.
At the OCP Global Summit this week in San Jose, Facebook was on hand to show off the designs for future systems aimed at both machine learning training and infrastructure, giving the world a chance to see at least one potential future for cost-optimized gear aimed at these two increasingly important workloads in the modern datacenter. The designs are interesting, showing Facebook’s penchant for creating systems that can accommodate different kinds of compute from the widest possible number of vendors to, once again, lower costs and reduce supply chain risk.
Not So Basic Training
The first new machine is code-named “Zion,” and it is aimed at machine learning training workloads at Facebook. The Zion system consists of two different subsystems, just like the DGX-1 from Nvidia and the HGX-1 tweak from Microsoft and DGX-2 and HGX-2 equivalents from Nvidia and their many clones out there among the ODM and OEM players who forge iron for customers. The Zion system is the successor to the “Big Basin” ceepie-geepie system that Facebook announced two years ago at the OCP Summit alongside Microsoft’s HGX-1, both of which had designs that were contributed to the OCP. The Big Basin machine supported up to eight of Nvidia’s “Pascal” GP100 or “Volta” GV100 GPU accelerators and two Intel Xeon CPUs on the host. The neat bit is that the CPU compute and GPU compute are separated from each other, on distinct motherboard and in distinct enclosures, so they can be upgraded separately. They are linked by varying levels of PCI-Express switching infrastructure, depending on the make and model.
Big Basin represented a radical improvement over its “Big Sur” predecessor, which was a less dense design based on a single motherboard with two Xeon CPUs and up to eight PCI-Express Nvidia Tesla accelerators (the M40 or K80 were the popular ones). Big Sur was revealed in December 2015. Facebook talks about designs as development is largely done and it has yet to roll them out into production, and that means the Zion machines are not yet out there in its fleet, but will be shortly. (We talked about Facebook’s evolving AI workloads and the machines that run them back in January 2018.) The changes with the Zion machine show how Facebook’s thinking has evolved on hybrid CPU-GPU machines, and in ways many of us would not expect.
The Zion machines two subsystems are called “Emerald Pools” and “Angels Landing” and they refer to the GPU and CPU subsystems, respectively. While Facebook has said for many years that its server designs were aimed at allowing for the choice of processors or accelerator, in this case Facebook and Microsoft have collaborated to come up with a unique packaging and motherboard socketing methodology, called the OCP Open Accelerator Module, or OAM for short, that will allow for accelerators with different sockets and thermals ranging from 250 watts to 350 watts with air cooling and as high as 700 watts with a future liquid cooling option, but all consistently deployed, in terms of the hardware form factor, in these accelerated systems.
Fellow hyperscalers Google, Alibaba, and Tencent are joining Facebook and Microsoft in promoting the OAM packaging, and so are chip makers AMD, Intel, Xilinx, Habana, Qualcomm, and Graphcore. System makers IBM, Lenovo, Inspur, Quanta Computer, Penguin Computing, Huawei Technologies, WiWynn, Molex, and BittWare have all got behind the OAM effort as well. Others will no doubt follow with their chippery and systems – Hewlett Packard Enterprise and Dell are the obvious missing OEMs and Foxconn and Inventec are missing among the key ODMs.
With the OAM, the accelerator is plugged into a portable socket that fits its pins on one side and then a standard parallel set of pins, which looks conceptually like the SXM2 socket from Nvidia that is used for NVLink on the Pascal and Volta GPUs, come off the module and plug into matching pairs of ports on the motherboard. Here are the mechanicals that show this:
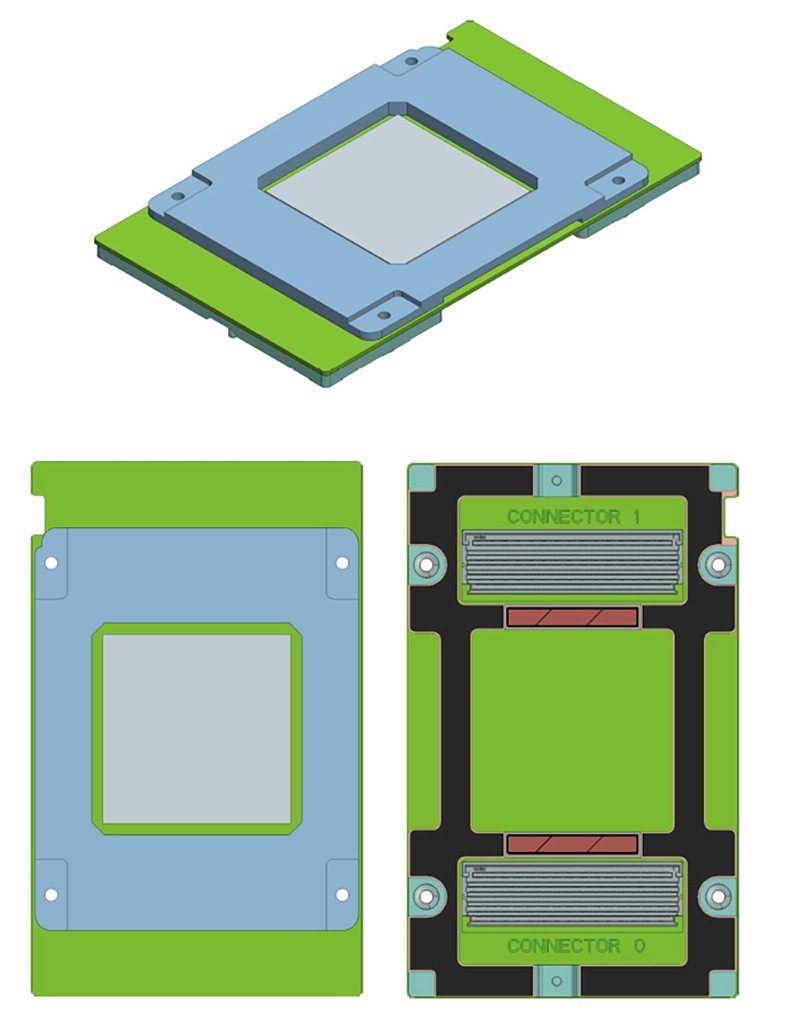
Any particular accelerator that will be plugged into the Emerald Pools enclosure will then have a heat sink, with varying number of fins and different materials suited to cooling the device underneath it but of a consistent height so airflow can be maintained across the enclosure in a consistent fashion no matter what kind of accelerator is plugged into the slots. And while Facebook does not say this, there is no reason at all that multiple and incompatible accelerators could not be plugged into the Emerald Pools enclosure and lashed to each other and to the host CPUs using the PCI-Express switched fabric implemented in that enclosure. Here is what that OAM looks like:

It looks suspiciously like a small car battery, doesn’t it?
Each OAM is 102 millimeters by 165 millimeters, which is big enough to hold what we presume will be ever-larger multichip modules in the future. The OAM can support 12 volt input for devices that consume up to 350 watts and 48 volt input for those that need to drive up to 700 watts; the thermals on air-cooled are expected to run out at around 450 watts. The current OAM spec allows for one or two PCI-Express 3.0 x16 slots between the accelerators and the host, and obviously faster PCI-Express 4.0 and 5.0 slots are on the roadmap. That leaves six or seven PCI-Express links for cross-coupling the accelerators. By the way, these links can be bifurcated to provide more interconnect links and to dial up or down the number of lanes for any given link.
Here is what the Emerald Pools enclosure with seven of the eight accelerators plugged in looks like:

There are four PCI-Express switches in the back of the Emerald Pools sled, which is to the right of these pictures, each of which plugs into a companion PCI-Express switch on the companion Angels Landing CPU enclosure that is the other half of the Zion system. The CPU portion of the system was not on display at the Facebook booth, but here is how Sam Naghshineh, technical program manager at Facebook and one of the engineers who designs its AI systems, presented the machine during a talk:

You can see the four PCI-Express 3.0 pipes coming off the accelerator sled and the CPU sled, linking them together. The interesting bit about Angels Landing is not that it has four server sleds in total, each with a pair of Xeon SP processors on it. This is a normal design for the hyperscale datacenter. The neat bit is that because of increasing demands for intensive processing of data during machine learning training on the CPU side of the system, it is lashing those four two-socket machines together using the UltraPath Interconnect (UPI) links on the processors to create an eight-socket, shared memory node. Technically, this is called a twisted hypercube topology, according to Naghshineh:
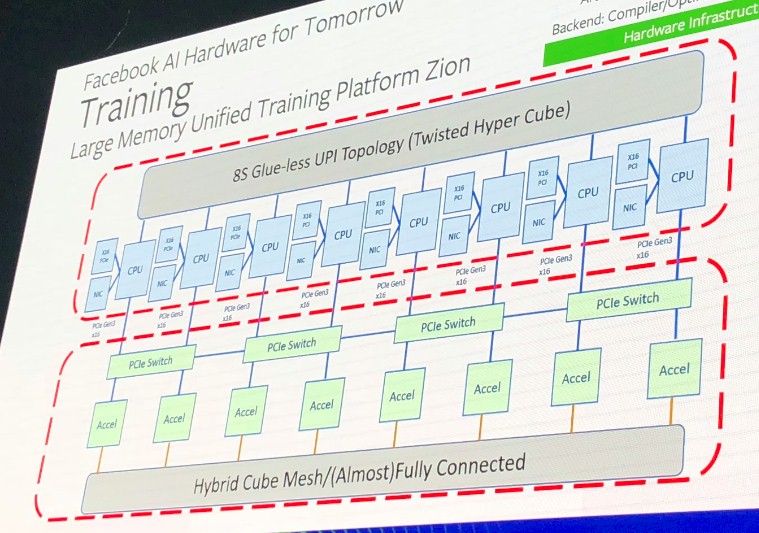
This fat CPU node is designed to have 2 TB of total DRAM main memory without having to resort to fat memory sticks or Optane 3D XPoint main memory, and importantly, to supply sufficient memory bandwidth on the CPU side of the system to not have to resort to HBM memory. (Not that Intel or AMD CPUs have HBM memory yet, but at some point, they will, particularly for HPC and AI workloads.) Those eight sockets are as much about DRAM memory bandwidth as they are about capacity.
As you can see, each CPU in the Angels Landing CPU enclosure has its own network interface card as well as a PCI-Express 3.0 x16 slot for linking that CPU out to the PCI-Express switch fabric that links the accelerator compute complex together and to the CPUs as well. Those accelerators are linked in a hybrid cube mesh that is almost fully connected in the diagram above, but there are other topologies that could be supported, like this:
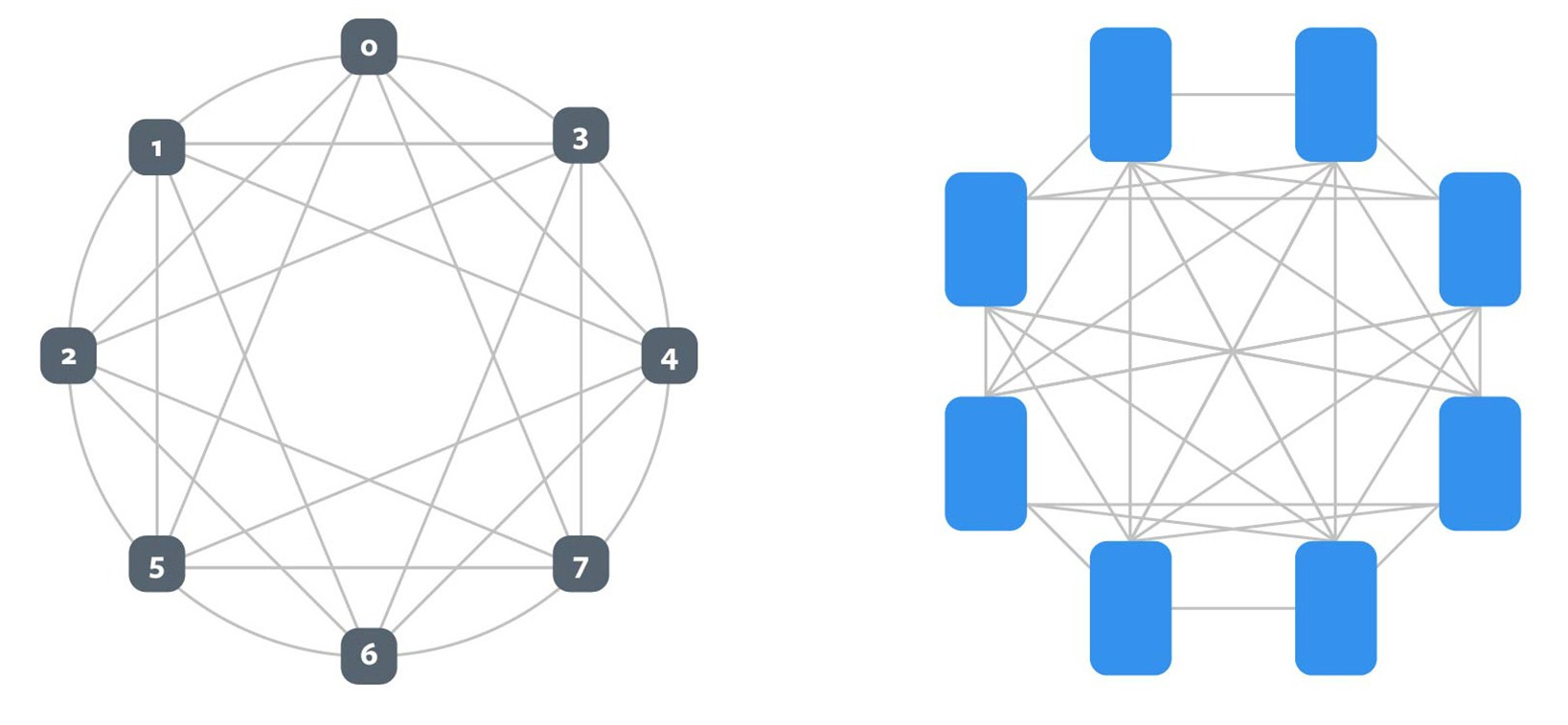
The diagram on the left has six ports coming off each accelerator and with eight accelerators linked in a hybrid cube mesh. On the right of the diagram above, there are eight devices again, but with one extra port per device (for a total of seven) the devices can be linked in an all-to-all interconnect arrangement. There are obviously other options, and the point is that different neural networks do better with different interconnect topologies, and this will allow Facebook and others to change up the topology on an interconnect to meet the needs of a neural network.
Inferring The Future Of Inference
Facebook has made no secret that it wants to have more efficient inference engines than it currently finds in the market, a topic that it discussed in a paper last year. This week at the OCP Global Summit, the company’s top brass outlined what the future might look like when it comes to machine learning inference hardware.
Vijay Rao, director of technology and strategy at Facebook, set the stage by reminding everyone about the 8087 math coprocessor, from way back in 1980, that Intel created for the 8086 family of processors that are the forbears of the Core chips in clients and Xeon chips in servers these days. These machines could do around 50 kiloflops (at 32-bit single precision) within a 2.4 watt thermal envelope, which is a pretty terrible 20.8 kiloflops per watt. The goal that Facebook has is to be able to do something closer to 5 teraflops per watt using low precision math such as INT8, and if you look at the big bad GPU from Nvidia, the GV100, it can do about 0.4 teraflops per watt.
“We have been working closely with a number of partners in designing ASICs for inference,” Rao explained in his keynote. “The throughput increase of running inference in an accelerator compared to a traditional CPU needs to be worthwhile. In our case, it should be roughly 10X on a per watt or a TCO basis.”
Rao talked generally about ganging up inference engines in M.2 form factors onto microserver cards and then plugging them into the “Yosemite” server enclosures, created way back in 2015, that Facebook designed to do basic infrastructure jobs. But later in the day, Naghshineh actually showed how this would be done. Here is what the “Kings Canyon” family of M.2 inference engines look like:

There are two different form factors, which Facebook is trying to encourage inference chip makers to support. One is a single wide M.2 unit that supports a maximum of 12 watts and has a single PCI-Express x4 interface coming off it, while the other has twice as much memory, a 20 watt thermal envelope and a pair of PCI-Express x4 ports which can either be used separately or bundled up. Multiple of these M.2 inference cards are plugged into the “Glacier Point” carrier card, which slots into a real PCI-Express x16 slot, and up to four of these carriers are crammed into a Yosemite enclosure, like this:
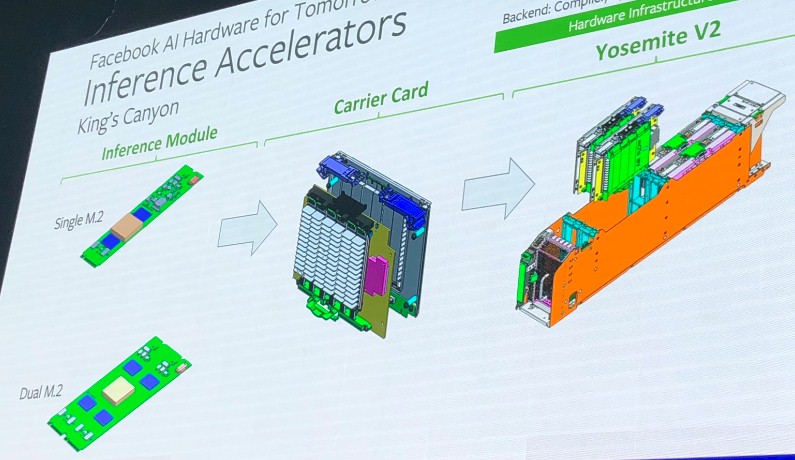
This is what the block diagram of the clustered inference engines looks like:

The only reason that this works is the same reason that it makes sense to use low-core count, high frequency, single-socket microservers to run electronic design automation (EDA) workloads, which Intel itself does despite the fact that it wants to sell two-socket servers to the world. Inference workloads are like Web serving and EDA verification: You can dispatch the whole job, which is small, to one of a zillion loosely coupled (barely coupled not really coupled at all) compute units, and do a zillion of those jobs at once and get a great deal of work done at the same time. Inferring on one bit of data is in no way dependent on what is being inferred on those other zillion jobs. Not so with machine learning training, which is much more like traditional HPC simulation and modeling in that, to varying degrees and frequencies, any bit of processing done on one compute element is dependent on the results from other compute elements.
Hence, the radically different hardware designs for machine learning training and inference we are seeing come out of Facebook. What we can see for sure is that Facebook wants to be able to adopt any kind of CPU and accelerator for training it thinks is right for the frameworks, and any cheap as chips inference engine that can do 10X better than a CPU at any given time. That inference business, which runs on X86 servers at Facebook today, is Intel’s to lose. Or not, if Facebook decides to deploy M.2 Nervana NNP inference engines in its fleet when they become available later this year. We will see which way the inference streams flow through Kings Canyon.


The Once And Future Federated Database
There are many different schools of thought when it comes to databases, which is one of the reasons that we launch our inaugural event focused solely on database technologies this year. But if you had to sum it up, it would look a bit like the following. After deploying a …
Meta’s Velox Means Database Performance Is Not Subject To Interpretation
A decade and a half ago, when Dennard scaling ran out of gas and many of us were starting to first think about what the end of Moore’s Law might look like should that day ever come, a bunch of us were kicking around what it might mean. People brought …
Xeon D Refresh: The Little Hyperscale Engine That Could
The datacenter server has been the center of gravity for compute for decades. But in recent years, as relatively heavy compute – meaning more than in your PC or smartphone – has been embedded into all kinds of storage and networking devices and increasingly pushes out to the hyperdistributed computing …
Be the first to comment