

Server virtualization has been around a long time, has come to different classes of machines and architectures over the decades to drive efficiency increases, and has seemingly reached a level of maturity that means we don’t have to give it a lot of thought. But some researchers at the Institute of Parallel and Distributed Systems at Shanghai Jiao Tong University have given it some thought, and they think that modern server virtualization hypervisors – the code that abstracts a system and allows it to run multiple virtual machines atop of that system – present too big of a security risk and don’t run as fast as they might.
And so they have created what they call the delegated user hypervisor, or DuVisor for short, that rectifies some of security and performance issues that affect VMware ESXi, Red Hat KVM, Citrix Systems Xen, and Microsoft Hyper-V as they multiplex physical resources to virtual machines that think they are running on one physical machine because the hypervisor is clever enough to make them think this.
Here is the problem. Back in the old days, with the System/370 mainframe’s Virtual Machine/370 hypervisor, the entire hypervisor for slicing, dicing, and multiplexing access to system CPU, memory, and I/O was all running inside of the VM/370 kernel itself. And funnily enough, customers could run many copies of VM/370 atop of VM/370, which was a proper operating system in itself as well as a hypervisor that could support IBM’s MVS and VSE operating systems. When IBM brought server virtualization to the AS/400 midrange systems in 1998 – a year and a half ahead of when any of the Unix variants and their RISC processors had any server virtualization – IBM took a similar approach, hosting whole OS/400 instances atop a master OS/400 that was converted into a hypervisor.
This approach had some inefficiencies, and so in 1999, IBM’s AIX and Hewlett Packard’s HP-UX were chopped down to the bare essentials to make proper, streamlined hypervisors, thus reducing the software load and, importantly, reducing the attack surface to make it more secure. (Performance and security both have an inverse relationship with software bloat.) Sun Microsystems did containers – somewhere between the VMs of its Unix peers and the Kubernetes containers we know today – with its Solaris operating system. VMware was founded and provided a similar host-based hypervisor for X86 PCs, and created an X86 server version of this host-based hypervisor, called GSX Server, in 2001, just when the dot-com boom was going bust. There was never a better time to drive up server efficiencies. By 2004, ESX Server, the free-standing hypervisor, was launched and included the core hypervisor (based on a stripped-down Linux kernel that eventually caused VMware some grief) and a Linux-based service console that was embedded in it. The rumor was that this original basis of what became the ESXi hypervisor weighed in at 6 million lines of code, with the vast majority of it being for the console, which was removed. We figure that the remaining ESXi still weighs in at many hundreds of thousands of lines of code (based on relative boot image sizes), and we also figure that Hyper-V is even fatter, although Microsoft has never given out the lines of code for this.
There is an interesting relationship between the security vulnerabilities in a server virtualization hypervisor and the number of CVE security bulletins associated with the, and we think that it is a reflection of coding practices as much as the lines of code implemented in the hypervisors.
Here is how the SJTU researchers characterized the situation:
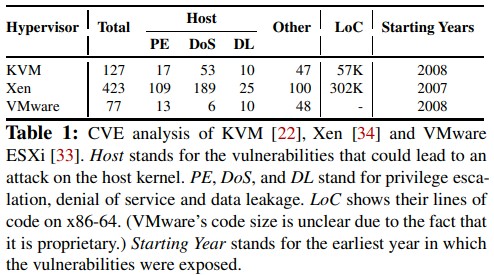
We didn’t believe for a second that VMware ESXi was inherently more secure than either KVM or Xen, which are both open source unlike ESXi, and Hyper-V was missing from this list, which bothered us. The table above is a very precise analysis, of course, but when we went to the CVE database, we found 448 security bulletins for ESX and 508 for ESXi (and there is some overlap in these, obviously), 490 for Xen, 181 for KVM, and 157 for Hyper-V. The Microsoft hypervisor used to require a copy of Windows Server 2008, which had 1,461 bulletins. If you put a gun to our heads, we would have guessed KVM is the most secure hypervisor because it has the smallest attack surface – it’s just a driver, really – but then if you look at the virtio storage drivers commonly used with KVM, that adds another 69 security bulletins. If you wanted to do equivalent stacks, it would take a lot of time to sort through all of the security bulletins over time and see how relevant they are.
Our point is, the attack surface and therefore the relative security of a server virtualization stack depends on that full stack. Some things are put into the hypervisor and some things are kicked out to adjunct code. The principle that the SJTU researchers are espousing – less code is better for security – is absolutely sound.
Where that code runs is just as important as how much code there is, and server virtualization has certainly evolved over time, generally along these lines:
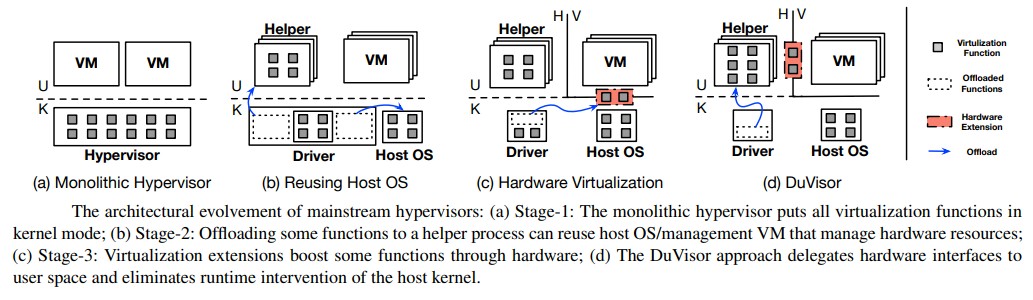
Over time, the idea is to move more and more of the server virtualization hypervisor’s function from the operating system kernel to the user space above the kernel, and while the chart does not show this, there has been an underlying change in CPU hardware to put some of the hypervisor functions and abstractions into the CPU itself to accelerate them. This has meant that server virtualization overhead has fallen from 50 percent of CPU capacity to 30 percent of capacity to a few percent of capacity over the past two decades on the X86 platform.
But don’t be mistaken, there are still huge performance penalties when it comes to server virtualization, and any vulnerability in the kernel code needed by the hypervisor means that it could be exploited to take control of the host kernel, access data in VMs, or be hijacked for a denial of service attack. There is a lot of hopping between different CPU protection levels, called rings, with hypervisors and operating systems arguing about who is in charge of the privileged access to CPU resources. Without getting into the weeds on these rings – you can do that by reading the paper – there are at least three levels of rings and every time you cross the rings, bouncing from kernel modes to user modes, you introduce latencies in the running of the guest operating systems.
To fix this problem, the DuVisor takes the existing hardware virtualization extensions invented over the past decade and a half for X86 architectures (and now used conceptually in Arm and some other CPU architectures like RISC-V) and moves the hardware-assisted portions of the hypervisor from kernel space to user space as well as employing an offload “helper” process to user-space that connects directly to the driver and does not have to go through the host operating system running on the bare metal (usually Linux or Windows Server these days).
The hardware extension created by the SJTU researchers is called Delegated Virtualization Extension, or DV-Ext for short, and here is how they explain it in their paper: “DV-Ext mostly reuses existing virtualization extensions with only minor modifications and securely exposes its hardware interface to user mode. With the new extension, the user-level hypervisor is able to handle runtime VM operations without trapping into the host kernel. Specifically, DuVisor directly utilizes DV-Ext’s registers and instructions in user mode to serve runtime VM exits caused by sensitive instructions, stage-2 page faults, and I/O operations.”
DuVisor is an extremely skinny bit of code, with the core hypervisor consisting of 6,732 lines of code written in Rust, 1,632 lines of code written in C, and 163 lines of code written in assembler. The DV-Ext extensions are 420 lines of code written in Chisel. The DuVisor was implemented atop a Rocket RISC-V core implemented atop FPGAs (we don’t know which one), which was equipped with the Linux v5.10.26 kernel that needed 362 lines of code added so it could know what the heck DuVisor is.
Here is what DuVisor looks like conceptually:
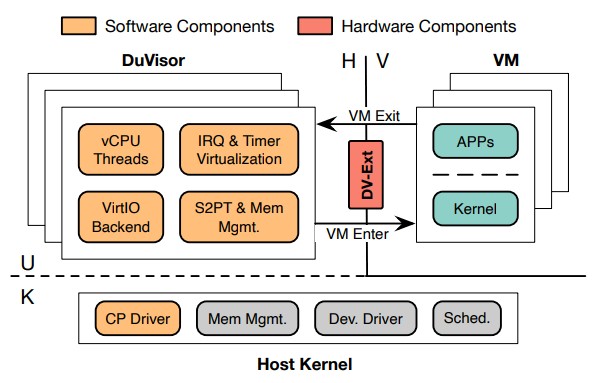
The CP in the diagram is the DuVisor control plane drive, which runs in kernel mode.
The important thing architecturally is that DuVisor is an untrusted piece of code running in user mode, and therefore is not trusted by the kernel of the host operating system, eliminating one avenue of attack on virtualized systems.
The “server” that the SJTU researchers used to run benchmark tests had two FPGA boards, each implementing an eight-core RISC-V processor with 16 GB of main memory and 115 GB of flash storage. The Rocket cores have 16 KB of L1 instruction cache, 16 KB of L1 data cache, and 512 KB of L2 cache shared across the cores. There are two IceNICs that run at 200 Gb/sec connecting the machines. The benchmarks pit DuVisor against KVM, the only hypervisor that has been ported to the RISC-V architecture so far – Xen is in the works and was booting on the new CPU architecture as 2021 came to a close.
Not only does the DV-Ext approach make KVM itself more secure with nominal overhead – somewhere way south of 1 percent, depending on the number of virtual CPUs in the virtual machine – but the DuVisor hypervisor has higher performance than the KVM hypervisor on a variety of benchmarks. Take a look:
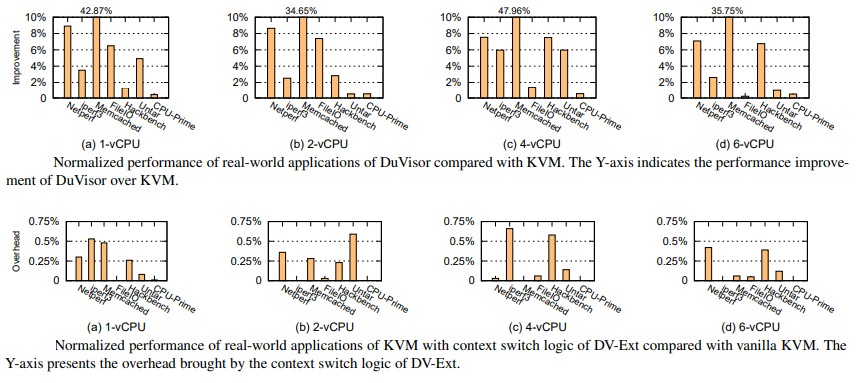
DuVisor has much lower overhead when it comes to VM exits caused by the memory management unit I/O stack, and this translates directly into better Memcached performance on DuVisor over KVM.
Very interesting work indeed, and surprising that it is coming out of China. Perhaps the Middle Kingdom will own a hypervisor of its own for all of the Chinese clouds to employ before this is all done. And perhaps the kind of delegated user hypervisor that the SJTU researchers have created will inspire the other hypervisor makers to take a new architectural approach.

The Ampere Arm Server Chip Roadmap May Lead Beyond Hyperscalers
Any tech startup that wants to live beyond is seed and venture funding rounds and make it to either an initial public offering or an acquisition by a company threatened by their very existence has to do two things. One, have a laser focus on precise markets and products that …

Talking Servers With Inspur And Intel
Any time a server maker comes into the global market and bypasses Cisco Systems, Lenovo, and IBM to become the third largest seller of machines in the world, you should pay attention. This is precisely what Inspur Information, the server unit of Chinese IT supplier Inspur Group, has accomplished, and …
Rest In Pieces: Servers And CXL
If you had to rank the level of hype around specific datacenter technologies, the top thing these days would be, without question, generative AI, probably followed by AI training and inference of all kinds and mixed precision computing in general. Co-packaged optics for both interconnects and I/O comes up a …
Coming from ElReg: Thanks for hinting to this topic and its paper. Have to read the paper thoroughly when having more time.
Just one thought:
“Very interesting work indeed, and surprising that it is coming out of China.”
->I think that this is not surprising.
China has “fresher” people, which grew up longer without Smartphone and IT influence in young years, so less distracted and better concentrated when learning – trained to work with their brains (lets say 100%) and then IT as supporting addition (another lets say 100% -> the sum is 200%).
In the US and Europe the younger generations grew up already more distracted than the generations that “invented IT”. Here the brain is used lets say 70% today, decreasing every year with more and more “outsourcing” to supporting IT products (lets assume still 100% -> the sum is 170%), more and more in addition already at school.
(“you don’t have to learn it, just google it – we need more tablets in the classroom – …” – well: not as fast as having learned it – while the chinese are already do combinations and developing new things with stuff they have in their head/brain, we are still googling for the basics, frankly said)
The problem is:
The longer this goes, the more the brain usage decreases -> the sum decreases -> the IT developed by these people will also “decrease” (get worser, more insecure, more complex – just too complex (code could no longer be reviewed and written as good as in the past) -> we are cutting the branch we are sitting on (which is IT more and more).
China will follow, but later.
IT destroys itself.
Very interesting reading! This is reminiscent of how TCP/IP and Java have been moved out of the Licensed Internal Code and into the “user land” realm of IBM i jobs on that platform.
Hey Kurt–funny seeing you over here in my other life. . . .